
 简介
相关资讯
更多+
简介
相关资讯
更多+
-
 Qwen2vl-Flux – 开源的多模态图像生成模型,支持多种生成模式
Qwen2vl-Flux – 开源的多模态图像生成模型,支持多种生成模式Qwen2VL-Flux是多模态图像生成模型,结合Qwen2VL的视觉语言理解和FLUX框架,基于文本提示和图像参考生成高质量的图像。模型支持多种生成模式,包括变体生成、图像到图像转换、智能修复及ControlNet引导生成,具备深度估计和线条检测功能,实现更精确的图像控制。
AI教程资讯
 2025-01-31
2025-01-31
-
 ShowUI – 新加坡国立联合微软推出用于 GUI 自动化的视觉-语言-操作模型
ShowUI – 新加坡国立联合微软推出用于 GUI 自动化的视觉-语言-操作模型ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。
AI教程资讯
2025-01-31
-
 NVLM – 英伟达推出的多模态大型语言模型
NVLM – 英伟达推出的多模态大型语言模型NVLM是NVIDIA推出的前沿多模态大型语言模型(LLMs),在视觉-语言任务上达到与顶尖专有模型(如GPT-4o)和开放访问模型(如Llama 3-V 405B和InternVL 2)相匹敌的性能。NVLM 1 0家族包括三种架构:仅解码器模型NVLM-D、基于交叉注意力的模型NVLM-X和混合架构NVLM-H。
AI教程资讯
2025-01-31
-
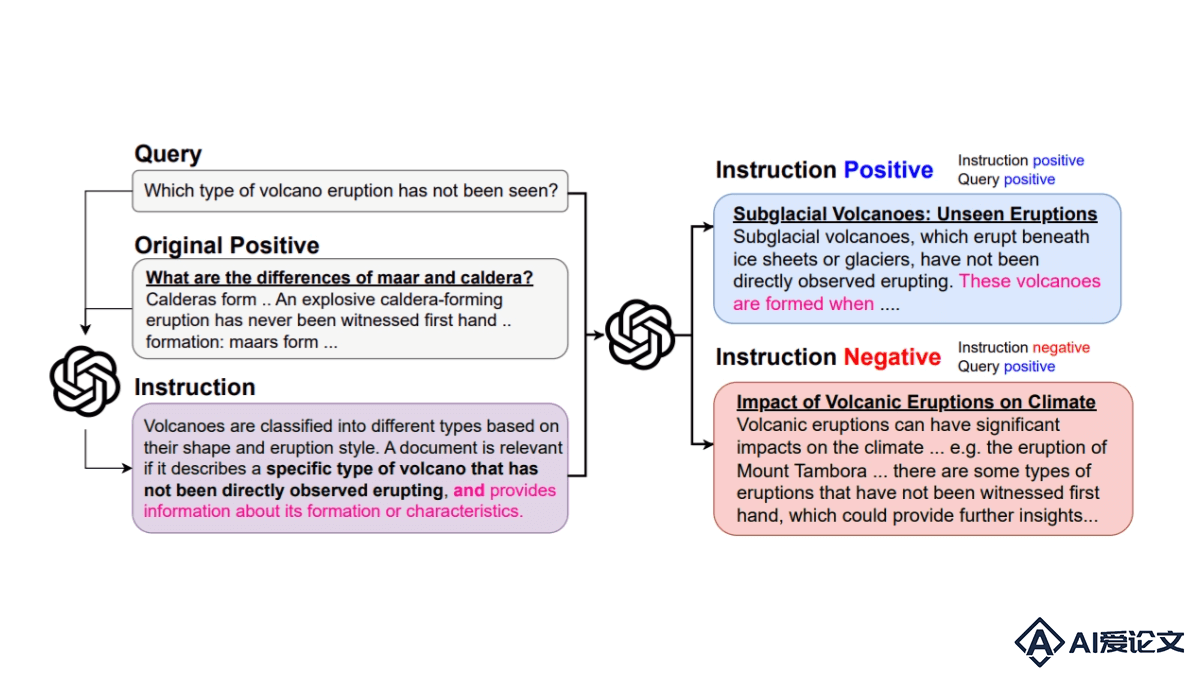 Promptriever – 信息检索模型,支持自然语言提示响应用户搜索需求
Promptriever – 信息检索模型,支持自然语言提示响应用户搜索需求Promptriever 是约翰斯·霍普金斯大学和Samaya AI联合推出的新型检索模型,能像语言模型一样接受自然语言提示,用直观的方式响应用户的搜索需求。Promptriever 基于 MS MARCO 数据集的指令训练集进行训练,不仅在标准检索任务上表现出色,还能更有效地遵循详细指令,提高对查询的鲁棒性和检索性能。
AI教程资讯
2025-01-31



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Typecast
查看
Typecast
查看
-
 Boomy
查看
Boomy
查看
-
 Soundraw
查看
Soundraw
查看
-
 Lemonaid
查看
Lemonaid
查看
-
 Murf AI
查看
Murf AI
查看
-
 Play.ht
查看
Play.ht
查看
 Boomy
查看
Boomy
查看
 Soundraw
查看
Soundraw
查看
 Lemonaid
查看
Lemonaid
查看
 Murf AI
查看
Murf AI
查看
 Play.ht
查看
热门推荐
更多+
Play.ht
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高





