
 简介
简介
Hoarder是一款开源的AI驱动的自托管书签管理工具,专为数据/知识收藏者设计,集成了人工智能技术,可帮助用户快速收集、管理链接、笔记和图片。该AI书签管理工具提供全文搜索、AI自动打标签功能,支持跨平台使用,包括浏览器扩展和移动应用。Hoarder适合需要高效信息管理的用户,无论是学术研究、日常笔记还是专业资料整理,都能提供强大支持。

Hoarder的主要功能
书签链接管理:用户可以轻松添加和管理网页链接,Hoarder支持一键保存,让信息收集变得简单快捷。笔记与记录:Hoarder允许用户撰写并存储笔记,无论是灵感闪现还是重要信息,都能得到妥善记录。图片存储功能:用户可以上传和保存图片,使得视觉信息也能被有效管理和回顾。自动信息提取:Hoarder能够自动获取并填充链接的标题、描述和图片,减轻用户手动输入的负担。智能分类系统:用户可以根据个人喜好和需求,创建不同的分类列表,实现信息的有序管理。全文内容搜索:Hoarder提供全文搜索功能,无论信息存储多久,都能快速定位和检索。AI自动标签:利用人工智能技术,Hoarder能够自动识别内容并生成标签,极大提升了信息的可检索性和管理效率。支持自托管:通过自托管,用户可以在自己的服务器上部署Hoarder,确保数据的安全性和自主性。如何使用Hoarder
Hoarder提供自托管,并提供Chrome和Firefox浏览器扩展,方便用户在浏览网页时快速保存书签。此外,还支持Android和iOS移动端应用。技术人员可以查看GitHub代码库自行部署,普通用户可以下载安装相应平台的应用和扩展进行使用。
GitHub源码库:https://github.com/hoarder-app/hoarderChrome浏览器扩展:https://chromewebstore.google.com/detail/hoarder/kgcjekpmcjjogibpjebkhaanilehneje?hl=zhFirefox火狐浏览器扩展:https://addons.mozilla.org/zh-CN/firefox/addon/hoarder/iOS应用(苹果App Store):https://apps.apple.com/cn/app/hoarder-app/id6479258022Android应用(Google Play):https://play.google.com/store/apps/details?id=app.hoarder.hoardermobileHoarder的应用场景
