
 简介
相关资讯
更多+
简介
相关资讯
更多+
-
 Vision Search Assistant – 结合视觉语言模型和网络代理搜索技术的开源框架
Vision Search Assistant – 结合视觉语言模型和网络代理搜索技术的开源框架Vision Search Assistant(VSA)是结合视觉语言模型(VLMs)和网络代理的框架,提升模型对未知视觉内容的理解能力。基于互联网检索,使VLMs处理和回答有关未见图像的问题。VSA在开放集和封闭集问答测试中表现出色,显著优于包括LLaVA-1 6-34B、Qwen2-VL-72B和InternVL2-76B在内的其他模型。
AI教程资讯
 2025-02-08
2025-02-08
-
 MVDrag3D – 南洋理工大学推出的拖拽式多视图3D编辑技术
MVDrag3D – 南洋理工大学推出的拖拽式多视图3D编辑技术MVDrag3D是创新的3D编辑框架,结合多视图生成和重建先验实现灵活且富有创造性的拖拽编辑。框架用多视图扩散模型作为生成先验,确保在多个渲染视图间进行一致的拖拽编辑,基于重建模型重建编辑对象的3D高斯表示,用视图特定的变形网络调整高斯位置实现视图间的对齐,最终用多视图分数函数增强视图一致性和视觉质量。
AI教程资讯
2025-02-08
-
 Chonkie – RAG文本分块库,基于Token、单词、句子和语义的多种分块方法
Chonkie – RAG文本分块库,基于Token、单词、句子和语义的多种分块方法Chonkie是轻量级、快速且功能丰富的RAG(Retrieval-Augmented Generation)分块库,为文本处理设计。Chonkie支持基于Token、单词、句子和语义的多种分块方法,易于安装和使用,无冗余,适合各种自然语言处理任务。Chonkie以高效性能和广泛的tokenizer支持,成为开发者在构建RAG应用时的首选库。
AI教程资讯
2025-02-08
-
 MSQA – 大规模多模态3D情境推理数据集
