Seed-VC是什么
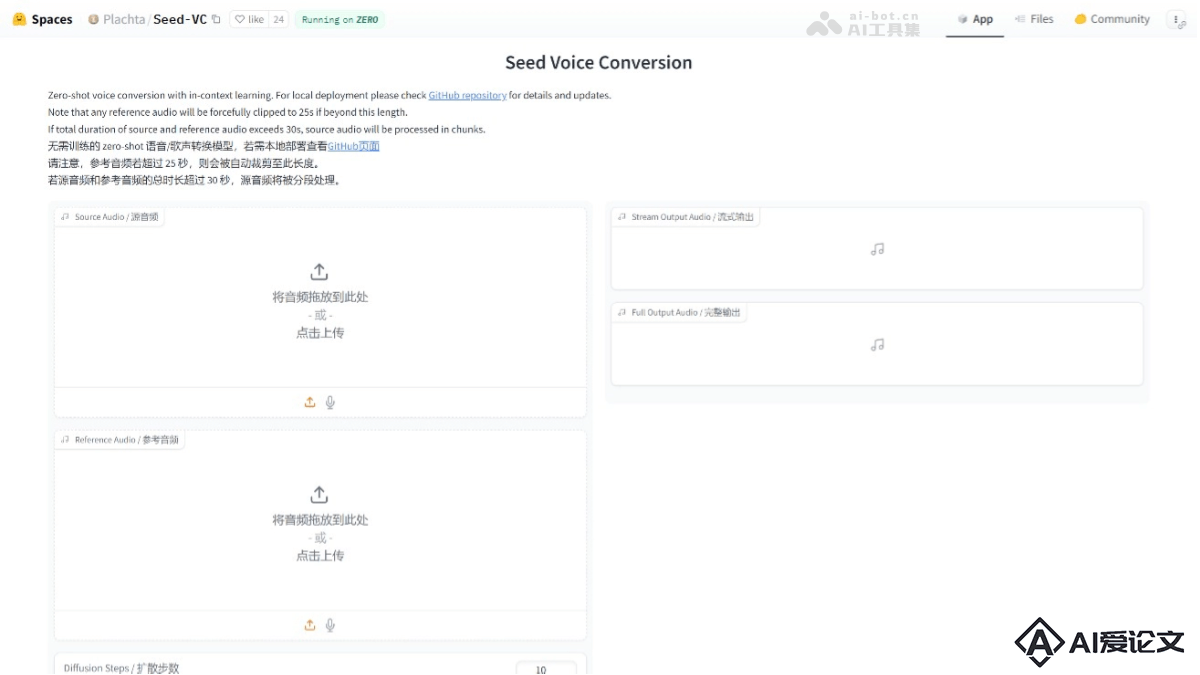
Seed-VC 是一种零样本声音转换技术,基于上下文学习实现高质量的音频输出和音色相似度。用户无需进行特定训练,只需提供1到30秒的参考语音样本,实现声音的克隆和转换。转换技术特别适合声音转换研究、娱乐、媒体制作、语音合成等场景。Seed-VC 支持零样本歌声转换,能将说话声音转换为歌声,同时保持原声音的音色特征。Seed-VC 提供命令行工具和 Gradio Web 界面,用户能轻松地进行声音转换。
来源:爱论文 时间:2025-02-25 10:49:59
Seed-VC 是一种零样本声音转换技术,基于上下文学习实现高质量的音频输出和音色相似度。用户无需进行特定训练,只需提供1到30秒的参考语音样本,实现声音的克隆和转换。