
 简介
简介
千鹿AI是什么
千鹿AI是一个AI设计助手,提供AI文生图/图生图、AI扩图、AI线稿上色、AI抠图等功能,大幅提高设计师和内容创作者的工作效率。用户每日可免费生成300张图像,适合电商、广告和社交媒体等场景。平台界面简洁,操作便捷,支持多种操作系统和设计软件。

千鹿AI的主要功能
AI文生图:通过输入提示词,AI自动生成符合要求的图片。AI图生图:基于现有图片,生成风格多元的图像作品。AI线稿上色:智能为线稿配色,提升创作效率。AI局部重绘:重新绘制图片中的指定元素,快速修改图片细节。AI免抠图生成:一键自动去除背景,提取主体。AI扩图:扩展图片的画面内容,增大创意空间。AI高清修复:对模糊图片进行高清修复,提升图片清晰度。AI智能擦除:去除图片中的不需要的元素,保持无痕迹效果。如何使用千鹿AI
访问官网:访问千鹿AI的官方网站。选择功能:根据需求选择合适的AI工具,例如AI生图、抠图、扩图、线稿上色等。生成图片:输入提示词或上传图片。例如,使用AI文生图时,输入相关的提示词;或者上传已有的图片进行处理。风格编辑处理:选择所需的上色风格或图片处理选项。千鹿AI提供了多种上色风格和图片处理功能,可以根据个人喜好进行选择。颜色细节处理:微调颜色或图片细节。如果需要,可以调整颜色或对图片的特定区域进行局部调整。导出图片:生成并下载图片。处理完成后,可以立即下载图片,用于商业或个人创意项目。千鹿AI的产品定价
免费:每天为用户提供300张图的免费生成额度;单次生成图片2张,不支持批量下载和去水印,适合日常图片处理需求。会员:每月提供15000张图生成额度;生图加速每月1000次;单次生成图片24张;支持批量下载和去水印。包月49元;连续包月29.9元;一年送6个月299元;两年送1年499元。千鹿AI的应用场景
电商领域:在电商平台上,高质量的商品图片能吸引消费者注意,提升点击率和转化率。千鹿AI的AI去背景功能可以帮助电商卖家快速将商品图片背景更换为白底或其他颜色,提高商品展示的专业度。营销素材制作:千鹿AI能轻松生成电商和营销素材,帮助用户快速实现创意想法,提高内容创作的效率。设计师工作:设计师可以用千鹿AI的多种图像处理功能,如智能抠图、AI扩图、高清修复等,来提升工作效率,实现创意设计。摄影后期处理:摄影师可以用千鹿AI的图片修复和上色功能,对照片进行后期处理,恢复老照片或增强照片效果。艺术创作:绘画爱好者可以用千鹿AI的线稿上色功能,为艺术作品增添色彩,实现艺术创作。社交媒体内容创作:社交媒体用户可以用千鹿AI生成独特的图片内容,用于个人资料图片、封面图片或帖子配图,增加个人内容的吸引力。相关资讯
更多+
-
 StableV2V – 中国科技大学开源的视频编辑项目
