OmniGen是什么
OmniGen是用于统一图像生成的新扩散模型,能在单一框架内处理多种图像生成任务,如文本到图像的生成、图像编辑、主题驱动生成和视觉条件生成等。OmniGen涉及传统计算机视觉任务,将任务转化为图像生成任务增强模型的复杂图像生成能力。OmniGen的架构简化,不需要额外的文本编码器,让用户用指令完成复杂任务,无需额外的预处理步骤,简化图像生成的工作流程。OmniGen展现出推理能力和链式思考机制,能处理多步图像编辑任务,在少样本学习中展现出对新任务的快速学习能力。

来源:爱论文 时间:2025-02-17 10:48:53
OmniGen是用于统一图像生成的新扩散模型,能在单一框架内处理多种图像生成任务,如文本到图像的生成、图像编辑、主题驱动生成和视觉条件生成等。OmniGen涉及传统计算机视觉任务,将任务转化为图像生成任务增强模型的复杂图像生成能力。OmniGen的架构简化,不需要额外的文本编码器,让用户用指令完成复杂任务,无需额外的预处理步骤,简化图像生成的工作流程。OmniGen展现出推理能力和链式思考机制,能处理多步图像编辑任务,在少样本学习中展现出对新任务的快速学习能力。
 相关资讯
更多+
相关资讯
更多+
OmniGen是用于统一图像生成的新扩散模型,能在单一框架内处理多种图像生成任务,如文本到图像的生成、图像编辑、主题驱动生成和视觉条件生成等。OmniGen涉及传统计算机视觉任务,将任务转化为图像生成任务增强模型的复杂图像生成能力。
AI教程资讯
 2023-04-14
2023-04-14
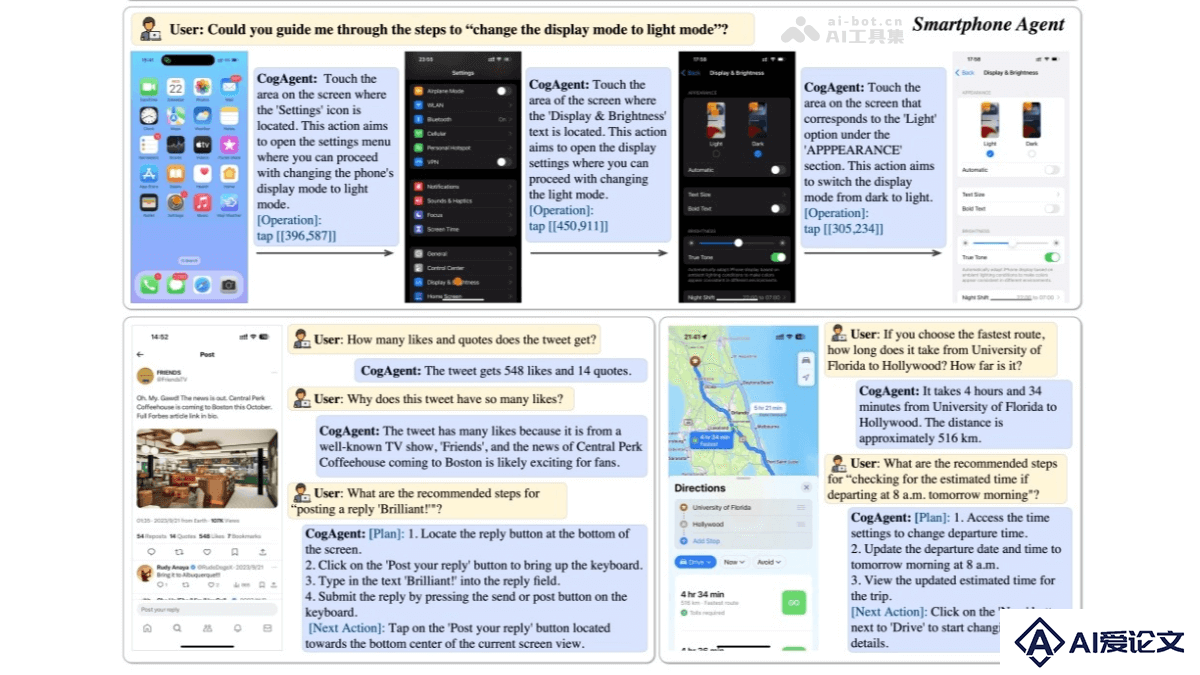
CogAgent是清华大学与智谱AI联合推出的多模态视觉大模型,专注于图形用户界面(GUI)的理解和导航。通过视觉模态对GUI界面进行感知,非传统的文本模态,更符合人类的直觉交互方式。
AI教程资讯
2023-04-14

OMNE Multiagent是天桥脑科学研究院(Tianqiao and Chrissy Chen Institute,TCCI)推出的大模型多智能体框架。基于长期记忆(Long Term Memory, LTM)构建,每个智能体拥有相同且独立的系统结构,能自主学习和理解完整的世界模型,独立理解环境。
AI教程资讯
2023-04-14

DuoAttention是新型的框架,由MIT韩松团队提出,用在提高大型语言模型(LLMs)在处理长上下文时的推理效率。基于区分“检索头”和“流式头”两种注意力头,优化模型的内存使用和计算速度。检索头负责处理长距离依赖,需要完整的键值(KV)缓存,流式头关注最近token和注意力汇聚点,只需固定长度的KV缓存。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















