MinT是什么
MinT(Mind the Time)是Snap Research、多伦多大学和向量研究所联合推出的多事件视频生成框架,基于精确的时间控制,根据文本提示生成包含多个事件的视频序列。MinT的核心技术是时间基位置编码(ReRoPE),让模型能将特定的文本提示与视频中的相应时间段关联起来,确保事件按顺序发生,控制每个事件的持续时间。作为首个提供视频中事件时间控制的模型,MinT在生成连贯、动态连接的事件方面超越现有的开源模型,为视频内容创作带来新的灵活性和控制能力。

来源:爱论文 时间:2025-01-16 12:40:24
MinT(Mind the Time)是Snap Research、多伦多大学和向量研究所联合推出的多事件视频生成框架,基于精确的时间控制,根据文本提示生成包含多个事件的视频序列。MinT的核心技术是时间基位置编码(ReRoPE),让模型能将特定的文本提示与视频中的相应时间段关联起来,确保事件按顺序发生,控制每个事件的持续时间。作为首个提供视频中事件时间控制的模型,MinT在生成连贯、动态连接的事件方面超越现有的开源模型,为视频内容创作带来新的灵活性和控制能力。
 相关资讯
更多+
相关资讯
更多+
MinT(Mind the Time)是Snap Research、多伦多大学和向量研究所联合推出的多事件视频生成框架,基于精确的时间控制,根据文本提示生成包含多个事件的视频序列。MinT的核心技术是时间基位置编码(ReRoPE),让模型能将特定的文本提示与视频中的相应时间段关联起来,确保事件按顺序发生,控制每个事件的持续时间。
