
 简介
简介
Sora是什么
Sora是由OpenAI研发的AI视频生成模型,具备将文本描述转化为视频的能力,能够创造出既逼真又富有想象力的视频场景。该模型专注于模拟物理世界的运动,旨在帮助人们解决需要现实世界互动的问题。相较于Pika、Runway、PixVerse、Morph Studio、Genmo等只能生成四五秒的AI视频工具,Sora能够生成长达一分钟的视频,同时保持视觉质量和对用户输入的高度还原。除从零开始创建视频,Sora还能基于现有静态图像生成动画,或者扩展和补全现有视频。

需要注意的是,尽管Sora的功能看起来非常强大,但目前还没有正式对外开放,OpenAI正在对其进行红队测试、安全检查和优化。OpenAI的官网上目前只有对Sora的介绍、视频Demo和技术讲解,暂未提供可直接使用的视频生成工具或API。madewithsora.com网站上收集了Sora生成的视频,感兴趣的朋友可以前往观看。
Sora的主要功能
文本驱动的视频生成:Sora 能够根据用户提供的详细文本描述,生成与之相符的视频内容。这些描述可以涉及场景、角色、动作、情感等多个方面。视频质量与忠实度:生成的视频保持高质量的视觉效果,并且紧密遵循用户的文本提示,确保视频内容与描述相符。模拟物理世界:Sora旨在模拟现实世界的运动和物理规律,使得生成的视频在视觉上更加逼真,能够处理复杂的场景和角色动作。多角色与复杂场景处理:模型能够处理包含多个角色和复杂背景的视频生成任务,尽管在某些情况下可能存在局限性。视频扩展与补全:Sora不仅能从头开始生成视频,还能基于现有的静态图像或视频片段进行动画制作,或者延长现有视频的长度。Sora的技术原理

OpenAI Sora的技术架构猜想
文本条件生成:Sora模型能够根据文本提示生成视频,这是通过将文本信息与视频内容相结合实现的。这种能力使得模型能够理解用户的描述,并生成与之相符的视频片段。视觉块(Visual Patches):Sora将视频和图像分解为小块的视觉块,作为视频和图像的低维表示。这种方法允许模型处理和理解复杂的视觉信息,同时保持计算效率。视频压缩网络:在生成视频之前,Sora使用一个视频压缩网络将原始视频数据压缩到一个低维的潜在空间。