
 简介
简介
StableVicuna 是由 Stable Diffusion 背后的 StabilityAI 推出的第一个通过基于人类反馈的强化学习(RLHF)训练的大规模开源聊天机器人。StableVicuna是Vicuna v0 13b的进一步指令微调和RLHF训练版本,它是一个指令微调的 LLaMA 130亿模型。
相关资讯
更多+
-
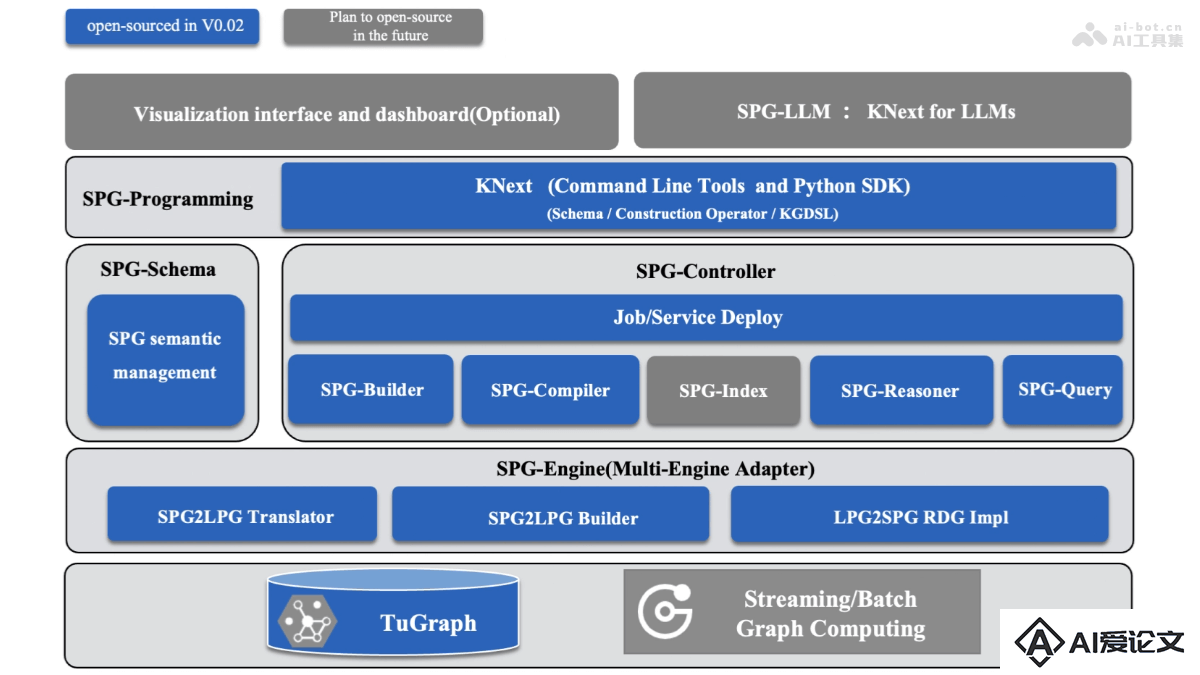 OpenSPG – 蚂蚁联合OpenKG开源的知识图谱引擎
OpenSPG – 蚂蚁联合OpenKG开源的知识图谱引擎OpenSPG是蚂蚁集团联合OpenKG社区推出的基于SPG框架的知识图谱引擎。OpenSPG融合LPG的结构性和RDF的语义性,克服RDF OWL语义复杂难以落地的问题,继承LPG结构简单与大数据体系兼容的优势。
AI教程资讯
 2025-02-14
2025-02-14
-
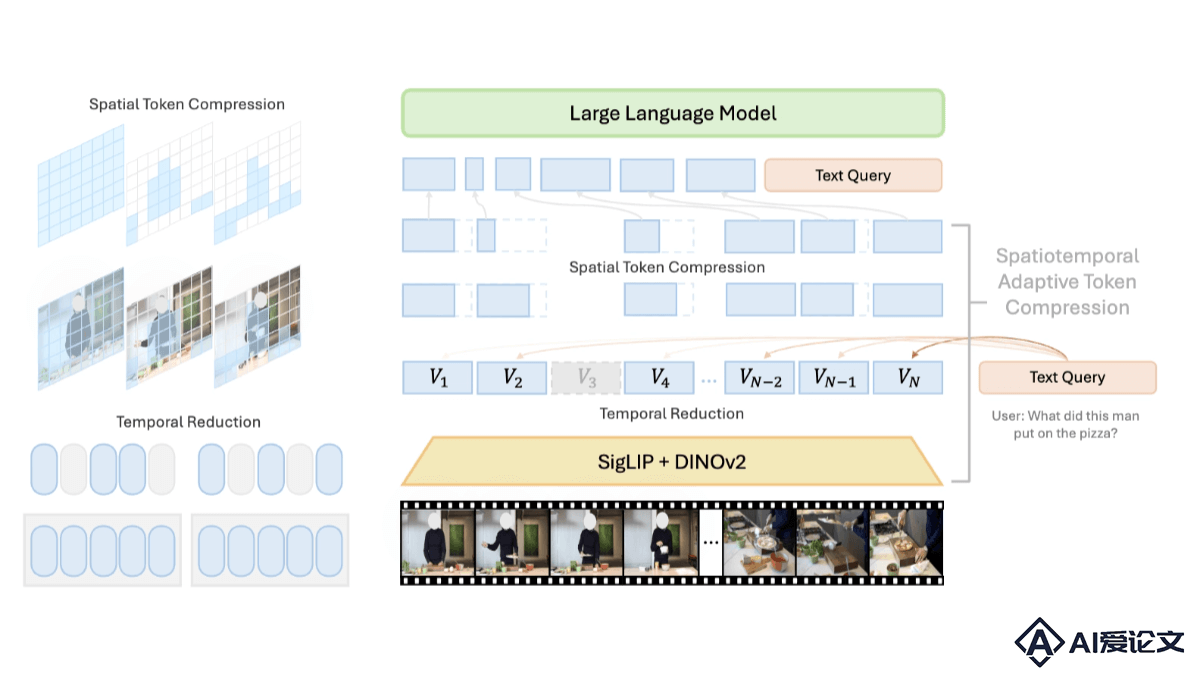 LongVU – Meta AI开源的长视频理解模型
