SaRA是什么
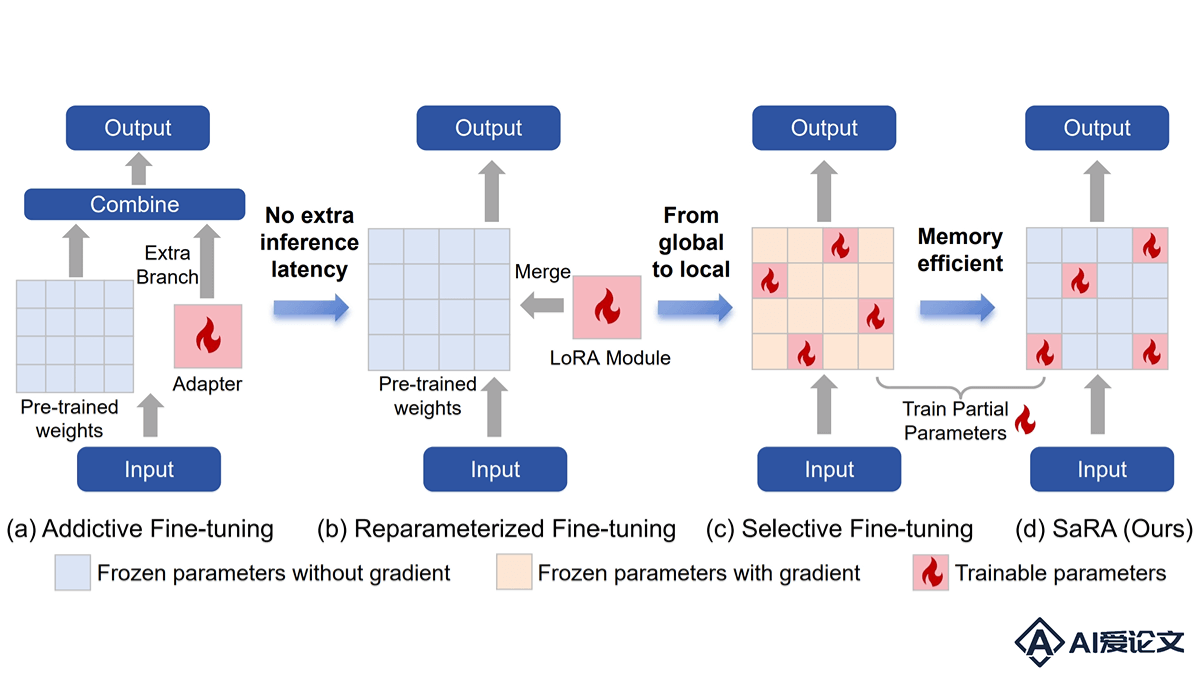
SaRA是一种新型的预训练扩散模型微调方法,由上海交通大学和腾讯优图实验室共同推出。基于重新激活预训练过程中看似无效的参数,让模型能适应新任务。SaRA基于核范数低秩稀疏训练方案避免过拟合,引入渐进式参数调整策略,优化模型性能。SaRA能提高模型的适应性和泛化能力,显著降低计算成本,只要修改一行代码即可实现,具有很高的实用价值。
来源:爱论文 时间:2025-02-18 12:07:51
SaRA是一种新型的预训练扩散模型微调方法,由上海交通大学和腾讯优图实验室共同推出。基于重新激活预训练过程中看似无效的参数,让模型能适应新任务。SaRA基于核范数低秩稀疏训练方案避免过拟合,引入渐进式参数调整策略,优化模型性能。SaRA能提高模型的适应性和泛化能力,显著降低计算成本,只要修改一行代码即可实现,具有很高的实用价值。
 相关资讯
更多+
相关资讯
更多+
SaRA是一种新型的预训练扩散模型微调方法,由上海交通大学和腾讯优图实验室共同推出。基于重新激活预训练过程中看似无效的参数,让模型能适应新任务。SaRA基于核范数低秩稀疏训练方案避免过拟合,引入渐进式参数调整策略,优化模型性能。
AI教程资讯
 2023-04-14
2023-04-14

Quanta Quest是一款面向个人用户的开源AI时代智能数据库产品,基于将个人数据如Gmail、Dropbox、Notion等整合到一个平台上,用RAG技术提供AI搜索功能,帮助用户高效管理和检索信息。Quanta Quest特别强调隐私保护和数据安全,确保用户数据的本地化处理,在保护个人隐私的同时,提供强大的数据检索能力。
AI教程资讯
2023-04-14

BiGR是一种新型的条件图像生成模型,用紧凑的二进制潜在代码进行生成训练,增强图像的生成质量和表示能力。作为首个在同一框架内统一生成和判别任务的模型,BiGR在保持高生成质量的同时,能有效地执行视觉生成、辨别和编辑等多种视觉任务。
AI教程资讯
2023-04-14

MoE++是一种新型的混合专家(Mixture-of-Experts)架构,由昆仑万维2050研究院与北大袁粒团队联合推出。基于引入零计算量专家,即零专家、复制专家和常数专家,降低计算成本、提升模型性能。MoE++支持每个Token动态地与不同数量的前馈网络专家交互,甚至跳过某些层,优化计算资源分配。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