AI教程资讯
 2023-04-14
2023-04-14
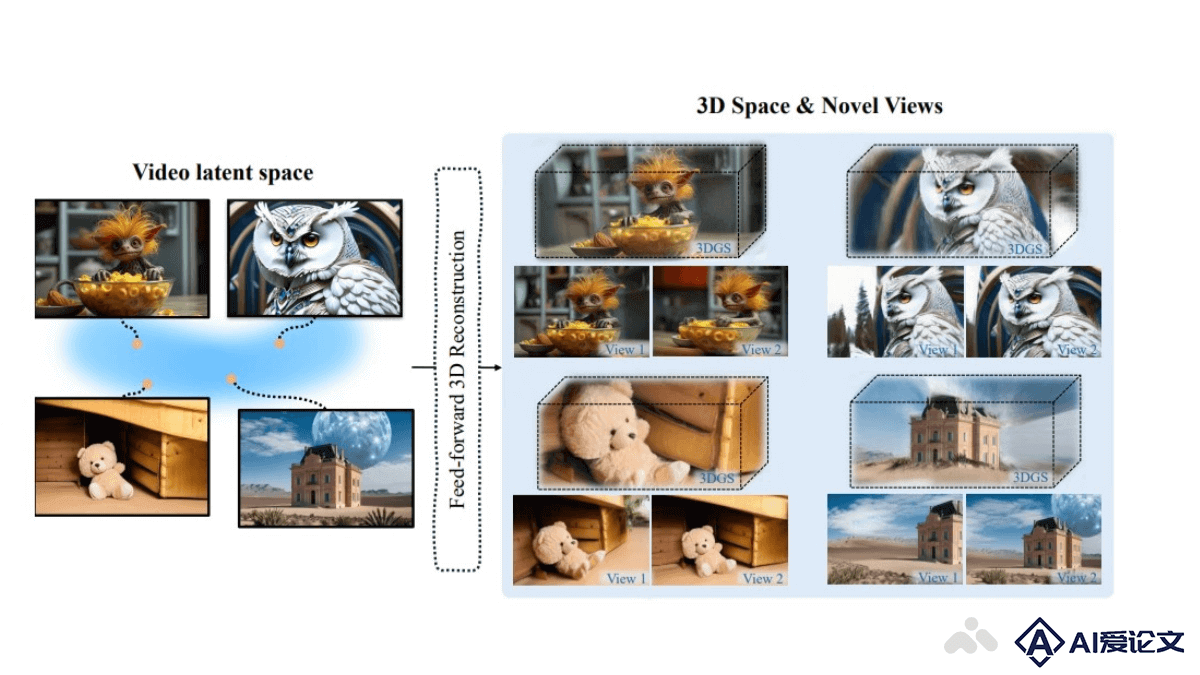
Wonderland是多伦多大学、Snap和UCLA的研究团队推出的技术,能够从单张图像生成高质量、广范围的3D场景,允许控制摄像轨迹。证明了三维重建模型可以有效地建立在扩散模型的潜在空间上,实现高效的三维场景生成,是单视图3D场景生成领域的一次突破性进展。
AI教程资讯
2023-04-14
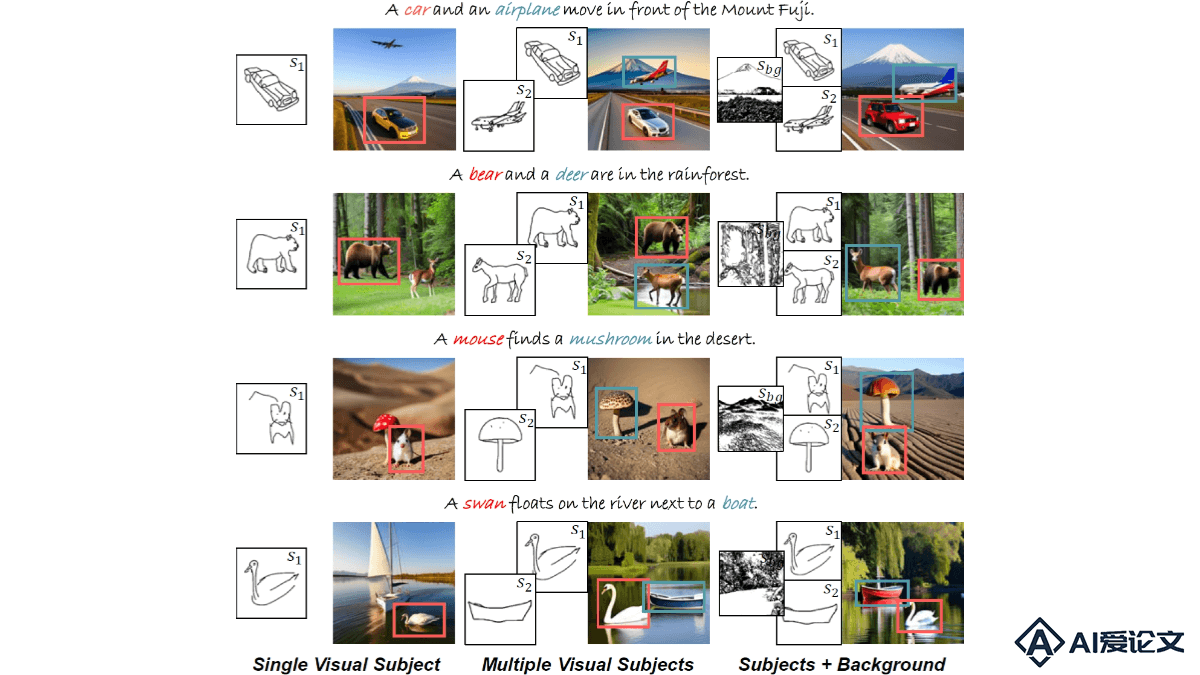
VersaGen是文本到图像合成的生成式AI代理,能实现灵活的视觉控制能力。VersaGen能处理包括单一视觉主体、多个视觉主体、场景背景,这些元素的任意组合在内的多种视觉控制类型。基于在已有的文本主导的扩散模型上训练适配器,VersaGen成功地将视觉信息融入图像生成过程中。
AI教程资讯
2023-04-14
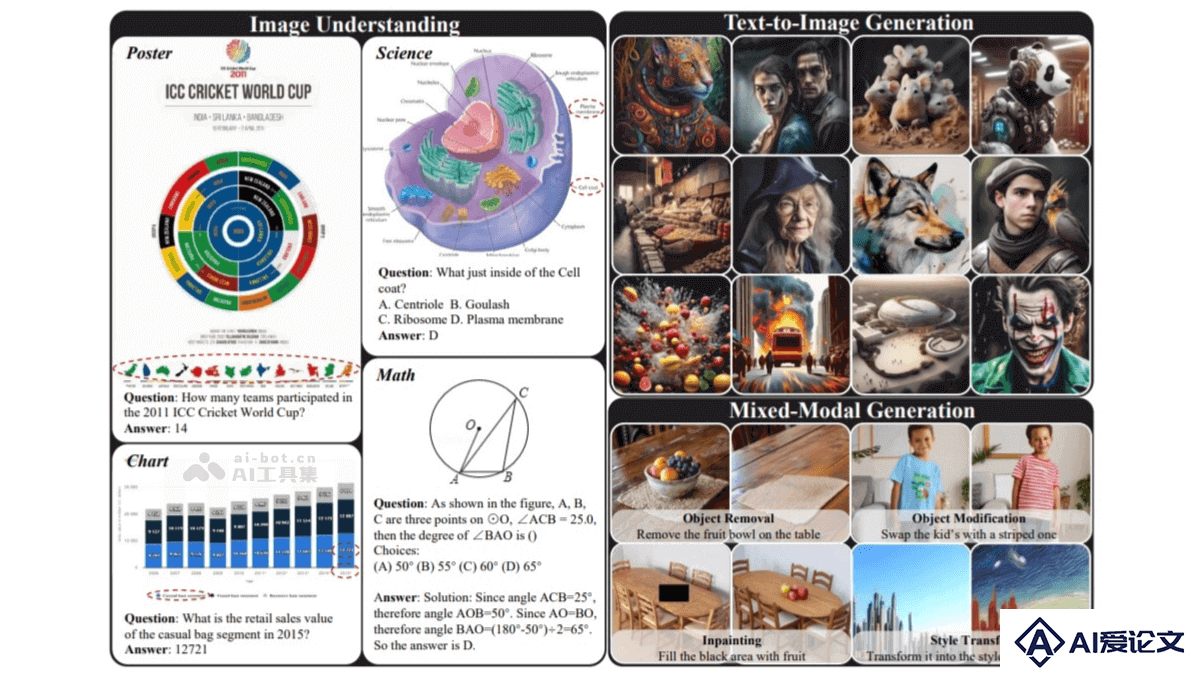
ILLUME是华为诺亚方舟实验室提出的统一多模态大模型,将视觉理解与生成能力融入同一框架中。模型以大型语言模型(LLM)为核心,采用“连续图像输入 + 离散图像输出”的架构,融合了多模态理解与生成的双重能力,深度挖掘了统一框架下理解与生成能力协同增强的潜力。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载