转换技术特别适合声音转换研究、娱乐、媒体制作、语音合成等场景。Seed-VC 支持零样本歌声转换,能将说话声音转换为歌声,同时保持原声音的音色特征。Seed-VC 提供命令行工具和 Gradio Web 界面,用户能轻松地进行声音转换。
 相关资讯
更多+
相关资讯
更多+
Seed-VC 是一种零样本声音转换技术,基于上下文学习实现高质量的音频输出和音色相似度。用户无需进行特定训练,只需提供1到30秒的参考语音样本,实现声音的克隆和转换。
AI教程资讯
 2023-04-14
2023-04-14

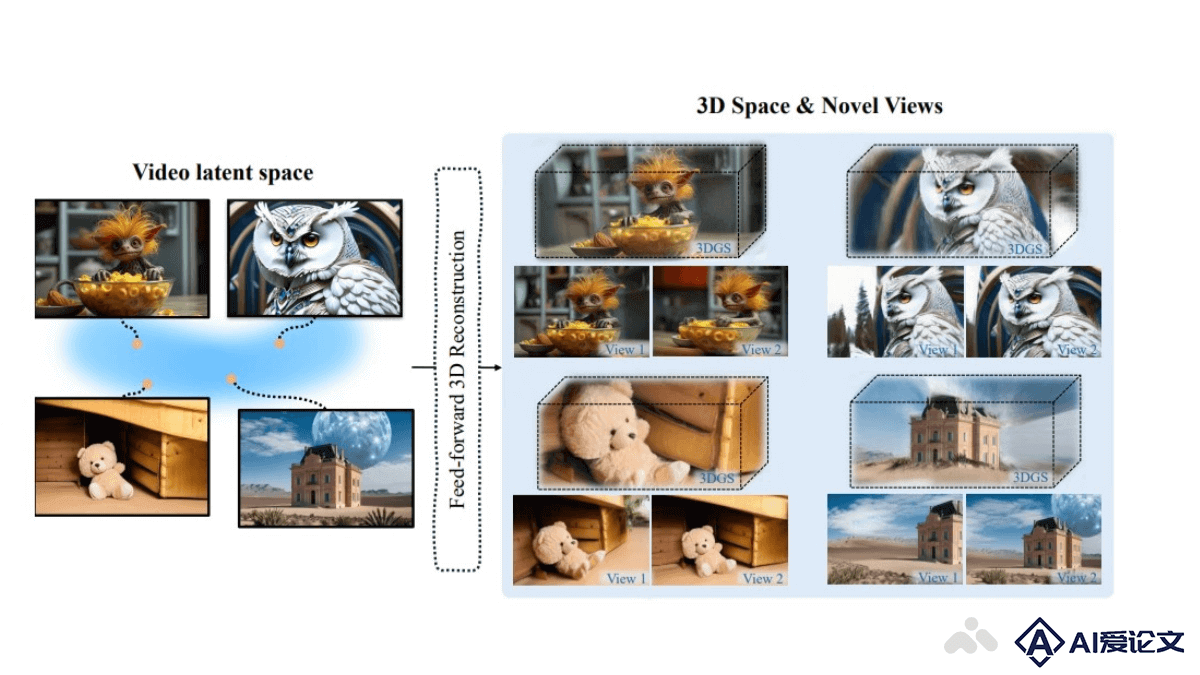
Phidias是一个先进的3D内容生成模型,将检索增强生成(RAG)的概念引入到3D建模领域。模型能基于用户提供的或从大型数据库中检索到的3D参考模型,辅助生成新的3D内容。
AI教程资讯