这个压缩过程减少了数据的复杂性,使得模型更容易学习和生成视频内容。空间时间块(Spacetime Patches):在视频压缩后,Sora进一步将视频表示分解为一系列空间时间块,作为模型的输入,使得模型能够处理和理解视频的时空特性。扩散模型(Diffusion Model):Sora采用扩散模型(基于Transformer架构的DiT模型)作为其核心生成机制。扩散模型通过逐步去除噪声并预测原始数据的方式来生成内容。在视频生成中,这意味着模型会从一系列噪声补丁开始,逐步恢复出清晰的视频帧。Transformer架构:Sora利用Transformer架构来处理空间时间块。Transformer是一种强大的神经网络模型,在处理序列数据(如文本和时间序列)方面表现出色。在Sora中,Transformer用于理解和生成视频帧序列。大规模训练:Sora在大规模的视频数据集上进行训练,这使得模型能够学习到丰富的视觉模式和动态变化。大规模训练有助于提高模型的泛化能力,使其能够生成多样化和高质量的视频内容。文本到视频的生成:Sora通过训练一个描述性字幕生成器,将文本提示转换为详细的视频描述。然后,这些描述被用来指导视频生成过程,确保生成的视频内容与文本描述相匹配。零样本学习:Sora能够通过零样本学习来执行特定的任务,如模拟特定风格的视频或游戏。即模型能够在没有直接训练数据的情况下,根据文本提示生成相应的视频内容。模拟物理世界:Sora在训练过程中展现出了模拟物理世界的能力,如3D一致性和物体持久性,表明该模型能够在一定程度上理解并模拟现实世界中的物理规律。OpenAI官方Sora技术报告:https://openai.com/research/video-generation-models-as-world-simulators机器之心解读的Sora技术细节:https://www.jiqizhixin.com/articles/2024-02-16-7赛博禅心 – 中学生能看懂:Sora 原理解读:https://mp.weixin.qq.com/s/KUnXlDlg-Rs_6D5RFpQbnQSora的应用场景