LongVU – Meta AI开源的长视频理解模型LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节
AI教程资讯
2025-02-13
-
 SynthID Text – 谷歌DeepMind推出的AI生成文本水印技术
SynthID Text – 谷歌DeepMind推出的AI生成文本水印技术SynthID Text 是谷歌DeepMind 推出的文本水印技术,用在识别和验证由大型语言模型(LLM)生成的文本。基于细微调整生成过程中的Token概率分数嵌入几乎无法察觉的水印,在不影响文本质量和用户体验的情况下,实现高检测精度。
AI教程资讯
2025-02-13
-
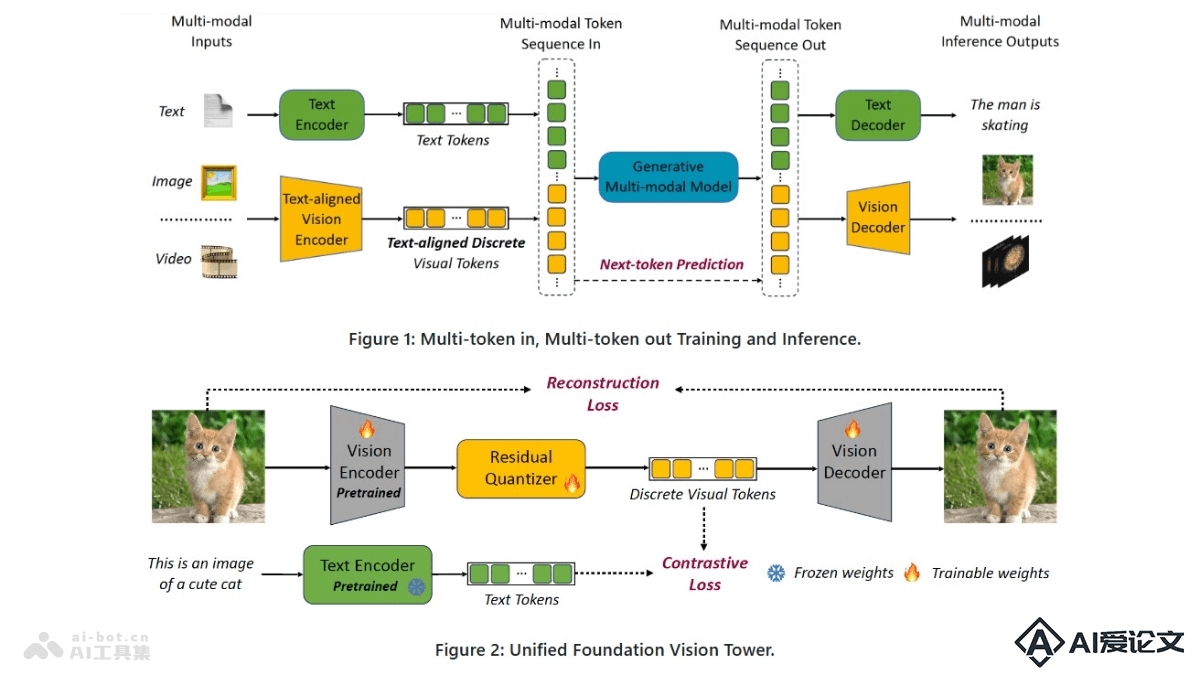 VILA-U – 融合多模态理解和生成的统一基础模型
VILA-U – 融合多模态理解和生成的统一基础模型VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。
AI教程资讯
2025-02-13