个人知识管理:用户可以利用Hoarder收集感兴趣的文章、博客、教程等,构建个人的知识库。学术研究:学者和研究人员可以保存学术论文、研究资料,并通过AI标签快速检索相关文献。项目文档管理:项目经理和团队成员可以使用Hoarder来保存项目相关的文档、链接和参考资料。日常笔记记录:学生和专业人士可以用Hoarder来记录会议要点、学习笔记和日常想法。灵感收集:设计师、作家和创意工作者可以收集灵感素材,如设计作品、写作素材等。技术资料整理:开发者和IT专业人员可以保存技术博客、开发文档、编程教程等。相关资讯
更多+
-
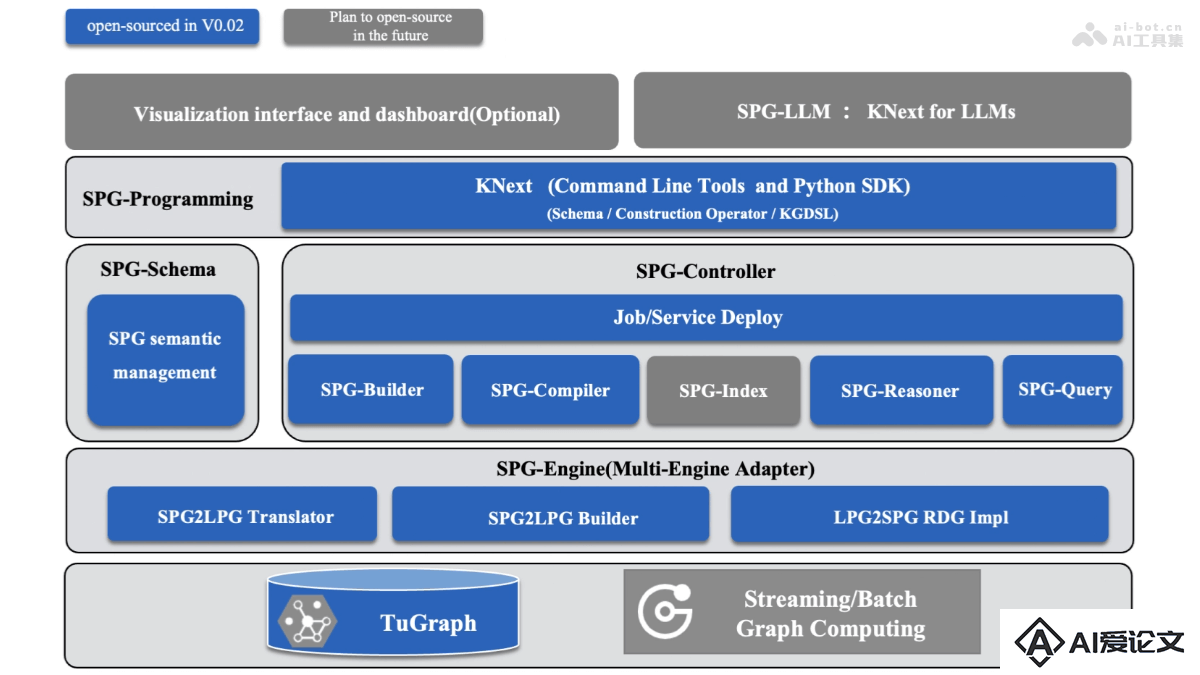 OpenSPG – 蚂蚁联合OpenKG开源的知识图谱引擎
OpenSPG – 蚂蚁联合OpenKG开源的知识图谱引擎OpenSPG是蚂蚁集团联合OpenKG社区推出的基于SPG框架的知识图谱引擎。OpenSPG融合LPG的结构性和RDF的语义性,克服RDF OWL语义复杂难以落地的问题,继承LPG结构简单与大数据体系兼容的优势。
AI教程资讯
 2025-02-14
2025-02-14
-
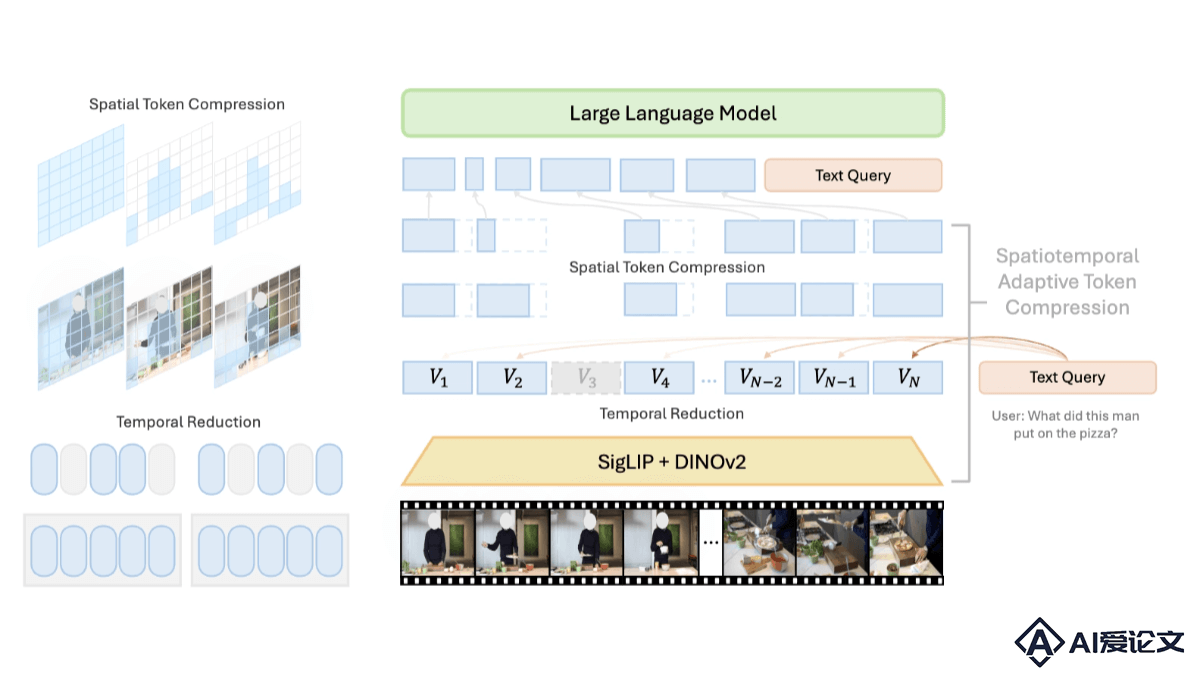 LongVU – Meta AI开源的长视频理解模型
LongVU – Meta AI开源的长视频理解模型LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节
AI教程资讯
2025-02-13
-
 SynthID Text – 谷歌DeepMind推出的AI生成文本水印技术
SynthID Text – 谷歌DeepMind推出的AI生成文本水印技术SynthID Text 是谷歌DeepMind 推出的文本水印技术,用在识别和验证由大型语言模型(LLM)生成的文本。基于细微调整生成过程中的Token概率分数嵌入几乎无法察觉的水印,在不影响文本质量和用户体验的情况下,实现高检测精度。
AI教程资讯
2025-02-13
-
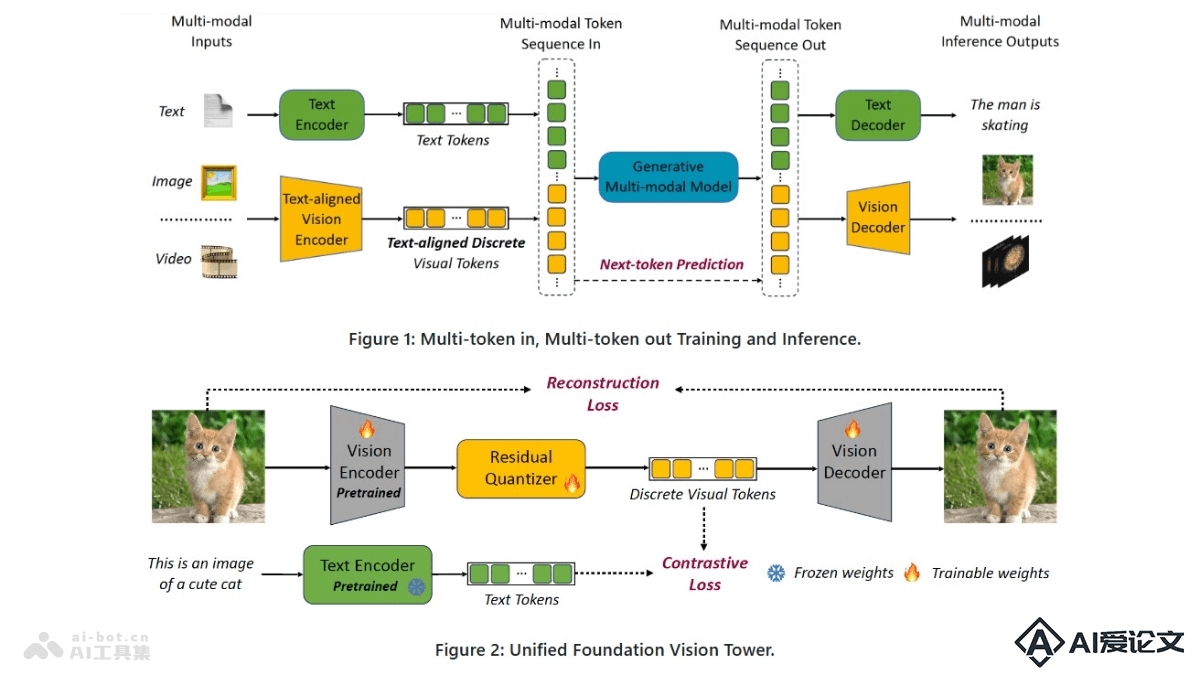 VILA-U – 融合多模态理解和生成的统一基础模型
VILA-U – 融合多模态理解和生成的统一基础模型VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。
AI教程资讯
2025-02-13