社交媒体短片制作:内容创作者快速制作出吸引人的短片,用于在社交媒体平台上分享。创作者可以轻松地将他们的想法转化为视频,而无需投入大量的时间和资源去学习视频编辑软件。Sora还可以根据社交媒体平台的特点(如短视频、直播等)生成适合特定格式和风格的视频内容。广告营销:快速生成广告视频,帮助品牌在短时间内传达核心信息。Sora可以生成具有强烈视觉冲击力的动画,或者模拟真实场景来展示产品特性。此外,Sora还可以帮助企业测试不同的广告创意,通过快速迭代找到最有效的营销策略。原型设计和概念可视化:对于设计师和工程师来说,Sora可以作为一个强大的工具来可视化他们的设计和概念。例如,建筑师可以使用Sora生成建筑项目的三维动画,让客户更直观地理解设计意图。产品设计师可以利用 Sora 展示新产品的工作原理或用户体验流程。影视制作:辅助导演和制片人在前期制作中快速构建故事板,或者生成初步的视觉效果。这可以帮助团队在实际拍摄前更好地规划场景和镜头。此外,Sora还可以用于生成特效预览,让制作团队在预算有限的情况下,探索不同的视觉效果。教育和培训:Sora 可以用来创建教育视频,帮助学生更好地理解复杂的概念。例如,它可以生成科学实验的模拟视频,或者历史事件的重现,使得学习过程更加生动和直观。如何使用Sora
OpenAI Sora目前暂未提供公开访问使用的入口,该模型正在接受红队(安全专家)的评估,只向少数视觉艺术家、设计师和电影制作人进行测试评估。OpenAI没有指定更广泛的公众可用性的具体时间表,不过可能是2024年的某个时间。若想现在获得访问权限,个人需要根据OpenAI定义的专家标准获得资格,其中包括属于参与评估模型有用性和风险缓解策略的相关专业团体。
相关资讯
更多+
-
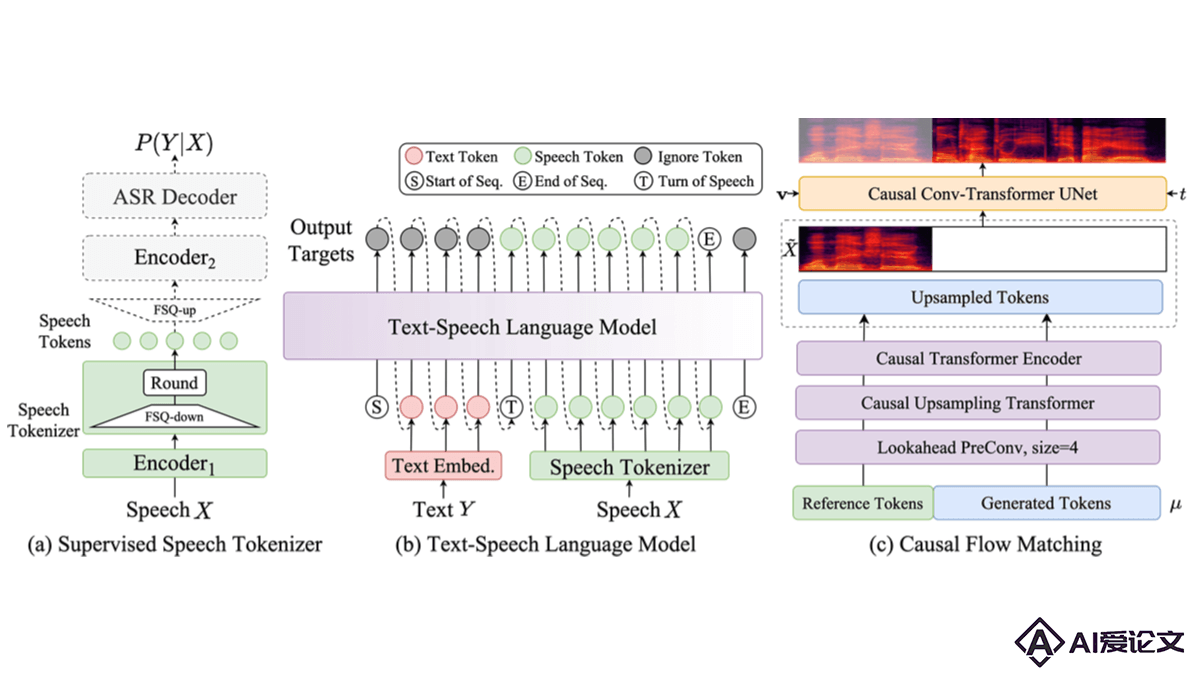 CosyVoice 2.0 – 阿里开源的语音生成大模型
CosyVoice 2.0 – 阿里开源的语音生成大模型CosyVoice 2 0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升。
AI教程资讯
 2025-01-23
