HUGWBC是什么
HUGWBC(Humanoid Unified and General Whole-Body Controller)是上海交通大学、上海AI Lab联合推出的人形机器人全身控制器,能实现精细的运动控制。HUGWBC基于扩展的命令空间和先进的训练技术,让机器人执行多种自然步态(如行走、跑步、跳跃、站立和单脚跳),支持实时外部上肢控制信号,实现复杂的运动操作任务。HUGWBC用强化学习在模拟环境中训练,用不对称训练框架(AAC)将策略直接迁移到真实机器人上。

来源:爱论文 时间:2025-03-20 15:12:02
HUGWBC(Humanoid Unified and General Whole-Body Controller)是上海交通大学、上海AI Lab联合推出的人形机器人全身控制器,能实现精细的运动控制。HUGWBC基于扩展的命令空间和先进的训练技术,让机器人执行多种自然步态(如行走、跑步、跳跃、站立和单脚跳),支持实时外部上肢控制信号,实现复杂的运动操作任务。HUGWBC用强化学习在模拟环境中训练,用不对称训练框架(AAC)将策略直接迁移到真实机器人上。
 相关资讯
更多+
相关资讯
更多+
HUGWBC(Humanoid Unified and General Whole-Body Controller)是上海交通大学、上海AI Lab联合推出的人形机器人全身控制器,能实现精细的运动控制。HUGWBC基于扩展的命令空间和先进的训练技术,让机器人执行多种自然步态(如行走、跑步、跳跃、站立和单脚跳),支持实时外部上肢控制信号,实现复杂的运动操作任务。
AI教程资讯
 2023-04-14
2023-04-14

TPO(Test-Time Preference Optimization)是新型的AI优化框架,在推理阶段对语言模型输出进行动态优化,更符合人类偏好。TPO通过将奖励信号转化为文本反馈,将模型生成的优质响应标记为“选择”输出,低质量响应标记为“拒绝”输出,进而生成“文本损失”并提出“文本梯度”,以此迭代改进模型输出,无需更新模型参数。
AI教程资讯
2023-04-14

PDF to Podcast是NVIDIA推出的PDF转音频的AI工具,基于NVIDIA NIM微服务架构的,能将PDF文档转换为生动的音频内容,如播客。基于大型语言模型(LLM)、文本到语音(TTS)技术以及NVIDIA的微服务,将PDF中的内容提取转换为Markdown格式,再生成自然流畅的对话或独白形式的音频。
AI教程资讯
2023-04-14
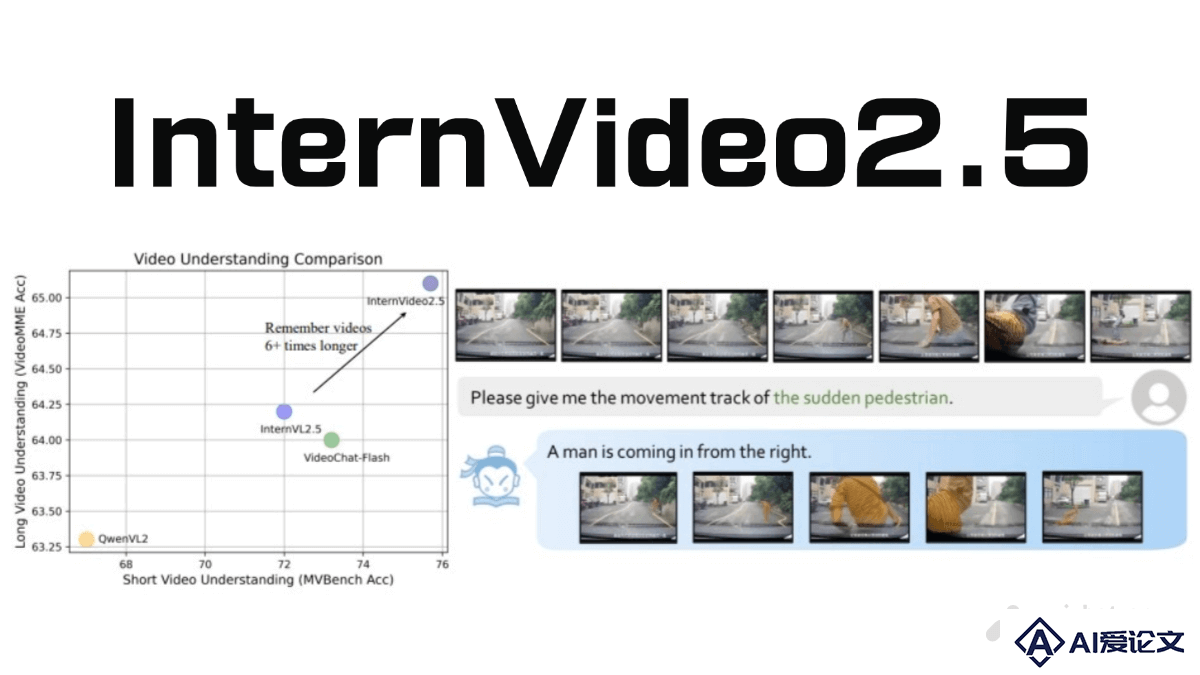
InternVideo2 5是上海人工智能实验室联合南京大学、中科院深圳先进技术研究院共同开源的视频多模态大模型。在视频理解领域取得了显著进展,特别是在长视频处理和细粒度时空感知方面表现出色。模型能处理长达万帧的视频,视频处理长度较前代提升了6倍,可在长视频中精准定位目标帧,实现“大海捞针”式的检索。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载















