Westlake-Omni是什么
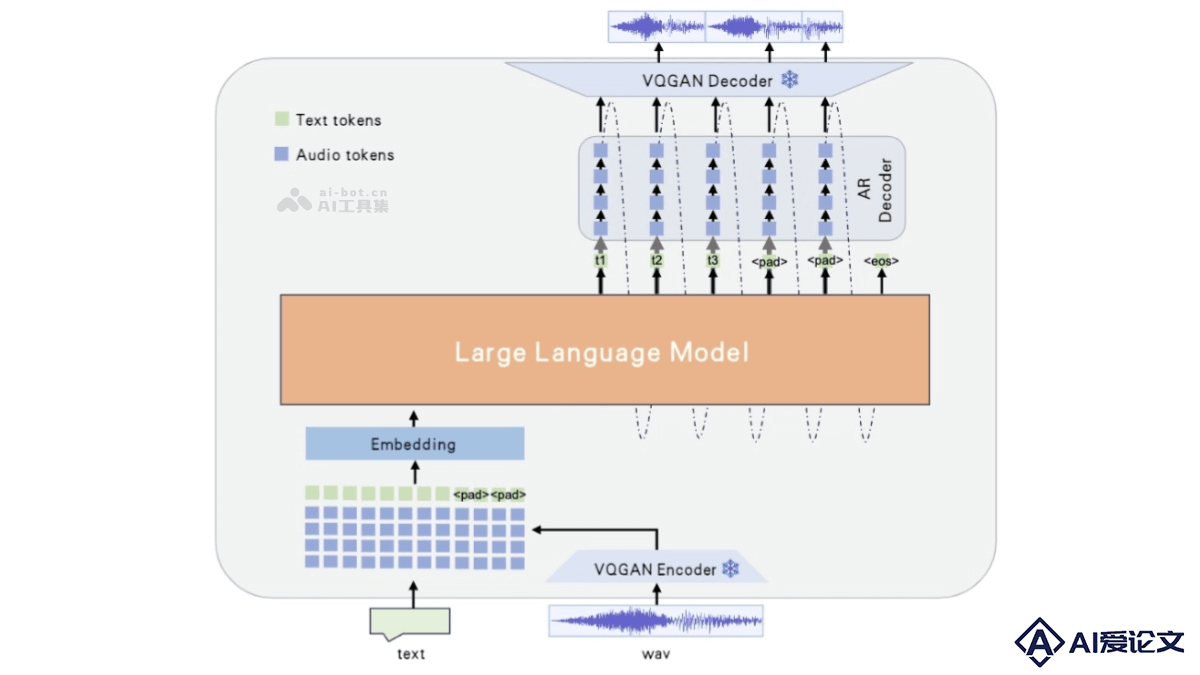
Westlake-Omni 是西湖心辰推出的全球首个开源中文情感端到端语音交互大模型。模型采用离散表示法,统一文本和语音模态的处理,特别强调实时性,快速响应用户输入,提供零延迟的交互体验。Westlake-Omni 在高质量中文情感语音数据集上进行深度训练,具备出色的情感理解和表达能力,能生成清晰、自然、富有表现力的中文语音。使模型能理解中文语境下的复杂情感,使语音交互更加人性化。
来源:爱论文 时间:2025-02-25 15:55:42
Westlake-Omni 是西湖心辰推出的全球首个开源中文情感端到端语音交互大模型。模型采用离散表示法,统一文本和语音模态的处理,特别强调实时性,快速响应用户输入,提供零延迟的交互体验。Westlake-Omni 在高质量中文情感语音数据集上进行深度训练,具备出色的情感理解和表达能力,能生成清晰、自然、富有表现力的中文语音。使模型能理解中文语境下的复杂情感,使语音交互更加人性化。
 相关资讯
更多+
相关资讯
更多+
Westlake-Omni 是西湖心辰推出的全球首个开源中文情感端到端语音交互大模型。模型采用离散表示法,统一文本和语音模态的处理,特别强调实时性,快速响应用户输入,提供零延迟的交互体验。
