
 简介
简介
Quivr是什么?
Quivr AI 是一个开源的本地知识库搭建解决方案,旨在利用大模型和生成式AI帮助用户存储和检索非结构化信息,构建用户知识的“第二大脑”。该工具允许用户上传各种类型的文件,如文本、Markdown、PDF、音频和视频,并将这些文件向量化后存储在云端。用户可以通过自然语言对话的方式向 Quivr 提问,以获取与上传文件相关的信息。

Quivr的主要功能
文件上传与存储:用户可以将各种类型的文件上传到Quivr,包括文本文件、Markdown、PDF、音频和视频等。这些文件会被向量化处理,以便后续的检索和分析。自然语言问答:Quivr 支持自然语言处理(NLP),用户可以直接用自然语言向Quivr提问,AI会根据上传的文件内容生成回答。信息检索:Quivr 能够理解和检索上传文件中的信息,帮助用户快速找到所需数据,无需手动搜索或翻阅大量文档。集成与API:Quivr 提供了API接口,允许第三方应用和服务与Quivr集成,从而扩展其功能和应用场景。多模型支持:Quivr 支持与OpenAI的GPT-3/4、Anthropic的Claude模型集成,以及通过Ollama连接开源的大型语言模型,以提供准确的问答服务。开源与本地部署:作为一个开源项目,Quivr 的源代码可以在GitHub上找到,用户可以选择在本地部署Quivr,以更好地控制数据的隐私和安全性。数据安全与隐私:Quivr 强调用户数据的安全,确保上传的数据不会被用于训练AI模型,除非用户明确同意。此外,Quivr 提供了数据加密和安全存储的措施。历史记录与分析:Quivr 保存了用户的提问和AI的回答历史,用户可以回顾和分析这些对话,以便进一步挖掘知识库中的信息。
如何使用Quivr AI
一、使用在线托管版
访问Quivr的官网(quivr.app),点击Try free demo进行注册登录选择Add Brain添加“大脑”(即知识库),选择大脑类型(文档或App)设置大脑名字和描述,然后上传文件或添加网页URL然后在搜索界面输入相关问题即可与你构建好的大脑进行对话检索二、本地部署开源版
访问Quivr的GitHub开源代码库https://github.com/StanGirard/quivr,根据说明步骤设置Supabase并使用Docker部署即可Quivr AI的产品价格
开源版:免费开源版本,用户可自行本地或云端部署GitHub中提供的代码在线版:免费版:3个知识库,每月100个问题、30Mb存储空间Hobby版:9美元每月,构建12个知识库、每月1000个问题、600Mb存储空间Plus版本:29美元每月,构建20个知识库、每月4000个问题、1GB存储空间、GPT-4模型Pro版本:99美元每月,构建40个知识库、每月10000个问题、2GB存储空间、GPT-4模型 相关资讯
更多+
相关资讯
更多+
-
 LaTRO – 基于自我奖励提升LLMs复杂推理能力的框架
LaTRO – 基于自我奖励提升LLMs复杂推理能力的框架LaTRO(Latent Reasoning Optimization)是先进的框架,提升大型语言模型(LLMs)在复杂推理任务中的表现。基于将推理过程类比为从潜在分布中采样,用变分推断方法进行优化,LaTRO让模型自我改进,增强生成和评估推理路径的能力。
AI教程资讯
 2025-02-05
2025-02-05
-
 ReCapture – 谷歌和新加坡国立大学共同推出的视频处理技术
ReCapture – 谷歌和新加坡国立大学共同推出的视频处理技术ReCapture是谷歌和新加坡国立大学推出的视频处理技术,能从单一用户提供的视频中生成具有新相机轨迹的新视频。ReCapture用多视图扩散模型或基于深度的点云渲染生成带有新相机轨迹的噪声锚视频,采用掩码视频微调技术,将锚视频转换成干净、时间一致的重新角度化视频,保留原始视频中的场景运动,从新角度展现场景。
AI教程资讯
2025-02-05
-
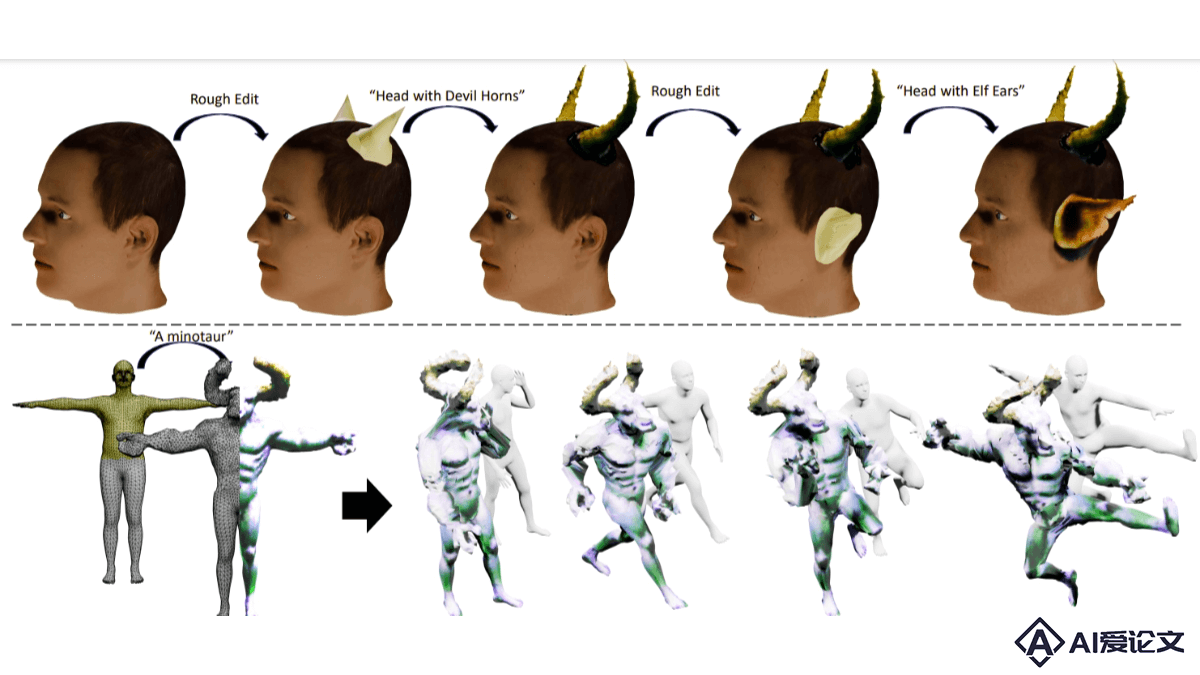 MagicClay – Adobe 推出的3D建模工具,文本引导3D模型局部雕刻
MagicClay – Adobe 推出的3D建模工具,文本引导3D模型局部雕刻MagicClay 是 Adobe 推出3D建模工具,结合网格和有向距离场(SDF)技术,支持艺术家基于文本提示对3D模型的特定部分进行雕刻,同时保持模型的其他区域不变。MagicClay 支持生成具有纹理的三维模型,能非破坏性地编辑局部网格,让艺术家用文本提示为基础,对3D模型进行更直观和更精细的编辑。
AI教程资讯
2025-02-05
-
 StableV2V – 中国科技大学开源的视频编辑项目
StableV2V – 中国科技大学开源的视频编辑项目StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。
AI教程资讯
2025-02-05



