Sonic是什么
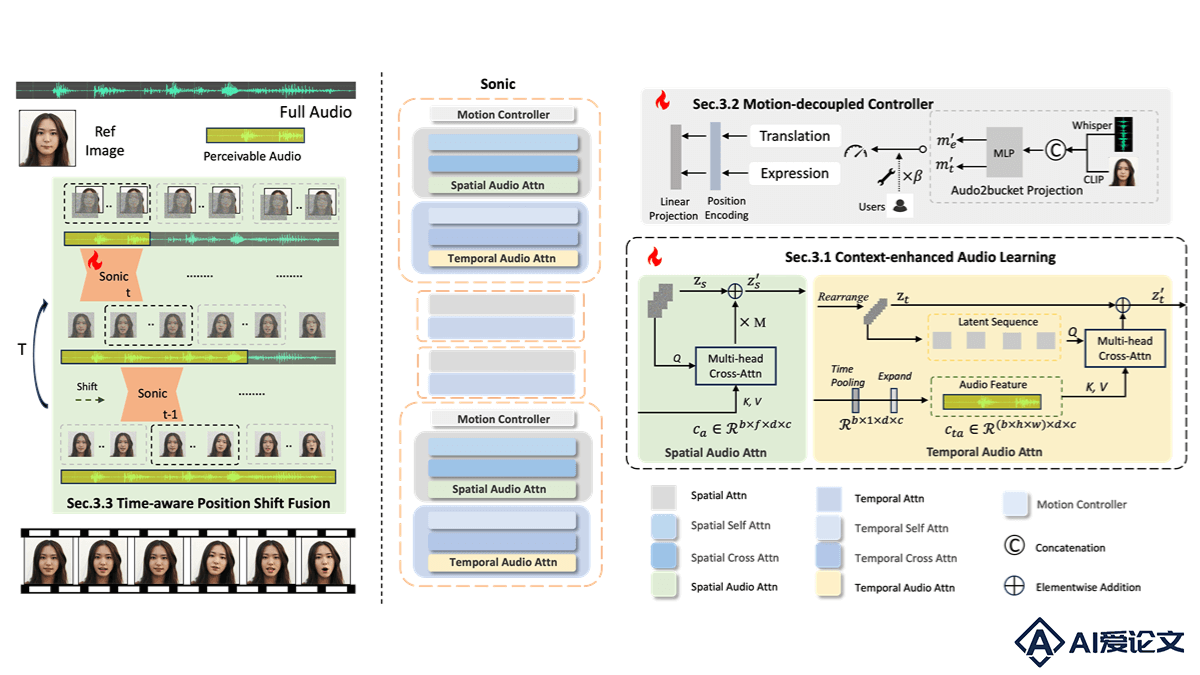
Sonic是腾讯和浙江大学推出的音频驱动肖像动画框架,基于全局音频感知生成逼真的面部表情和动作。Sonic基于上下文增强音频学习和运动解耦控制器,分别提取音频片段内的长期时间音频知识和独立控制头部与表情运动,增强局部音频感知能力。Sonic用时间感知位置偏移融合机制,将局部音频感知扩展到全局,解决长视频生成中的抖动和突变问题。Sonic在视频质量、唇部同步精度、运动多样性和时间连贯性方面优于现有的最先进方法,显著提升肖像动画的自然性和连贯性,支持用户对动画的精细调整。
来源:爱论文 时间:2025-03-21 14:34:02
Sonic是腾讯和浙江大学推出的音频驱动肖像动画框架,基于全局音频感知生成逼真的面部表情和动作。Sonic基于上下文增强音频学习和运动解耦控制器,分别提取音频片段内的长期时间音频知识和独立控制头部与表情运动,增强局部音频感知能力。Sonic用时间感知位置偏移融合机制,将局部音频感知扩展到全局,解决长视频生成中的抖动和突变问题。Sonic在视频质量、唇部同步精度、运动多样性和时间连贯性方面优于现有的最先进方法,显著提升肖像动画的自然性和连贯性,支持用户对动画的精细调整。
 相关资讯
更多+
相关资讯
更多+
Sonic是腾讯和浙江大学推出的音频驱动肖像动画框架,基于全局音频感知生成逼真的面部表情和动作。Sonic基于上下文增强音频学习和运动解耦控制器,分别提取音频片段内的长期时间音频知识和独立控制头部与表情运动,增强局部音频感知能力。
AI教程资讯
 2023-04-14
2023-04-14

FireRedASR 是小红书开源的工业级自动语音识别(ASR)模型家族,支持普通话、中文方言和英语,在普通话 ASR 基准测试中达到了新的最佳水平(SOTA),在歌词识别方面表现出色。
AI教程资讯
2023-04-14

MVoT(Multimodal Visualization-of-Thought)是微软研究院、剑桥大学语言技术实验室、中国科学院自动化研究所推出的新型多模态推理范式,基于生成图像可视化推理痕迹增强多模态大语言模型(MLLMs)在复杂空间推理任务中的表现。
AI教程资讯
2023-04-14

DynVFX是创新的视频增强技术,能根据简单的文本指令将动态内容无缝集成到真实视频中。通过结合预训练的文本到视频扩散模型和视觉语言模型(VLM),实现了在不依赖复杂用户输入的情况下,自然地将新动态元素与原始视频场景融合。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














