
 简介
简介
Audiobox是Meta于2023年11月30日推出的免费开源的AI语音和声音生成模型,12月11日上线在线网页版本,用户可免费体验该模型的能力。Audiobox是Meta继Voicebox后推出的最新一代的音频生成模型,可以结合使用语音输入和自然语言文本提示来生成语音和音效,从而可以轻松地为各种用例创建逼真的自定义音频。

Audiobox的主要功能
克隆用户声音:录制声音按照用户的声音风格或以任意音频样本的风格生成语音文本描述生成人声:使用文本描述声音风格的特征以及声学环境生成人声更改声音风格:可结合声音和文本描述更改现有的声音风格本文描述生成音效:根据输入的声音特征文本描述生成声音效果噪音消除:提供Magic Eraser功能消除录音中的瞬态噪声声音填充:根据文本描述用新的声音替换音频中的一部分音频故事制作器:结合以上功能,利用Audiobox Maker制作原创有趣的音频故事相关资讯
更多+
-
 Micro LLAMA – 教学版 LLAMA 3模型实现,用于学习大模型的核心原理
Micro LLAMA – 教学版 LLAMA 3模型实现,用于学习大模型的核心原理Micro LLAMA是精简的教学版LLAMA 3模型实现,能帮助学习者理解大型语言模型架构。整个项目仅约180行代码,便于理解和学习。Micro LLAMA用的是LLAMA 3中最小的8B参数模型,模型本身需15GB存储空间,运行时约需30GB内存。
AI教程资讯
 2025-01-28
2025-01-28
-
 GenCast – 谷歌DeepMind推出的AI气象预测模型
GenCast – 谷歌DeepMind推出的AI气象预测模型GenCast是DeepMind推出的革命性AI气象预测模型,基于扩散模型技术,提供长达15天的全球天气预报。GenCast在97 2%的预测任务中超越全球顶尖的中期天气预报系统ENS,尤其在极端天气事件的预测上表现突出。与传统模型相比,GenCast能在8分钟内生成预报,显著提高预测效率。
AI教程资讯
2025-01-28
-
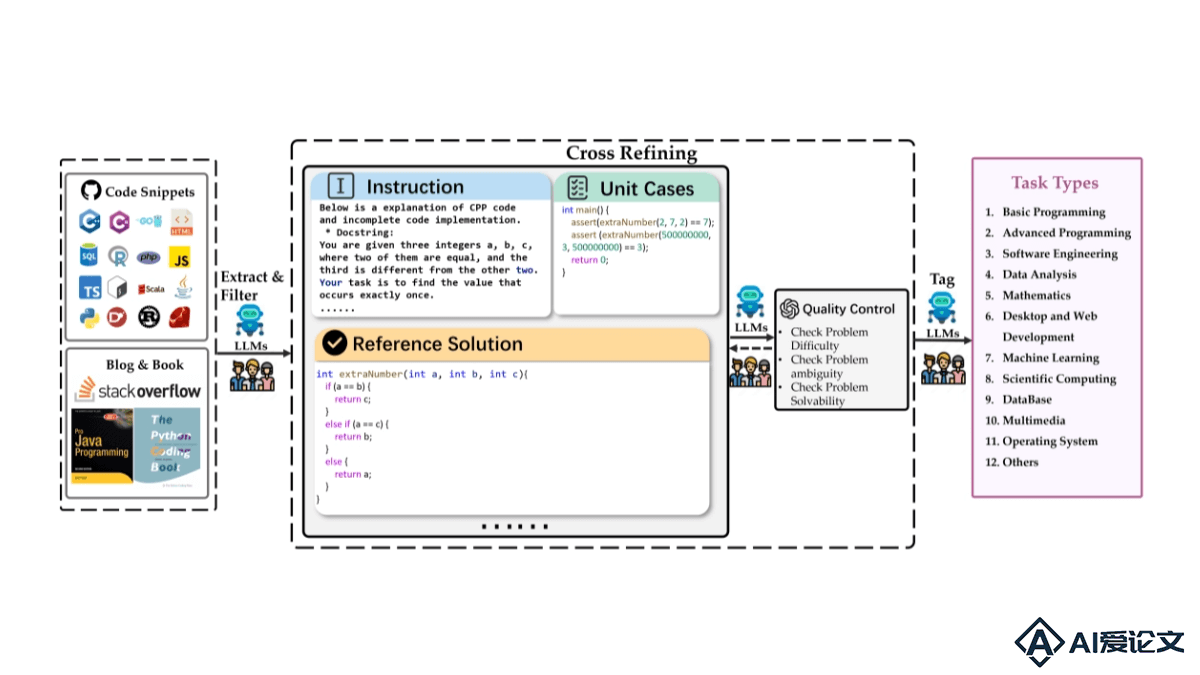 FullStack Bench – 字节豆包联合M-A-P社区开源的全新代码评估基准
FullStack Bench – 字节豆包联合M-A-P社区开源的全新代码评估基准FullStack Bench是字节跳动豆包大模型团队与M-A-P社区联合推出的全新代码评估基准,专注于全栈编程和多语言编程能力评估。FullStack Bench覆盖超过11种真实编程场景,包含3374个问题,涉及16种编程语言,能更有效地衡量大模型在现实世界中的代码开发能力。
AI教程资讯
2025-01-28
-
 Motion Prompting – 谷歌联合密歇根和布朗大学推出的运动轨迹控制视频生成模型
Motion Prompting – 谷歌联合密歇根和布朗大学推出的运动轨迹控制视频生成模型Motion Prompting是 Google DeepMind、密歇根大学和布朗大学联合推出的视频生成技术,基于运动轨迹(motion trajectories)控制和引导视频内容的生成。Motion Prompting用点轨迹作为灵活的运动表示,能编码从单个点到全局场景的任意复杂度的运动。用户能设计“运动提示”(motion prompts),类似于文本提示,激发视频模型的不同能力,包括对象控制、相机控制、物理现象模拟等。
AI教程资讯
2025-01-28



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Audiobox
查看
Audiobox
查看
-
 Deepgram
查看
Deepgram
查看
-
 蓝藻AI
查看
蓝藻AI
查看
-
 ACE Studio
查看
ACE Studio
查看
-
 OptimizerAI
查看
OptimizerAI
查看
-
 Voicenotes
查看
Voicenotes
查看
 Deepgram
查看
Deepgram
查看
 蓝藻AI
查看
蓝藻AI
查看
 ACE Studio
查看
ACE Studio
查看
 OptimizerAI
查看
OptimizerAI
查看
 Voicenotes
查看
热门推荐
更多+
Voicenotes
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高