AI教程资讯
 2023-04-14
2023-04-14
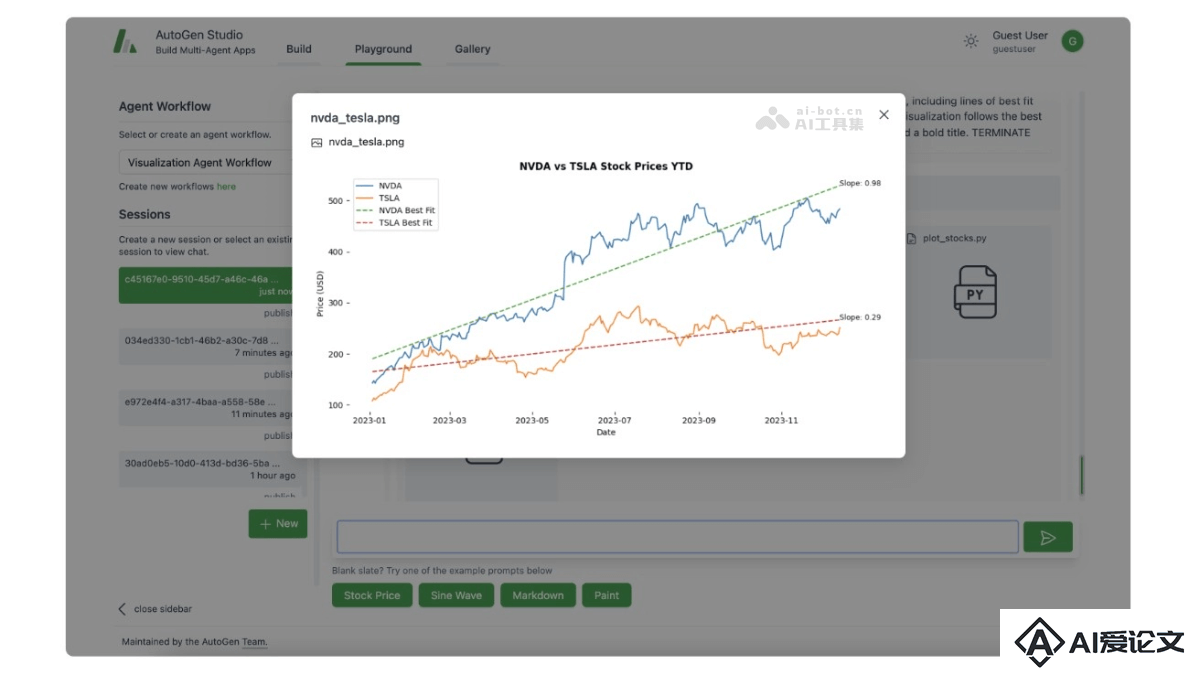
AutoGen Studio 是微软研究院推出的一款开源界面工具,旨在简化多智能体系统的构建、调试和评估过程。AutoGen Studio提供一个基于 Web 的交互式界面和 Python API,支持用户拖放和声明式规范定义智能体及工作流,无需编写代码。
AI教程资讯
2023-04-14

IDIFY是一款免费开源的在线证件照生成工具,通过AI技术实现自动抠图,帮助用户快速生成符合标准的证件照。用户只需在浏览器中上传照片,选择尺寸和背景色,可下载高清证件照。
AI教程资讯
2023-04-14

Emu3是由北京智源人工智能研究院推出的一款原生多模态世界模型,采用智源自研的多模态自回归技术路径,在图像、视频、文字上联合训练,使模型具备原生多模态能力,实现图像、视频、文字的统一输入和输出。Emu3将各种内容转换为离散符号,基于单一的Transformer模型来预测下一个符号,简化了模型架构。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载