
 简介
简介
Stable Doodle 是Stability AI(Stable Diffusion背后的公司)最新推出的将手绘草图转换成精美图像的工具,无论你是专业人士,还是绘画爱好者,都可以借助 Stable Doodle 快速将简单的手绘稿变为现实,让你从灵魂画手变身艺术大师。
通过 Stable Doodle 任何具有基本绘图技能和访问在线网站的人都可以在几秒钟内生成高质量的原始图像,设计师、插画师和其他专业人士能够腾出宝贵的时间并最大限度地提高效率,以草图形式绘制的想法可以立即落地到作品中,为客户创建设计、为展示平台和网站创建物料、甚至创建LOGO标志。
目前 Stable Doodle与最新的 Stable Diffusion 模型 SDXL 0.9 一起都可以在Stability AI 旗下的 Clipdrop 网站上免费试用。
AI工具集编辑随意画了3栋楼的轮廓,然后输入简单的skyscraper buildings提示词,下面生成的3张效果图还是不错的。
 相关资讯
更多+
相关资讯
更多+
-
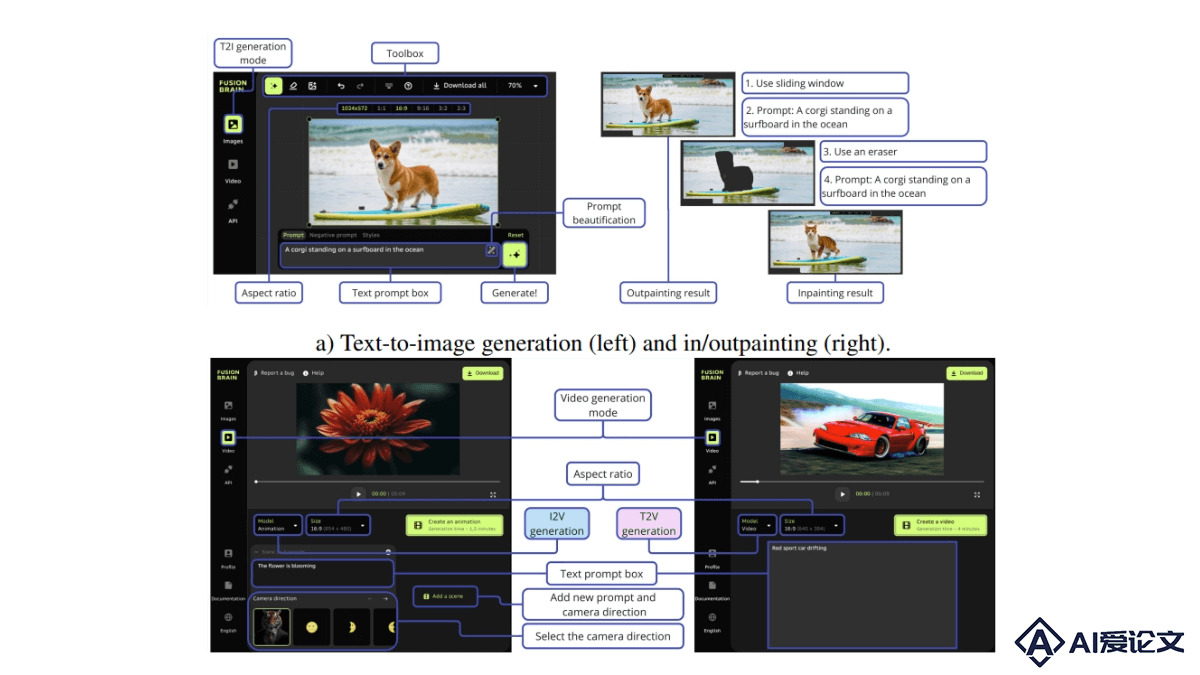 Kandinsky-3 – 开源的文本到图像生成框架,适应多种图像生成任务
Kandinsky-3 – 开源的文本到图像生成框架,适应多种图像生成任务Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,以高质量和逼真度在图像合成领域脱颖而出。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复 扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。
AI教程资讯
 2025-02-02
2025-02-02
-
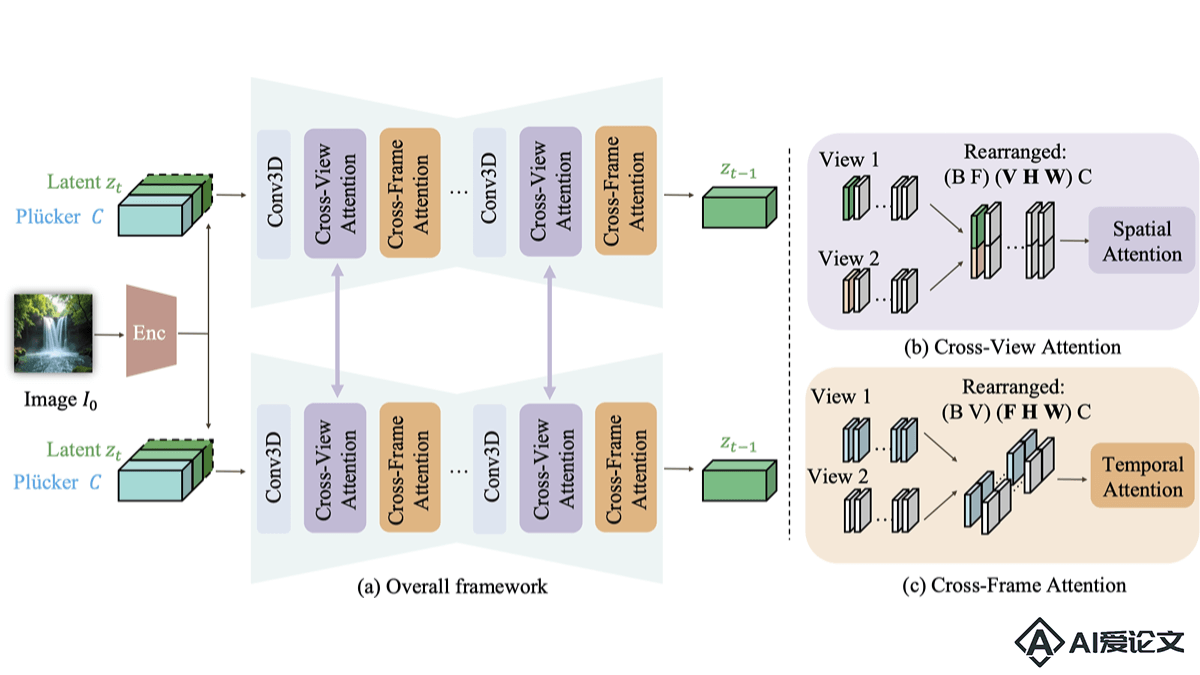 CAVIA – 苹果、得克萨斯、谷歌联合推出的多视角视频生成框架
CAVIA – 苹果、得克萨斯、谷歌联合推出的多视角视频生成框架CAVIA是苹果公司、得克萨斯大学奥斯汀分校、谷歌联合推出的多视角视频生成框架,能将单一输入图像转换成多个时空一致的视频序列。框架基于引入视角集成注意力模块,增强视频的视角一致性和时间连贯性,支持用户精确控制相机运动,同时保留对象运动。
AI教程资讯
