
 简介
简介
Reecho睿声是什么
Reecho睿声是一个超拟真瞬时人工智能语音克隆平台,利用先进的AI语音技术,允许用户通过上传或录制一段音频样本,来创建并克隆特定的声音角色。该平台的特点是能够快速地从较短的音频样本中克隆声音,而不需要长时间的训练过程。Reecho睿声基于中文领域领先的SOTA语音大模型技术,可一定程度上理解文本上下文,并以与真人几乎无异的表现力、情感、韵律和音色来基于文本生成人声音频,并且支持以5秒极短样本进行瞬时语音克隆。

Reecho睿声的主要功能
超拟真语音克隆:用户可以通过上传或录制一段音频样本,快速克隆特定的声音。这个过程中,AI会学习样本的声音特征,以便生成与原声音相似的新声音。角色管理:用户可以在平台上创建和管理多个声音角色。每个角色都可以有自己的声音样本和属性,方便用户根据不同的需求选择和使用。语音合成:Reecho睿声允许用户将克隆的声音角色分配给不同的文本,AI会使用这些角色的声音来朗读文本,生成语音输出。语音文本内容编辑:用户可以编辑要合成语音的文本内容,包括文本的修改、格式调整等,以确保生成的语音符合预期。声音社区市场:Reecho睿声还提供了一个声音分享社区,用户可以在这里找到预置的声音角色,或者将自己创建的声音角色分享给其他用户。如何使用Reecho睿声
访问Reecho睿声的官网(reecho.ai),点击右上角登录/注册按钮登录成功后跳转到后台选择开启声音之旅点击快速创建新角色,输入角色名称和添加音频样本角色创建后,在文本输入框中分配角色,然后输入任意文本点击添加段落,系统将会自动对文本进行按句拆分,你也可以手动编辑完成内容编辑后,在右侧进行设置调整,最后点击开始生成即可Reecho睿声的产品价格
免费版:新用户注册后即可获得免费的1500点数,每日签到可获得699点数,QQ群签到可获得299点数,无限角色数量付费点数购买:14.99元可购买30000点数、24.99元可获得53000点数、49.99元可获得120000点数、99.99元可获得260000点数,付费后可享受无限角色数量、点数永不过期、API访问权限和专享加速生成通道等权益
Reecho睿声的应用场景
有声读物和播客:内容创作者可以利用Reecho睿声为电子书、有声书籍或播客节目生成个性化的朗读声音,吸引听众并提供更丰富的听觉体验。游戏和娱乐产业:游戏开发者可以为游戏角色定制独特的声音,或者为动画、电影、广告等娱乐内容创造逼真的配音。广播和电台:广播电台可以使用Reecho睿声生成特定风格或名人的声音,用于节目制作,增加节目的吸引力。虚拟主播和Vtuber:视频内容创作者可以创建虚拟主播,使用Reecho睿声为虚拟形象提供声音,进行直播或制作视频内容。相关资讯
更多+
-
 POINTS 1.5 – 腾讯微信推出的多模态大模型
