FlashVideo是什么
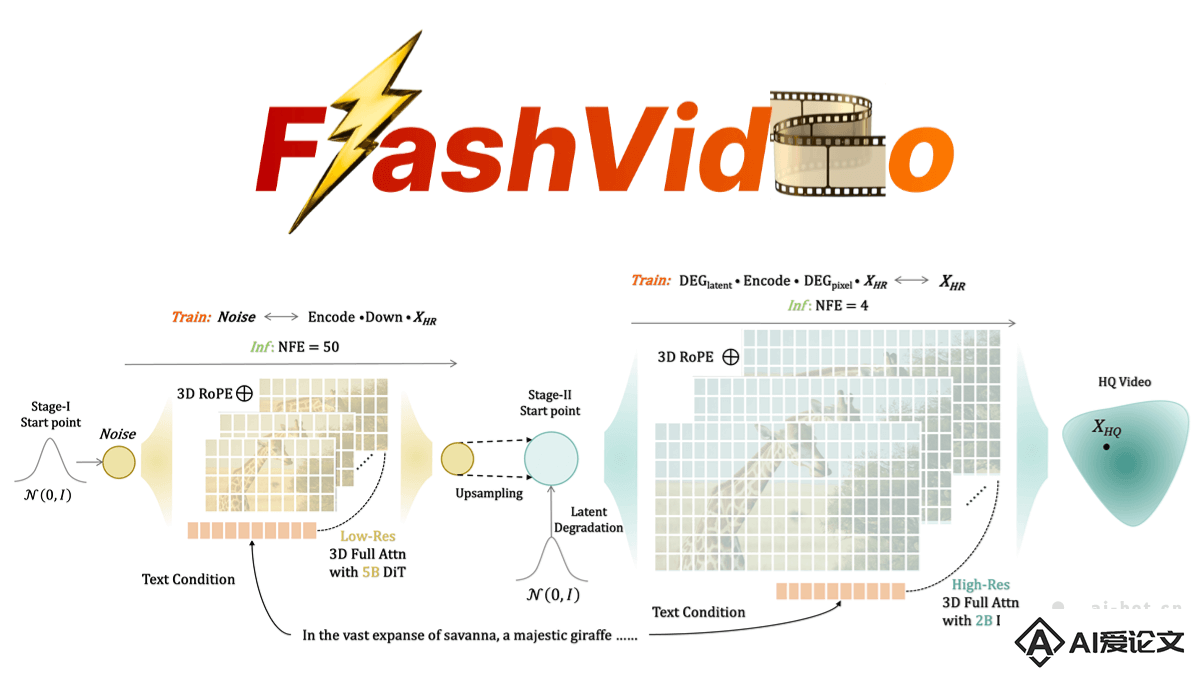
FlashVideo是字节跳动团队提出的高效的高分辨率视频生成框架,通过两阶段方法解决了传统单阶段扩散模型在高分辨率视频生成中面临的巨大计算成本问题。在第一阶段,FlashVideo 使用 50 亿参数的大型模型在低分辨率(270p)下生成与文本提示高度一致的内容和运动,基于参数高效微调(PEFT)技术确保计算效率。第二阶段通过流匹配技术,将低分辨率视频映射到高分辨率(1080p),仅需 4 次函数评估可生成细节丰富的高质量视频。
来源:爱论文 时间:2025-03-21 09:37:04
FlashVideo是字节跳动团队提出的高效的高分辨率视频生成框架,通过两阶段方法解决了传统单阶段扩散模型在高分辨率视频生成中面临的巨大计算成本问题。在第一阶段,FlashVideo 使用 50 亿参数的大型模型在低分辨率(270p)下生成与文本提示高度一致的内容和运动,基于参数高效微调(PEFT)技术确保计算效率。第二阶段通过流匹配技术,将低分辨率视频映射到高分辨率(1080p),仅需 4 次函数评估可生成细节丰富的高质量视频。
 相关资讯
更多+
相关资讯
更多+
FlashVideo是字节跳动团队提出的高效的高分辨率视频生成框架,通过两阶段方法解决了传统单阶段扩散模型在高分辨率视频生成中面临的巨大计算成本问题。在第一阶段,FlashVideo 使用 50 亿参数的大型模型在低分辨率(270p)下生成与文本提示高度一致的内容和运动,基于参数高效微调(PEFT)技术确保计算效率。
AI教程资讯
 2023-04-14
2023-04-14

ACE++是阿里巴巴通义实验室推出的先进的图像生成与编辑工具,通过指令化和上下文感知的内容填充技术,实现了高质量的图像创作和编辑功能。
AI教程资讯
2023-04-14

LLaVA-Rad是微软研究院推出的小型多模态模型,专注于临床放射学报告生成。是LLaVA-Med项目的分支,特别是胸部X光(CXR)成像。基于LLaVA-Med的基础架构和训练方法,针对放射学领域的特定需求进行了优化。
AI教程资讯
2023-04-14
Satori 是 MIT、哈佛大学等机构研究者推出的 7B 参数的大型语言模型,专注于提升推理能力。基于Qwen-2 5-Math-7B,Satori通过小规模的格式微调和大规模的增强学习实现了最先进的推理性能。采用行动思维链(COAT)机制,通过强化学习优化模型性能,具备强大的自回归搜索和自我纠错能力。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载