StableV2V – 中国科技大学开源的视频编辑项目StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。
AI教程资讯
 2025-02-05
2025-02-05
-
 Halo – 开源的DIY健康追踪项目,构建私人健康检测应用
Halo – 开源的DIY健康追踪项目,构建私人健康检测应用Halo是开源的DIY健康追踪项目,基于低成本的智能戒指和开源软件,让用户构建自己的私人健康监测应用。Halo支持活动追踪、心率监测、睡眠分析等功能,且完全尊重用户隐私。基于Halo,用户能深入了解自己的健康数据,享受定制化的健康追踪体验。
AI教程资讯
2025-02-05
-
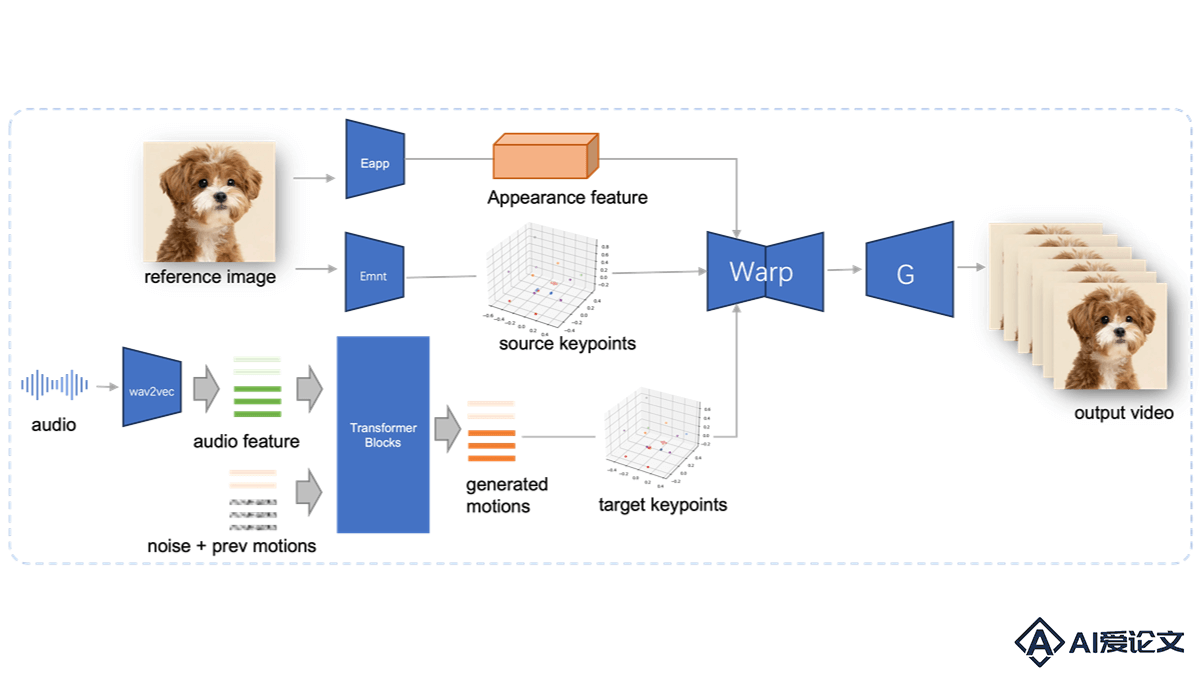 JoyVASA – 京东健康开源的音频驱动的数字人头项目
JoyVASA – 京东健康开源的音频驱动的数字人头项目JoyVASA是京东健康国际公司开源的音频驱动的数字人头项目,基于扩散模型技术,根据音频信号生成与音频同步的面部动态和头部运动。JoyVASA能实现人物的唇形同步和表情控制,还扩展到动物头像的动画生成,在多语种支持和跨物种动画化方面具有广泛的应用潜力。
AI教程资讯
2025-02-05
-
 TIP-I2V – 超170万大规模真实文本和图像提示数据集
TIP-I2V – 超170万大规模真实文本和图像提示数据集TIP-I2V是大规模真实文本和图像提示数据集,用在图像到视频生成领域。TIP-I2V包含超过170万独特的用户文本和图像提示,及五种SOTA图生视频模型生成的相应视频。数据集能推动更好、更安全的图像到视频模型的发展,帮助研究人员分析用户偏好,评估模型性能,解决图像到视频模型引起的错误信息问题。
AI教程资讯
2025-02-05



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 千鹿AI
查看
千鹿AI
查看
-
 Upscayl
查看
Upscayl
查看
-
 Relight
查看
Relight
查看
-
 Facet
查看
Facet
查看
-
 Skybox AI
查看
Skybox AI
查看
-
 行者AI美术
查看
行者AI美术
查看
 Upscayl
查看
Upscayl
查看
 Relight
查看
Relight
查看
 Facet
查看
Facet
查看
 Skybox AI
查看
Skybox AI
查看
 行者AI美术
查看
热门推荐
更多+
行者AI美术
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高