2025-01-23
-
 Megrez-3B-Omni – 无问芯穹开源的端侧全模态理解模型
Megrez-3B-Omni – 无问芯穹开源的端侧全模态理解模型Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。
AI教程资讯
2025-01-23
-
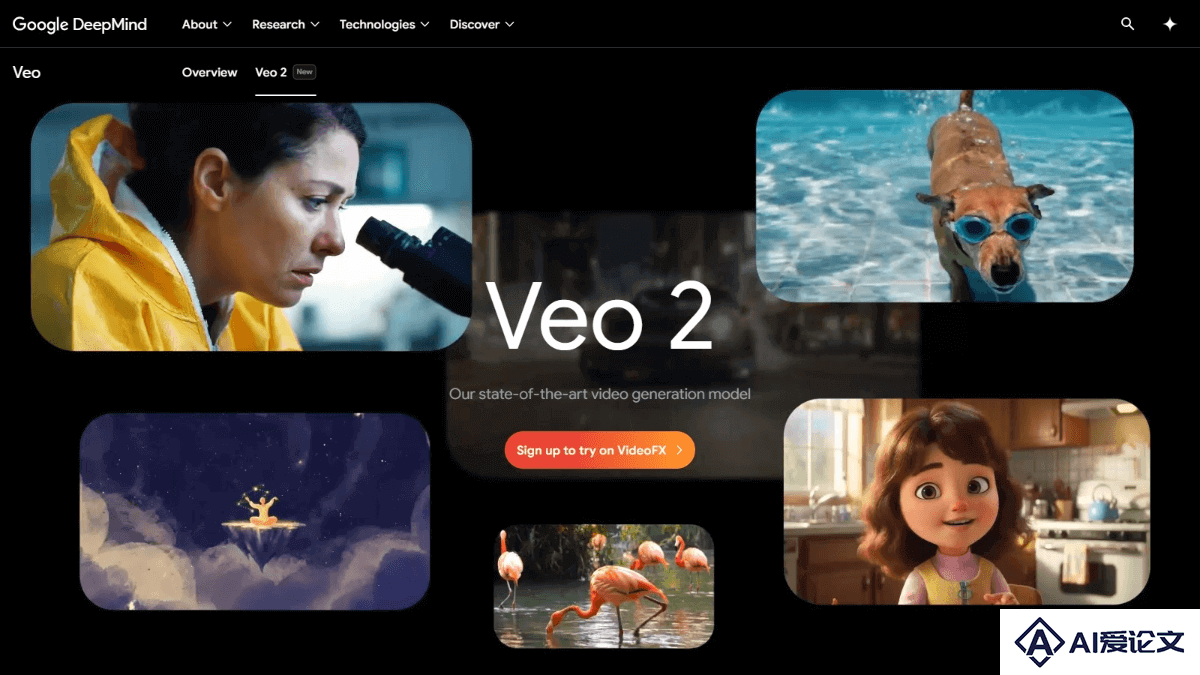 Veo 2 – 谷歌 DeepMind 推出的 AI 视频生成模型,支持高达 4K 分辨率
Veo 2 – 谷歌 DeepMind 推出的 AI 视频生成模型,支持高达 4K 分辨率Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2 在 Meta 的 MovieGenBench 基准测试中表现优异,优于其他视频生成模型(如Meta、Minimax)。
AI教程资讯
2025-01-23
-
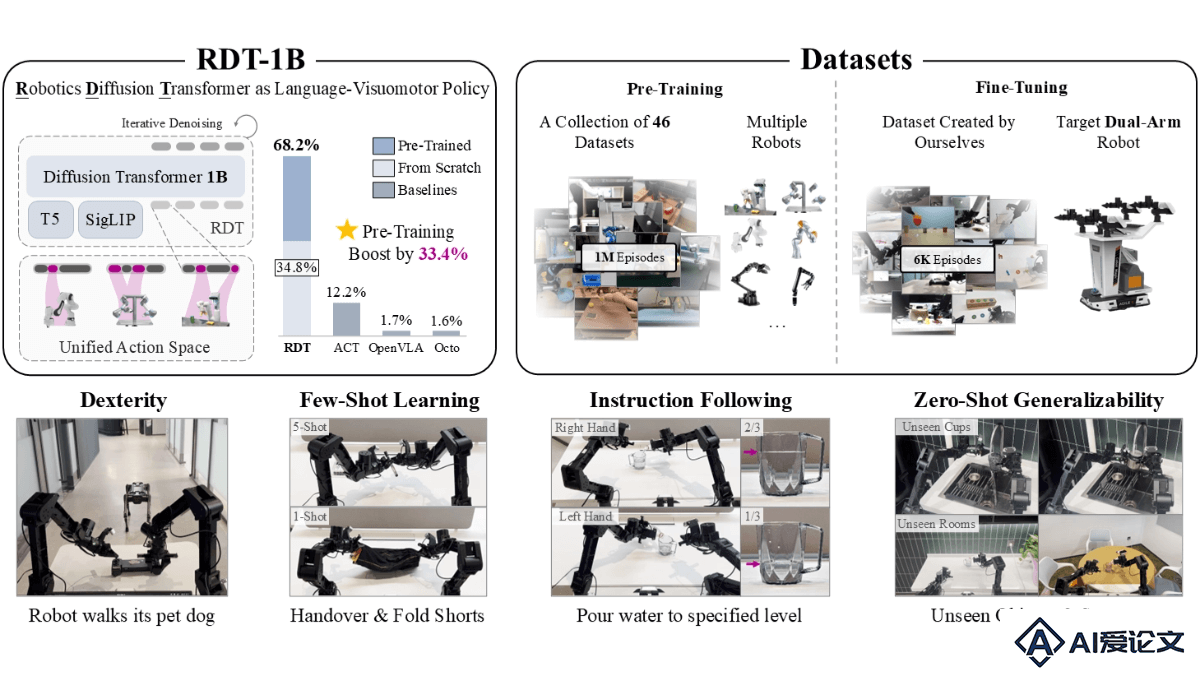 RDT – 清华开源的双臂机器人扩散基础模型
RDT – 清华开源的双臂机器人扩散基础模型RDT(Robotics Diffusion Transformer)是清华大学AI研究院TSAIL团队推出的全球最大的双臂机器人操作任务扩散基础模型。RDT具备十亿参数量,能在无需人类操控的情况下,自主完成复杂任务,如调酒和遛狗。
AI教程资讯
2025-01-23



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Sora
查看
Sora
查看
-
 即梦AI
查看
即梦AI
查看
-
 可灵AI
查看
可灵AI
查看
-
 秒创
查看
秒创
查看
-
 巨日禄
查看
巨日禄
查看
-
 有言
查看
有言
查看
 即梦AI
查看
即梦AI
查看
 可灵AI
查看
可灵AI
查看
 秒创
查看
秒创
查看
 巨日禄
查看
巨日禄
查看
 有言
查看
热门推荐
更多+
有言
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14



