ImageRAG是什么
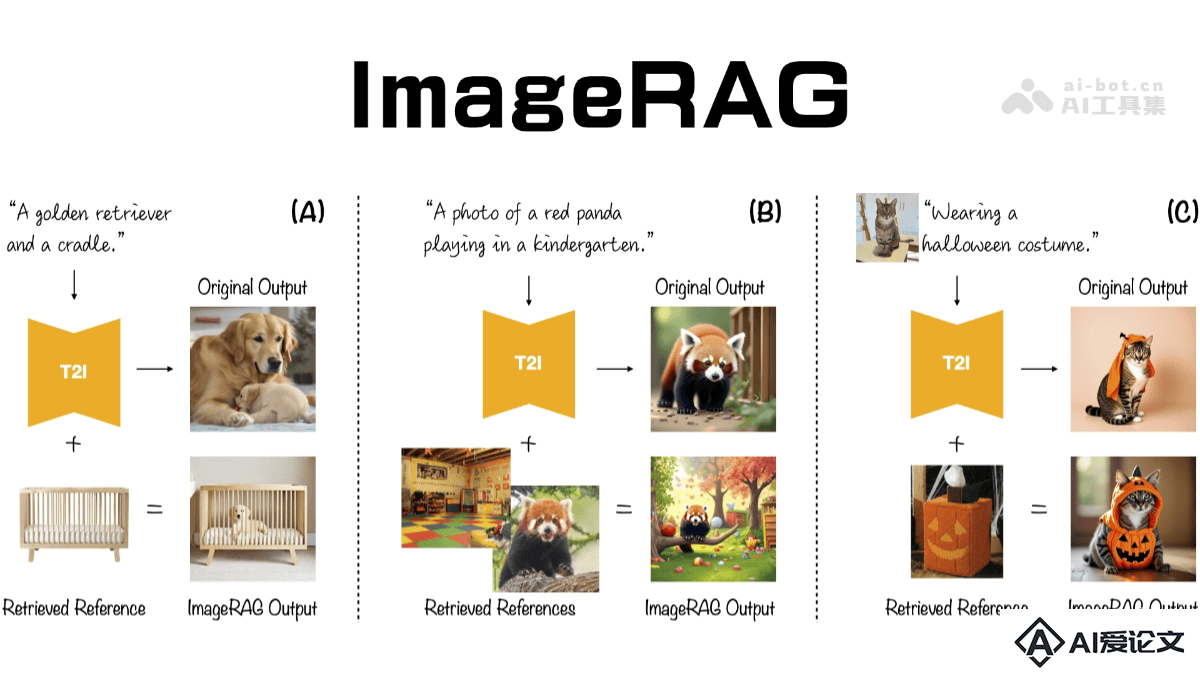
ImageRAG 是基于检索增强生成(Retrieval-Augmented Generation, RAG)的图像生成技术,通过动态检索相关图像来提升文本到图像(T2I)模型生成罕见或未见概念的能力。基于现有的图像条件模型,无需特定的 RAG 训练,可改善生成图像的真实度和相关性。
来源:爱论文 时间:2025-03-18 14:00:25
ImageRAG 是基于检索增强生成(Retrieval-Augmented Generation, RAG)的图像生成技术,通过动态检索相关图像来提升文本到图像(T2I)模型生成罕见或未见概念的能力。基于现有的图像条件模型,无需特定的 RAG 训练,可改善生成图像的真实度和相关性。
 相关资讯
更多+
相关资讯
更多+
ImageRAG 是基于检索增强生成(Retrieval-Augmented Generation, RAG)的图像生成技术,通过动态检索相关图像来提升文本到图像(T2I)模型生成罕见或未见概念的能力。基于现有的图像条件模型,无需特定的 RAG 训练,可改善生成图像的真实度和相关性。
AI教程资讯
 2023-04-14
2023-04-14

X-R1是基于强化学习的低成本训练框架,能加速大规模语言模型的后训练(Scaling Post-Training)开发。X-R1用极低的成本训练0 5B(5亿参数)规模的R1-Zero模型,仅需4块3090或4090 GPU,训练时间约1小时,成本低于10美元。
AI教程资讯
2023-04-14

Step-Video-T2V 是阶跃星辰团队推出的开源文本到视频预训练模型,拥有 300 亿参数,能生成长达 204 帧的高质量视频。模型基于深度压缩的变分自编码器(Video-VAE),实现 16×16 的空间压缩和 8× 的时间压缩,显著提高了训练和推理效率。
AI教程资讯
2023-04-14
unsloth 是开源的大语言模型(LLM)微调工具,基于优化计算步骤和 GPU 内核,显著提升模型训练速度减少内存使用。Unsloth支持多种主流 LLM,如 Llama-3、Mistral、Phi-4 等,在单 GPU 上实现最高 10 倍、多 GPU 上最高 32 倍的加速效果,同时内存使用减少 70% 以上。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载