 最新录入
更多+
最新录入
更多+

 查看
查看



 同类别攻略
更多+
同类别攻略
更多+
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 2025-01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 2025-01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 2025-01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 2025-01-20
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 2025-01-13
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 2025-01-13
 同类别推荐
更多+
同类别推荐
更多+
-
 Quivr
查看
Quivr
查看
-
 Cubox
查看
Cubox
查看
-
 腾讯文档智能助手
查看
腾讯文档智能助手
查看
-
 WPS AI
查看
WPS AI
查看
-
 Acrobat AI Assistant
查看
Acrobat AI Assistant
查看
-
 万知
查看
万知
查看
 Cubox
查看
Cubox
查看
 腾讯文档智能助手
查看
腾讯文档智能助手
查看
 WPS AI
查看
WPS AI
查看
 Acrobat AI Assistant
查看
Acrobat AI Assistant
查看
 万知
查看
热门推荐
更多+
万知
查看
热门推荐
更多+




- SPAR3D – Stability AI等机构推出的单试图重建 3D 网络模型 01-13
- 星火纪要 – 科大讯飞推出的会议交流总结和分析平台 01-13
- Agent Laboratory – AMD 联合约翰·霍普金斯大学推出的自主科研 Agent 01-13
- 日日新融合大模型 – 商汤科技推出的原生融合模态大模型 01-13
- LatentSync – 字节联合北交大开源的端到端唇形同步框架 01-15
- Diff-Instruct – 从预训练扩散模型中迁移知识的通用框架 01-20
- Search-o1 – 人大联合清华推出自主知识检索增强的推理框架 01-13
- rStar-Math – 微软推出的小模型复杂推理与自进化SLMs的创新技术 01-13
- Mobile-Agent – 自主多模态移动设备代理,通过视觉感知实现智能化手机操作 01-14
- CHRONOS – 阿里通义联合上海交大等推出时间线摘要生成新框架 01-14
大家都在用
更多+

-
1

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
2
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
3

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
4

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
5
2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高
-
6

2025顶尖智能网页抓取工具排名-2025哪款网页抓取器效率最高