 最新录入
更多+
最新录入
更多+

 查看
查看




 同类别攻略
更多+
同类别攻略
更多+
- AnimePro FLUX – 动漫风格图像生成模型,基于Flux.1 Shnell模型微调 2025-02-10
- HK-O1aw – HKGAI团队联合北大团队推出的慢思考范式法律推理大模型 2025-02-10
- SeedEdit – 字节豆包团队推出的AI图像编辑模型 2025-02-10
- DimensionX – 港科大、清华和生数科技共同推出的单图像生成复杂3D、4D场景框架 2025-02-10
- App Intents – 苹果推出的集成Siri和Apple Intelligence新框架 2025-02-10
- HourVideo – 李飞飞和吴佳俊团队推出的长视频理解基准数据集 2025-02-10
 同类别推荐
更多+
同类别推荐
更多+
-
 Hoarder
查看
Hoarder
查看
-
 苏打办公
查看
苏打办公
查看
-
 云一朵
查看
云一朵
查看
-
 奇觅
查看
奇觅
查看
-
 Glif
查看
Glif
查看
-
 WPS灵犀
查看
WPS灵犀
查看
 苏打办公
查看
苏打办公
查看
 云一朵
查看
云一朵
查看
 奇觅
查看
奇觅
查看
 Glif
查看
Glif
查看
 WPS灵犀
查看
热门推荐
更多+
WPS灵犀
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

星火文档问答是科大讯飞推出的基于讯飞星火认知大模型的AI文档问答和知识库方案,提供Al分析、阅读、问答工具,可帮助用户高效检索文档信息,准确回答专业问题,让大模型助你高效解读文档内容。
-
2
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高