MSQA – 大规模多模态3D情境推理数据集MSQA(Multi-modal Situated Question Answering)是大规模多模态情境推理数据集,提升具身AI代理在3D场景中的理解与推理能力。数据集包含251K个问答对,覆盖9个问题类别,基于3D场景图和视觉-语言模型在真实世界3D场景中收集。MSQA用文本、图像和点云的交错多模态输入,减少单模态输入的歧义。
AI教程资讯
2025-02-08



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
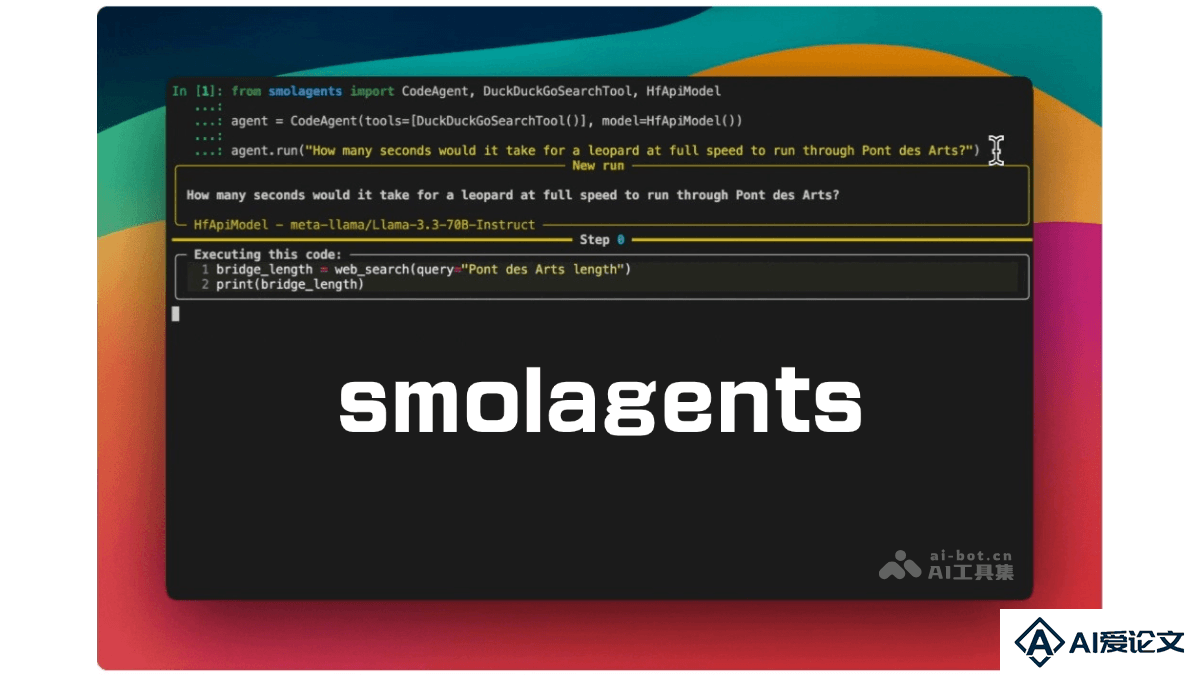
- smolagents – Hugging Face 开源的轻量级 Agent 构建库 2025-01-15
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
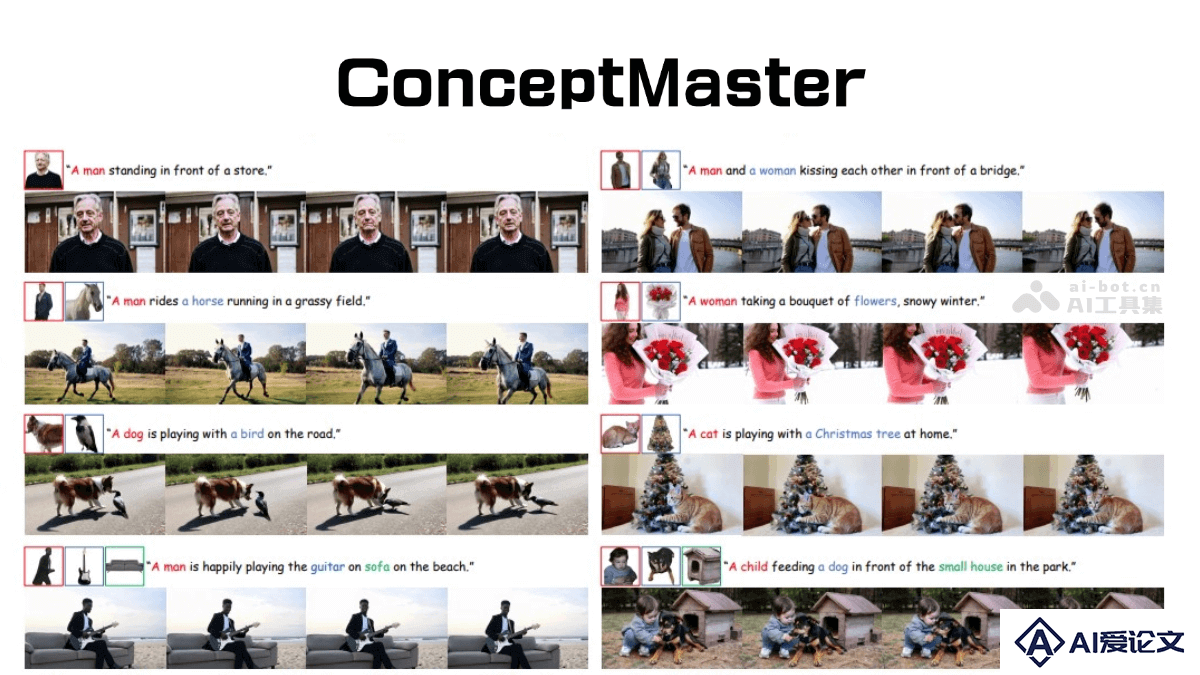
- ConceptMaster – 高保真多概念视频定制生成的创新 AI 框架 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 MarsX
查看
MarsX
查看
-
 Fronty
查看
Fronty
查看
-
 Locofy
查看
Locofy
查看
-
 Codiga
查看
Codiga
查看
-
 Ghostwriter
查看
Ghostwriter
查看
-
 Deco
查看
Deco
查看
 Fronty
查看
Fronty
查看
 Locofy
查看
Locofy
查看
 Codiga
查看
Codiga
查看
 Ghostwriter
查看
Ghostwriter
查看
 Deco
查看
热门推荐
更多+
Deco
查看
热门推荐
更多+


- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高





