
 简介
简介
场辞是什么
场辞是新片场推出的AI视频字幕制作工具,利用先进的语音识别技术,能够迅速将视频中的语音内容转化为文字,准确率高达97.5%。具备一键加字幕、多轨制作、字幕快捷校对等功能,支持多种视频和字幕文件格式,提供实时预览和创新的字幕编辑工具,帮助用户轻松完成字幕制作。场辞还支持导出SRT、ASS、XML等格式,无缝对接第三方视频制作工具,是视频制作人员的理想选择。

场辞的主要功能
语音转字幕:利用深度学习技术,自动识别视频中的语音并转换成文字。一键加字幕:简化操作流程,用户只需一键即可为视频添加字幕。视频加字幕:支持导入已有视频或音频文件,并自动生成字幕。可视化时间轴编辑:用户可以直观地在时间轴上编辑字幕,提高编辑效率。多语言和方言识别:具备强大的多语言模型,支持超过99种语言和方言。如何使用场辞
下载和安装:首先从场辞的官方网站(trans.xinpianchang.com)下载软件,并按照提示完成安装。注册和登录:安装完成后,打开软件并注册一个账户,或使用现有账户登录。导入视频:登录后,可以导入需要添加字幕的视频文件。场辞AI支持多种视频格式。语音识别:选择视频文件后,软件将自动开始语音识别过程,将视频中的语音转换为文字。字幕生成:语音识别完成后,场辞AI会生成字幕文件。可以查看自动生成的字幕,并进行必要的编辑和校对。编辑字幕:使用场辞AI提供的编辑工具,可以调整字幕的文本内容、时间轴、样式等。多轨制作:如果视频包含多个声道或语言,可以使用多轨制作功能分别为每个声道添加字幕。实时预览:在编辑过程中,可以实时预览字幕效果,确保字幕与视频内容同步。导出字幕:编辑完成后,可以将字幕导出为SRT、ASS、XML等格式,以满足不同用途的需求。场辞的适用人群
视频制作人员:需要为视频添加字幕的导演、剪辑师和后期制作人员。自媒体创作者:制作和发布视频内容的博主、Vlogger和短视频创作者。在线教育工作者:制作教学视频并需要添加字幕的教师和教育工作者。企业宣传部门:制作企业宣传片、产品介绍视频并需要字幕的企业员工。相关资讯
更多+
-
 InfiMM-WebMath-40B – 字节联合中科院开源的超大规模多模态数据集
InfiMM-WebMath-40B – 字节联合中科院开源的超大规模多模态数据集InfiMM-WebMath-40B 是字节跳动和中国科学院联合开源的超大规模多模态数据集,旨在提升多模态模型的图文混合推理能力,在数学领域。数据集从 Common Crawl 中提取,经过严格的筛选、清洗和标注,包含 2400 万个网页、8500 万个图像 URL 和 400 亿个文本标记,涵盖了丰富的数学和科学相关内容。
AI教程资讯
 2025-01-31
2025-01-31
-
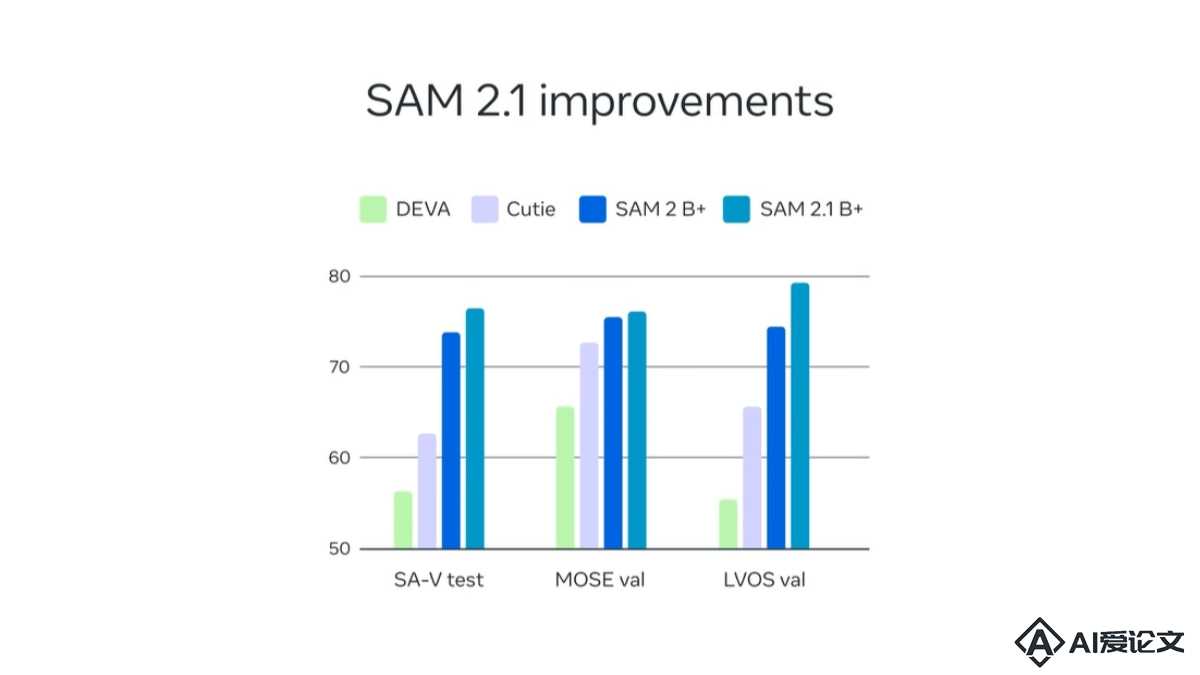 SAM 2.1 – Meta 开源的视觉分割模型
SAM 2.1 – Meta 开源的视觉分割模型SAM 2 1(全称Segment Anything Model 2 1)是Meta(Facebook的母公司)推出的先进视觉分割模型,用于图像和视频。基于简单的Transformer架构和流式记忆设计,实现实时视频处理。SAM 2 1在前代基础上引入数据增强技术,改善对视觉相似物体和小物体的识别,提升遮挡处理能力。
AI教程资讯
2025-01-31
-
 Qwen2vl-Flux – 开源的多模态图像生成模型,支持多种生成模式
Qwen2vl-Flux – 开源的多模态图像生成模型,支持多种生成模式Qwen2VL-Flux是多模态图像生成模型,结合Qwen2VL的视觉语言理解和FLUX框架,基于文本提示和图像参考生成高质量的图像。模型支持多种生成模式,包括变体生成、图像到图像转换、智能修复及ControlNet引导生成,具备深度估计和线条检测功能,实现更精确的图像控制。
AI教程资讯
2025-01-31
-
 ShowUI – 新加坡国立联合微软推出用于 GUI 自动化的视觉-语言-操作模型
ShowUI – 新加坡国立联合微软推出用于 GUI 自动化的视觉-语言-操作模型ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。
AI教程资讯
2025-01-31



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 场辞
查看
场辞
查看
-
 Duix
查看
Duix
查看
-
 开拍
查看
开拍
查看
-
 曦灵
查看
曦灵
查看
-
 Descript
查看
Descript
查看
-
 Filmora
查看
Filmora
查看
 Duix
查看
Duix
查看
 开拍
查看
开拍
查看
 曦灵
查看
曦灵
查看
 Descript
查看
Descript
查看
 Filmora
查看
热门推荐
更多+
Filmora
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14



