
 简介
简介
OneStory是什么
OneStory是一款创新的AI故事生成助手,用户只需输入文字描述,AI能帮你生成连贯的图片和视频,无需专业技能。无论是角色设计、场景布局还是动画制作。OneStory就像一个智能故事机,你只要告诉它你的故事,就能帮你画出角色、场景,甚至还能做成动画视频。OneStory让创作故事和视频变得像说话一样简单。

OneStory的主要功能
AI智能画笔:使用AI文生图、文生视频技术,将用户的文字描述转换成图像和视频,让创意快速可视化。一键生成分镜脚本:将剧本或创意文稿自动转化为专业分镜脚本和故事板,简化制作流程。影视级图像创作:即使没有美术基础,用户也能通过AI快速创作出高质量的图像故事。画面元素级控制:提供文本提示词和图像编辑器,支持用户对画面中的单个元素进行精准控制和修改。角色资产库构建:支持用户通过提示词和人物形象图片,创建个性化的角色库,打造独特的IP形象。多场景适用性:适用于多种不同的创作场景和案例,满足不同用户的个性化需求。如何使用OneStory
产品官网:访问 onestory.art ,微信扫码注册登录账号。明确创作目标:在开始之前,想清楚你想要创作的主题和风格,例如是卡通形象、科幻战士还是古装仙子等。输入描述:在OneStory的输入框中,详细描述你的角色或场景,包括外貌特征、服装、表情、动作和环境等。使用关键词:尽量使用具体和丰富的关键词来描述,AI能更准确地理解并生成你想要的图像。调整参数:根据需要,调整生成图像的参数,比如分辨率、尺寸比例等。生成图像:输入描述和调整参数后,点击生成按钮,AI将根据你的描述创建图像。筛选和优化:需要多次生成,从多个结果中选择最满意的图像,可使用局部编辑功能来调整不满意的细节。系列化创作:要保持角色或场景的一致性,尽量在后续创作中保持关键词和描述的一致性,只对细节进行微调。一键生成视频:如果你想将图像串联成视频,OneStory支持视频生成功能,可根据生成的图像一键制作动画视频。
OneStory怎么收费
OneStory提供多种订阅方案,主要包括:
免费用户:基础试用服务。普通会员:18元/月,180元/年,提供100个项目、600次重绘、8000字字符数,以及AI编辑器优先体验。高级会员:38元/月,380元/年,提供500个项目、2000次重绘、15000字字符数。团队会员:价格定制,包括团队协作功能如多人编辑和图片批注。OneStory的应用场景
个人创作:个人艺术家和爱好者可以用OneStory快速将创意转化为视觉作品,不论是绘画、插图还是动画。教育领域:教师和学生可用OneStory进行故事叙述、角色设计和场景构建教学活动,提高学生的创造力和想象力。电影和电视制作:电影制作人和电视制片人可使用OneStory来生成分镜脚本和故事板,加快前期制作流程。游戏开发:游戏开发者可使用OneStory来设计游戏角色、环境和动画,提高开发效率。虚拟现实和增强现实:VR和AR开发者可以用OneStory来创造沉浸式体验的视觉效果。企业宣传:企业用OneStory来制作宣传材料,如产品介绍视频、公司故事等,更生动地展示企业形象。出版物设计:出版行业可以用OneStory来设计书籍封面、插图和漫画,提升出版物的吸引力。艺术展览和画廊:艺术家可以用OneStory来创作数字艺术作品,用于线上或线下的艺术展览。相关资讯
