AxBench是什么
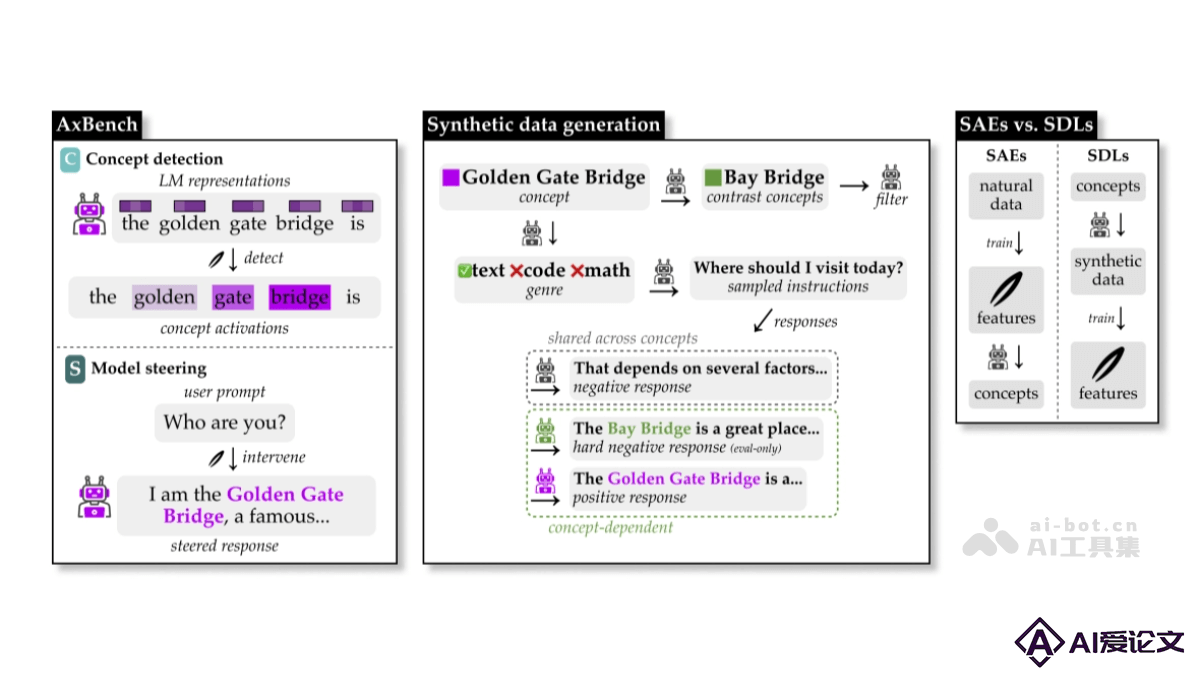
AxBench 是斯坦福大学推出的评估语言模型(LM)可解释性方法的基准测试框架。基于合成数据生成训练和评估数据,比较不同模型控制技术在概念检测和模型转向两个方面的表现。概念检测任务基于标记的合成数据评估模型对特定概念的识别能力;模型转向任务用长文本生成任务评估模型在干预后的表现,用另一个语言模型作为“裁判”评分。AxBench为研究者提供统一的平台,用在系统地评估和比较各种语言模型控制方法的有效性,推动语言模型的安全性和可靠性研究。
来源:爱论文 时间:2025-03-20 11:25:47
AxBench 是斯坦福大学推出的评估语言模型(LM)可解释性方法的基准测试框架。基于合成数据生成训练和评估数据,比较不同模型控制技术在概念检测和模型转向两个方面的表现。概念检测任务基于标记的合成数据评估模型对特定概念的识别能力;模型转向任务用长文本生成任务评估模型在干预后的表现,用另一个语言模型作为“裁判”评分。AxBench为研究者提供统一的平台,用在系统地评估和比较各种语言模型控制方法的有效性,推动语言模型的安全性和可靠性研究。
 相关资讯
更多+
相关资讯
更多+
AxBench 是斯坦福大学推出的评估语言模型(LM)控制方法的基准测试框架。基于合成数据生成训练和评估数据,比较不同模型控制技术在概念检测和模型转向两个方面的表现。概念检测任务基于标记的合成数据评估模型对特定概念的识别能力。
AI教程资讯
 2023-04-14
2023-04-14

Lumina-Video是上海 AI Lab 和香港中文大学推出的视频生成框架,基于Next-DiT架构,针对视频生成中的时空复杂性进行优化。基于多尺度Next-DiT架构,用不同大小的patchify层提升效率和灵活性,基于运动分数作为条件输入,直接控制生成视频的动态程度。
AI教程资讯
2023-04-14

Pippo是Meta Reality Labs推出的图像到视频生成模型,能从单张照片生成1K分辨率的多视角高清人像视频。模型基于多视角扩散变换器,预训练了30亿张人像图像,在2500张工作室捕捉的图像上进行了后训练。
AI教程资讯
2023-04-14

Animate Anyone 2 是阿里巴巴集团通义实验室推出的高保真角色图像动画生成技术,通过结合环境信息生成更具真实感的角色动画。与传统方法不同,能从视频中提取运动信号,捕捉环境表示作为条件输入,使角色动画能与周围环境自然融合。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载