2023-04-14

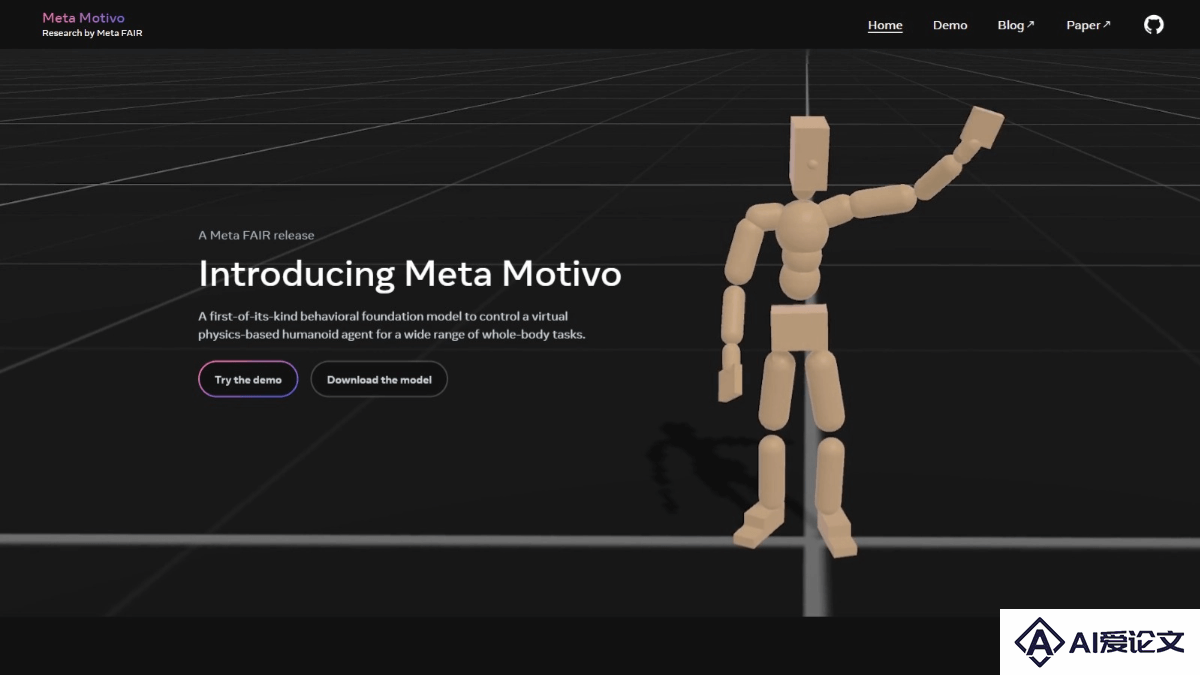
Movie Gen 是 Meta 推出的AI视频生成工具,能根据文本提示生成和编辑视频,为视频配上同步音频。技术包括创建长达16秒的高清视频、为现有视频配上音频、编辑视频以及基于照片制作定制视频。
AI教程资讯
2023-04-14
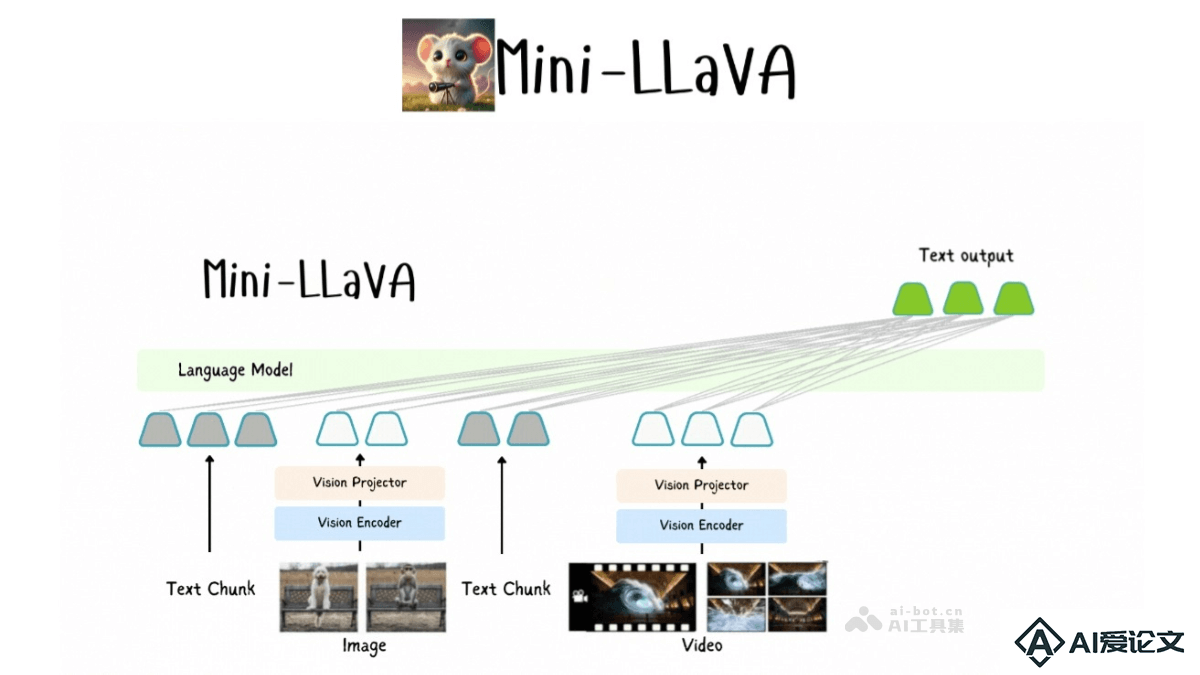
Mini-LLaVA是一款轻量级的多模态大语言模型,由清华大学和北京航空航天大学的研究团队联合开发。能处理图像、文本和视频输入,实现高效的多模态数据处理。Mini-LLaVA基于Llama 3 1模型,优化了代码结构,在单个GPU上即可运行,适合复杂的视觉-文本关联任务。
AI教程资讯
2023-04-14
热门推荐
更多+

 下载
下载