2025-02-02
-
 Flex3D – Meta GenAI和牛津大学共同推出的两阶段3D生成框架
Flex3D – Meta GenAI和牛津大学共同推出的两阶段3D生成框架Flex3D是由Meta的GenAI团队和牛津大学研究团队推出的创新的两阶段3D生成框架,能基于任意数量的高质量输入视图,解决从文本、单张图片或稀疏视图图像生成高质量3D内容的挑战。第一阶段,基于微调的多视图和视频扩散模型生成多样化的候选视图,用视图选择机制确保只有高质量和一致的视图被用于重建。
AI教程资讯
2025-02-02
-
 EvolveDirector – 阿里联合南洋理工推出文本到图像生成模型的高效训练技术
EvolveDirector – 阿里联合南洋理工推出文本到图像生成模型的高效训练技术EvolveDirector是阿里巴巴和南洋理工大学联合推出的创新框架,用公开资源和高级模型的API接口训练一个高性能的文本到图像生成模型。框架基于与现有高级模型的API交互获取数据对,训练一个基础模型,并借助预训练的大型视觉语言模型(VLMs)动态优化训练数据集,显著减少所需的数据量和训练成本。
AI教程资讯
2025-02-02



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Stable Doodle
查看
Stable Doodle
查看
-
 Stockimg AI
查看
Stockimg AI
查看
-
 Freepik AI Image Generator
查看
Freepik AI Image Generator
查看
-
 Imagine with Meta
查看
Imagine with Meta
查看
-
 网易AI创意工坊
查看
网易AI创意工坊
查看
-
 360智绘
查看
360智绘
查看
 Stockimg AI
查看
Stockimg AI
查看
 Freepik AI Image Generator
查看
Freepik AI Image Generator
查看
 Imagine with Meta
查看
Imagine with Meta
查看
 网易AI创意工坊
查看
网易AI创意工坊
查看
 360智绘
查看
热门推荐
更多+
360智绘
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高




