InternVideo2.5是什么
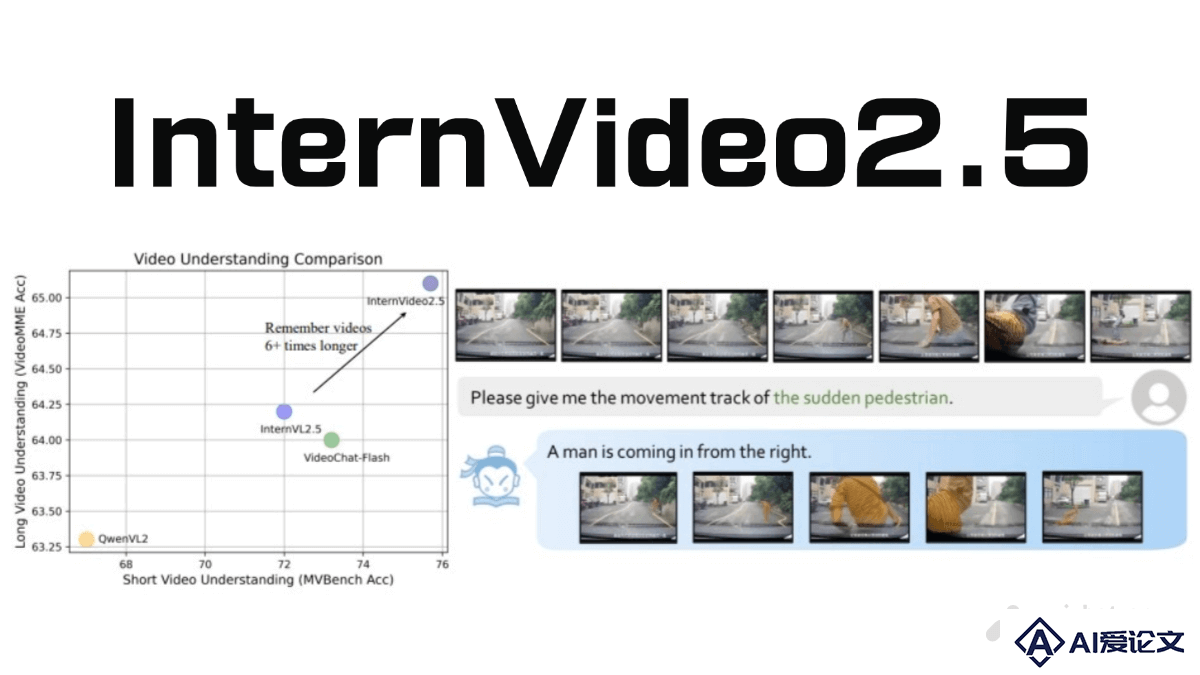
InternVideo2.5是上海人工智能实验室联合南京大学、中科院深圳先进技术研究院共同开源的视频多模态大模型。在视频理解领域取得了显著进展,特别是在长视频处理和细粒度时空感知方面表现出色。模型能处理长达万帧的视频,视频处理长度较前代提升了6倍,可在长视频中精准定位目标帧,实现“大海捞针”式的检索。支持通用视频问答,完成目标跟踪、分割等专业视觉任务。
来源:爱论文 时间:2025-03-20 14:00:26
InternVideo2.5是上海人工智能实验室联合南京大学、中科院深圳先进技术研究院共同开源的视频多模态大模型。在视频理解领域取得了显著进展,特别是在长视频处理和细粒度时空感知方面表现出色。模型能处理长达万帧的视频,视频处理长度较前代提升了6倍,可在长视频中精准定位目标帧,实现“大海捞针”式的检索。支持通用视频问答,完成目标跟踪、分割等专业视觉任务。
 相关资讯
更多+
相关资讯
更多+
InternVideo2 5是上海人工智能实验室联合南京大学、中科院深圳先进技术研究院共同开源的视频多模态大模型。在视频理解领域取得了显著进展,特别是在长视频处理和细粒度时空感知方面表现出色。模型能处理长达万帧的视频,视频处理长度较前代提升了6倍,可在长视频中精准定位目标帧,实现“大海捞针”式的检索。
AI教程资讯
 2023-04-14
2023-04-14

HumanDiT 是浙江大学和字节跳动联合提出的姿态引导的高保真人体视频生成框架。基于扩散变换器(Diffusion Transformer,DiT),能在大规模数据集上训练,生成具有精细身体渲染的长序列人体运动视频。
AI教程资讯
2023-04-14

ProtGPS(Protein Localization Prediction Model)是麻省理工学院(MIT)和怀特黑德生物医学研究所推出的,基于深度学习的蛋白质语言模型,用在预测蛋白质在细胞内的亚细胞定位。ProtGPS基于分析蛋白质的氨基酸序列,用进化尺度的蛋白质变换器(Transformer)架构学习序列中的复杂模式和相互关系。
AI教程资讯
2023-04-14
potpie ai 是开源平台,基于AI技术为代码库创建定制化的工程代理(Agents)。potpie ai基于构建代码库的知识图谱,深度理解代码组件之间的关系,实现自动化代码分析、测试和开发任务。potpie ai提供多种预构建的代理,例如调试代理、代码库问答代理、代码变更代理、集成测试代理、单元测试代理、低层次设计代理和代码生成代理等。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载