 最新录入
更多+
最新录入
更多+

 查看
查看




 同类别攻略
更多+
同类别攻略
更多+
- AnimePro FLUX – 动漫风格图像生成模型,基于Flux.1 Shnell模型微调 2025-02-10
- HK-O1aw – HKGAI团队联合北大团队推出的慢思考范式法律推理大模型 2025-02-10
- SeedEdit – 字节豆包团队推出的AI图像编辑模型 2025-02-10
- DimensionX – 港科大、清华和生数科技共同推出的单图像生成复杂3D、4D场景框架 2025-02-10
- App Intents – 苹果推出的集成Siri和Apple Intelligence新框架 2025-02-10
- HourVideo – 李飞飞和吴佳俊团队推出的长视频理解基准数据集 2025-02-10
 同类别推荐
更多+
同类别推荐
更多+
-
 StableVicuna
查看
StableVicuna
查看
-
 Imagen
查看
Imagen
查看
-
 HuggingFace
查看
HuggingFace
查看
-
 天壤小白
查看
天壤小白
查看
-
 Segment Anything(SAM)
查看
Segment Anything(SAM)
查看
-
 OpenBMB
查看
OpenBMB
查看
 Imagen
查看
Imagen
查看
 HuggingFace
查看
HuggingFace
查看
 天壤小白
查看
天壤小白
查看
 Segment Anything(SAM)
查看
Segment Anything(SAM)
查看
 OpenBMB
查看
热门推荐
更多+
OpenBMB
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

66AI论文是专业的AI论文写作工具,覆盖720多个学科领域。能在10秒内生成千字论文大纲,3分钟内完成万字论文初稿。平台承诺论文查重率控制在10%左右,超出此标准可申请退款,确保用户获得高质量、低重复率的论文。
-
5

悟智写作是一个由人工智能技术驱动的内容创作平台,旨在帮助用户高效地创作出高质量的文本内容。该AI写作工具提供了超过100种不同行业和场景的文本模板,无论是撰写广告文案、学术文章、电子邮件、产品描述,还是创作吸引人的标题,用户都能在几分钟内完成。
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高



