
 简介
简介
OpenBMB全称为Open Lab for Big Model Base,旨在打造大规模预训练语言模型库与相关工具, 加速百亿级以上大模型的训练、微调与推理,降低大模型使用门槛,与国内外开发者共同努力形成大模型开源社区, 推动大模型生态发展,实现大模型的标准化、普及化和实用化,让大模型飞入千家万户。
OpenBMB开源社区由清华大学自然语言处理实验室和智源研究院语言大模型加速技术创新中心共同支持发起。 发起团队拥有深厚的自然语言处理和预训练模型研究基础,近年来围绕模型预训练、提示微调、模型压缩技术等方面在顶级国际会议上发表了数十篇高水平论文。
相关资讯
更多+
-
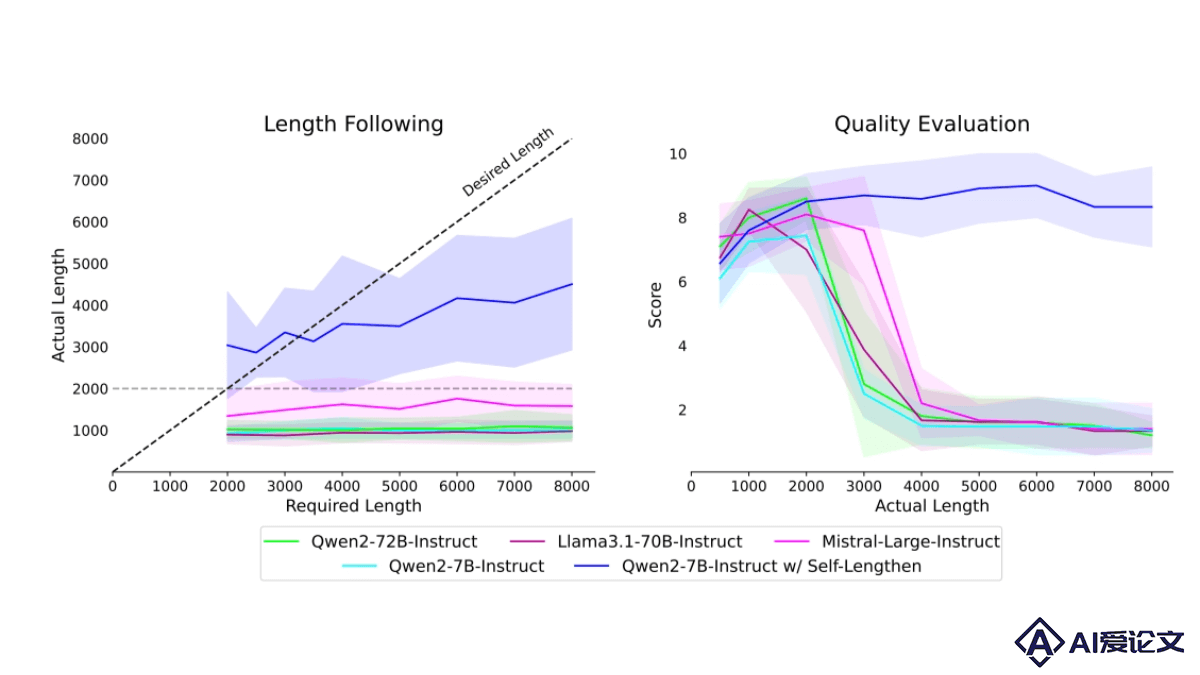 Self-Lengthen – 阿里千问推出的提升输出长度迭代训练框架
Self-Lengthen – 阿里千问推出的提升输出长度迭代训练框架Self-Lengthen是阿里巴巴千问团队推出的创新的迭代训练框架,能提升大型语言模型(LLMs)生成长文本的能力。框架基于两个角色,生成器和扩展器协同工作,生成器负责生成初始响应,扩展器将响应拆分、扩展产生更长的文本。
AI教程资讯
 2025-02-12
2025-02-12
-
 Amphion – 开源的全能AI音频项目,面向音频、音乐和语音生成的工具包
Amphion – 开源的全能AI音频项目,面向音频、音乐和语音生成的工具包Amphion是开源的音频、音乐和语音生成工具包,是香港中文大学(深圳)副教授武执政团队联合上海人工智能实验室和深圳市大数据研究院共同推出的。工具包支持可重复的研究,帮助初级研究人员和工程师快速进入音频、音乐和语音生成领域。
AI教程资讯
2025-02-12
-
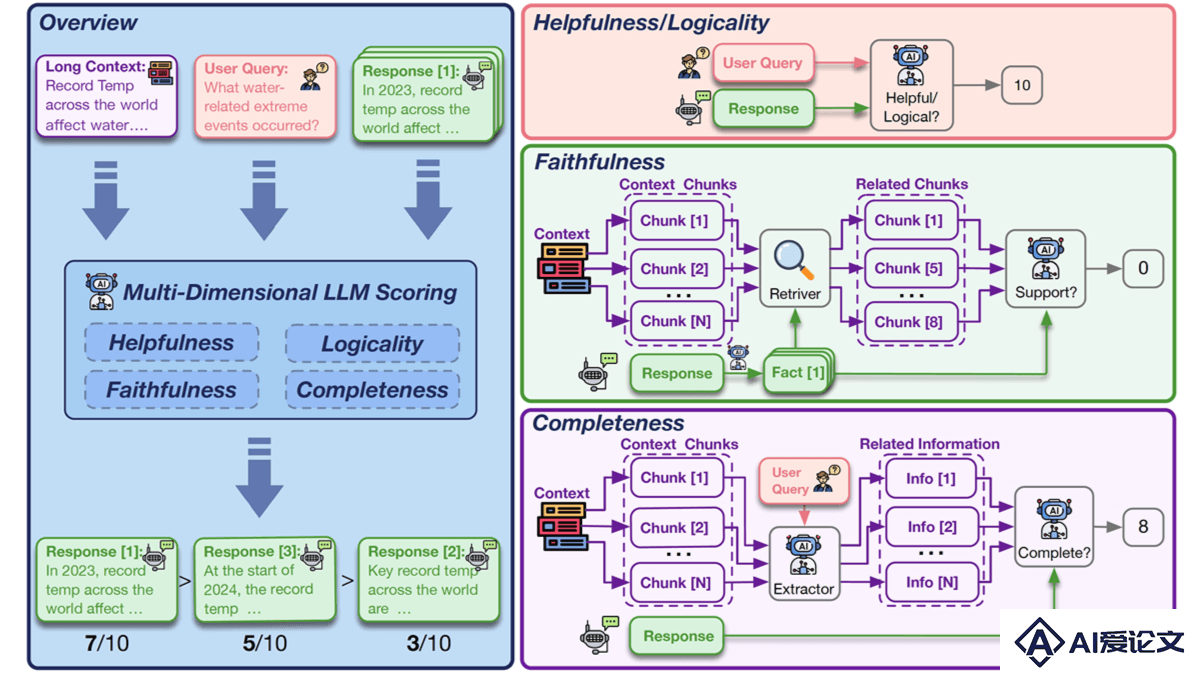 LongReward – 清华、中科院、智谱AI联合推出提升长文本大语言模型性能的方法
LongReward – 清华、中科院、智谱AI联合推出提升长文本大语言模型性能的方法LongReward是清华大学、中国科学院、智谱AI联合推出的,基于AI反馈改进长文本大型语言模型(LLMs)性能的方法。LongReward从有用性、逻辑性、忠实性和完整性四个维度为模型响应打分,提供奖励信号,强化学习的方式优化模型,让模型在处理长文本时更准确、一致,能更好地遵循指令。