POINTS 1.5 – 腾讯微信推出的多模态大模型POINTS 1 5 是腾讯微信发布的多模态大模型,是POINTS 1 0的升级版本。 模型继续沿用了POINTS 1 0中的LLaVA架构,由一个视觉编码器、一个投影器和一个大型语言模型组成。 POINTS 1 5在效率和性能上都进行了增强,特别是在全球10B以下开源模型的排名中,POINTS 1 5-7B位居榜首,超越了其他业界领先的模型,如Qwen2-VL、InternVL2和MiniCPM-V-2 5等。
AI教程资讯
 2025-01-24
2025-01-24
-
 k1 视觉思考模型 – kimi推出的 k1 系列强化学习模型
k1 视觉思考模型 – kimi推出的 k1 系列强化学习模型k1 视觉思考模型是kimi推出的k1系列强化学习AI模型,原生支持端到端图像理解和思维链技术,将能力扩展到数学之外的更多基础科学领域。k1模型在图像理解、数学、物理、化学等学科的基准测试中表现优异,超过全球多个标杆模型(如OpenAI o1、GPT-4o以及 Claude 3 5 Sonnet)。k1 视觉思考模型能直接处理图像信息进行思考得出答案,无需借助外部OCR或视觉模型,提供完整的推理思维链,让用户看到模型思索答案的全过程。
AI教程资讯
2025-01-24
-
 FreeScale – 无需微调的推理框架,提升扩散模型生成能力首次实现8K分辨率图像
FreeScale – 无需微调的推理框架,提升扩散模型生成能力首次实现8K分辨率图像FreeScale是南洋理工大学、阿里巴巴集团和复旦大学推出无需微调的推理框架,提升预训练扩散模型生成高分辨率图像和视频的能力。FreeScale基于处理和融合不同尺度的信息,有效解决模型在生成超训练分辨率内容时出现的高频信息增加导致的重复模式问题。
AI教程资讯
2025-01-24
-
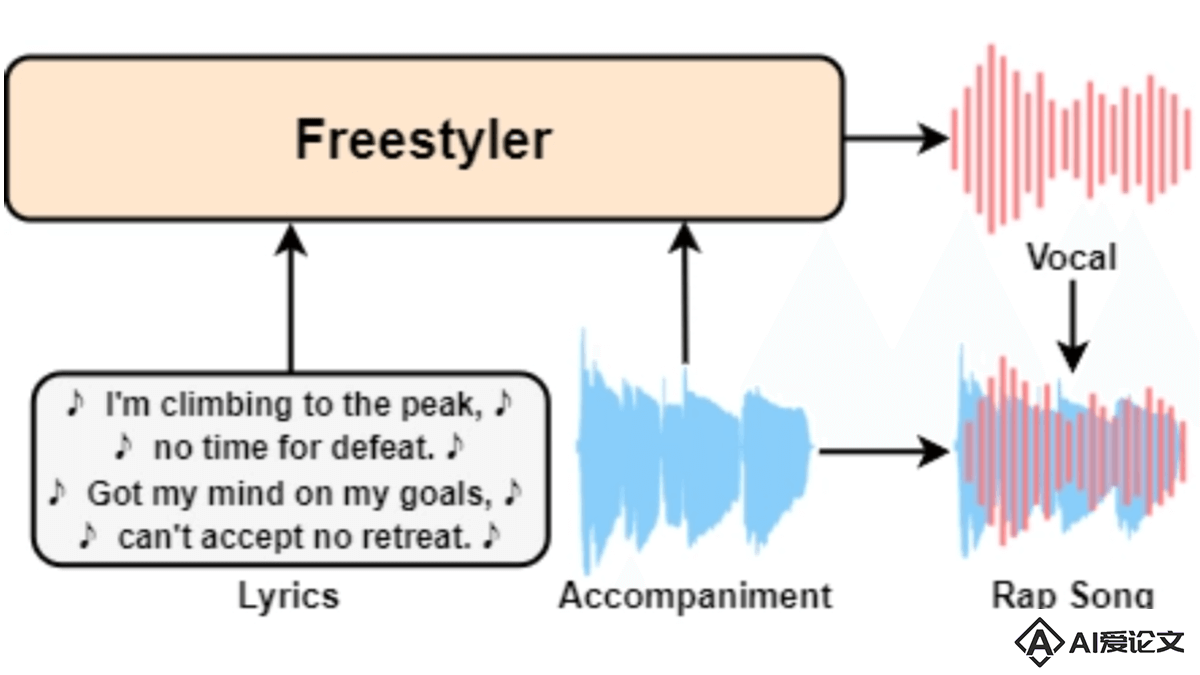 Freestyler – 西工大联合微软和香港大学推出的说唱乐生成模型
Freestyler – 西工大联合微软和香港大学推出的说唱乐生成模型Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。
AI教程资讯
2025-01-23



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Reecho睿声
查看
Reecho睿声
查看
-
 MemoAI
查看
MemoAI
查看
-
 讯飞听见
查看
讯飞听见
查看
-
 简单听记
查看
简单听记
查看
-
 音剪
查看
音剪
查看
-
 琅琅配音
查看
琅琅配音
查看
 MemoAI
查看
MemoAI
查看
 讯飞听见
查看
讯飞听见
查看
 简单听记
查看
简单听记
查看
 音剪
查看
音剪
查看
 琅琅配音
查看
热门推荐
更多+
琅琅配音
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高