更多+
-
 clone-voice – 开源的声音克隆工具,支持16种语言
clone-voice – 开源的声音克隆工具,支持16种语言Clone-voice是开源的声音克隆工具,基于深度学习技术分析和模拟人类声音,实现声音的高质量克隆。工具支持包括中文、英文、日语、韩语等在内的16种语言,能将文本转换为语音或将一种声音风格转换为另一种。用户界面友好,操作简单,不需要高性能的硬件支持,适合个人和专业领域使用。
AI教程资讯
 2025-01-28
2025-01-28
-
 SNOOPI – AI文本到图像生成框架,提升单步扩散模型的效率和性能
SNOOPI – AI文本到图像生成框架,提升单步扩散模型的效率和性能SNOOPI是创新的文本到图像生成框架,基于增强单步扩散模型的指导提升模型性能和控制力。SNOOPI包括PG-SB(适当指导 - SwiftBrush)和NASA(负向远离转向注意力)两种技术。PG-SB用随机尺度的无分类器引导方法,增强训练稳定性;NASA用交叉注意力机制整合负面提示,有效抑制生成图像中的不期望元素。
AI教程资讯
2025-01-28
-
 MEMO – 音频驱动的生成肖像说话视频框架,保持身份一致性和表现力
MEMO – 音频驱动的生成肖像说话视频框架,保持身份一致性和表现力MEMO(Memory-Guided EMOtionaware diffusion)是Skywork AI、南洋理工大学和新加坡国立大学推出的音频驱动肖像动画框架,用在生成具有身份一致性和表现力的说话视频。MEMO围绕两个核心模块构建:记忆引导的时间模块和情感感知音频模块。
AI教程资讯
2025-01-28
-
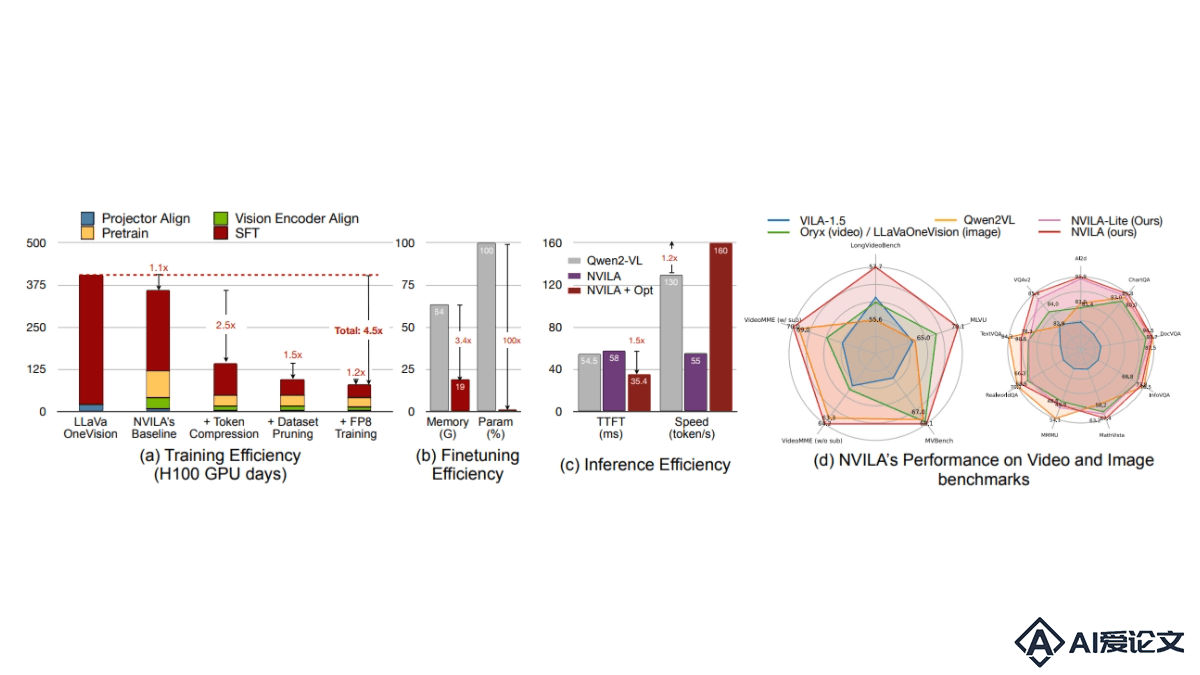 NVILA – 英伟达推出的视觉语言大模型
NVILA – 英伟达推出的视觉语言大模型NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。
AI教程资讯
2025-01-27



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 OneStory
查看
OneStory
查看
-
 Stable Video
查看
Stable Video
查看
-
 D-ID
查看
D-ID
查看
-
 Humva
查看
Humva
查看
-
 Viva
查看
Viva
查看
-
 Hotshot
查看
Hotshot
查看
 Stable Video
查看
Stable Video
查看
 D-ID
查看
D-ID
查看
 Humva
查看
Humva
查看
 Viva
查看
Viva
查看
 Hotshot
查看
热门推荐
更多+
Hotshot
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14



