Sa2VA是什么
Sa2VA是字节跳动联合加州大学默塞德分校、武汉大学和北京大学共同推出的多模态大语言模型,是SAM2和LLaVA结合而成,能实现对图像和视频的密集、细粒度理解。Sa2VA基于统一的任务表示,将图像或视频指代分割、视觉对话、视觉提示理解等任务整合到一个框架中,用LLM生成的空间-时间提示指导SAM2生成精确分割掩码。Sa2VA采用解耦设计,保留SAM2的感知能力和LLaVA的语言理解能力,引入Ref-SAV数据集,用在提升复杂视频场景下的指代分割性能。

来源:爱论文 时间:2025-03-19 13:40:42
Sa2VA是字节跳动联合加州大学默塞德分校、武汉大学和北京大学共同推出的多模态大语言模型,是SAM2和LLaVA结合而成,能实现对图像和视频的密集、细粒度理解。Sa2VA基于统一的任务表示,将图像或视频指代分割、视觉对话、视觉提示理解等任务整合到一个框架中,用LLM生成的空间-时间提示指导SAM2生成精确分割掩码。Sa2VA采用解耦设计,保留SAM2的感知能力和LLaVA的语言理解能力,引入Ref-SAV数据集,用在提升复杂视频场景下的指代分割性能。
 相关资讯
更多+
相关资讯
更多+
Sa2VA是字节跳动联合加州大学默塞德分校、武汉大学和北京大学共同推出的多模态大语言模型,是SAM2和LLaVA结合而成,能实现对图像和视频的密集、细粒度理解。Sa2VA基于统一的任务表示,将图像或视频指代分割、视觉对话、视觉提示理解等任务整合到一个框架中,用LLM生成的空间-时间提示指导SAM2生成精确分割掩码。
AI教程资讯
 2023-04-14
2023-04-14

WebLI-100B是Google DeepMind推出的包含1000亿图像-文本对的超大规模数据集,用在预训练视觉语言模型(VLMs)。WebLI-100B是WebLI数据集的扩展版本,基于从网络中收集大量图像及其对应的标题或页面标题作为文本配对信息构建而成。
AI教程资讯
2023-04-14

BAG(Body-Aligned 3D Wearable Asset Generation)是香港中文大学和腾讯联合提出创新的3D可穿戴资产生成技术,通过结合多视图图像扩散模型和控制网络(ControlNet),运用人体形状和姿态信息,自动生成与人体完美适配的3D可穿戴资产,如服装和配饰。
AI教程资讯
2023-04-14
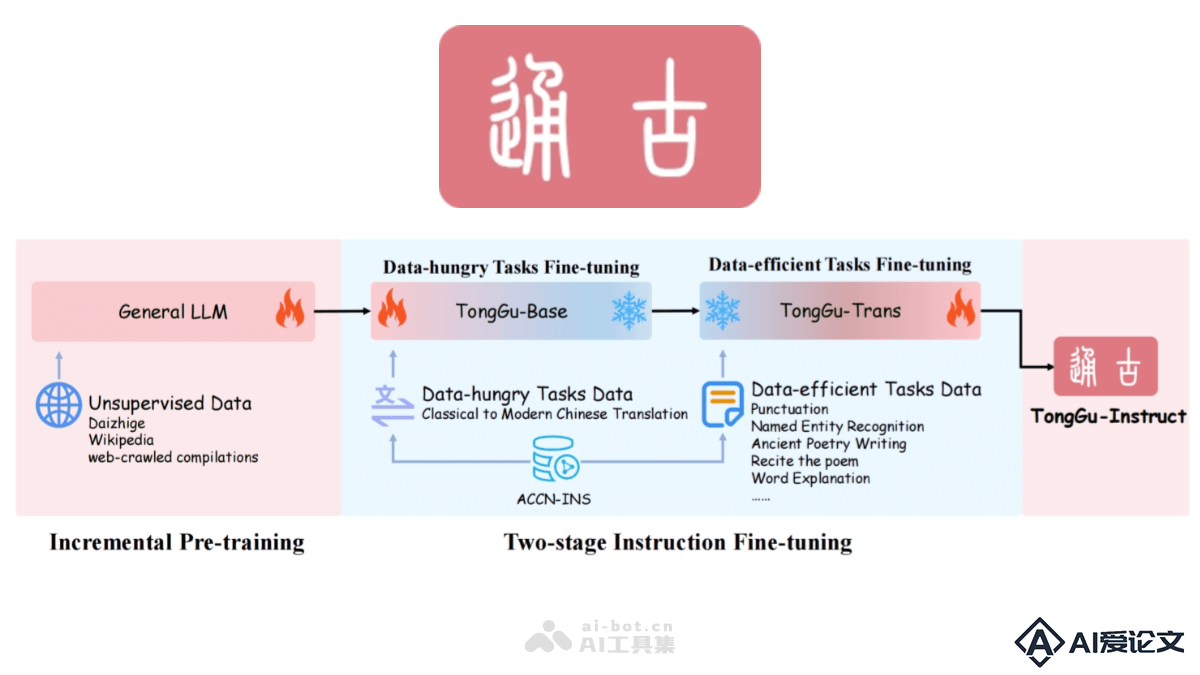
通古大模型是华南理工大学深度学习与视觉计算实验室(SCUT-DLVCLab)推出的专注于古籍文言文处理的人工智能语言模型。基于百川2-7B-Base进行增量预训练,使用24 1亿古籍语料进行无监督训练,结合400万古籍对话数据进行指令微调。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载