AI教程资讯
2025-02-12
-
 Fish Agent – FishAudio推出的端到端语音处理模型
Fish Agent – FishAudio推出的端到端语音处理模型Fish Agent是FishAudio推出的创新的端到端语音处理模型,集成自动语音识别(ASR)和文本到语音(TTS)技术,无需传统的语义编码器 解码器,即可实现语音到语音的直接转换。模型经过700,000小时的多语言音频内容训练,支持包括英语、中文在内的多种语言,精准捕捉和生成环境音频信息
AI教程资讯
2025-02-12



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- smolagents – Hugging Face 开源的轻量级 Agent 构建库 2025-01-15
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- ConceptMaster – 高保真多概念视频定制生成的创新 AI 框架 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 OpenBMB
查看
OpenBMB
查看
-
 PaLM 2
查看
PaLM 2
查看
-
 DeepSpeed
查看
DeepSpeed
查看
-
 Gen-2
查看
Gen-2
查看
-
 StableLM
查看
StableLM
查看
-
 Lamini
查看
Lamini
查看
 PaLM 2
查看
PaLM 2
查看
 DeepSpeed
查看
DeepSpeed
查看
 Gen-2
查看
Gen-2
查看
 StableLM
查看
StableLM
查看
 Lamini
查看
热门推荐
更多+
Lamini
查看
热门推荐
更多+



- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14





