TextHarmony是什么
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和语言的生成。TextHarmony在视觉和语言模态之间实现更统一的生成过程。研究团队推出高质量的图像字幕数据集DetailedTextCaps-100K,基于高级闭源MLLM合成,进一步提升模型的视觉文本生成能力。

来源:爱论文 时间:2025-02-14 13:00:44
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和语言的生成。TextHarmony在视觉和语言模态之间实现更统一的生成过程。研究团队推出高质量的图像字幕数据集DetailedTextCaps-100K,基于高级闭源MLLM合成,进一步提升模型的视觉文本生成能力。
 相关资讯
更多+
相关资讯
更多+
TextHarmony是华东师范大学和字节跳动共同推出的多模态生成模型,擅长理解和生成视觉文本。模型基于Slide-LoRA技术,动态聚合特定于模态和模态无关的LoRA专家,部分解耦多模态生成空间,在单一模型实例中协调视觉和语言的生成。
AI教程资讯
 2023-04-14
2023-04-14
BlinkShot是实时AI图像生成器,能迅速生成高质量的图像。用户只需输入提示,BlinkShot能在几毫秒内生成图像。工具基于Together AI的Flux Schnell技术,支持自定义分辨率和生成步骤,非常适合艺术创作和设计领域的专业人士使用。
AI教程资讯
2023-04-14
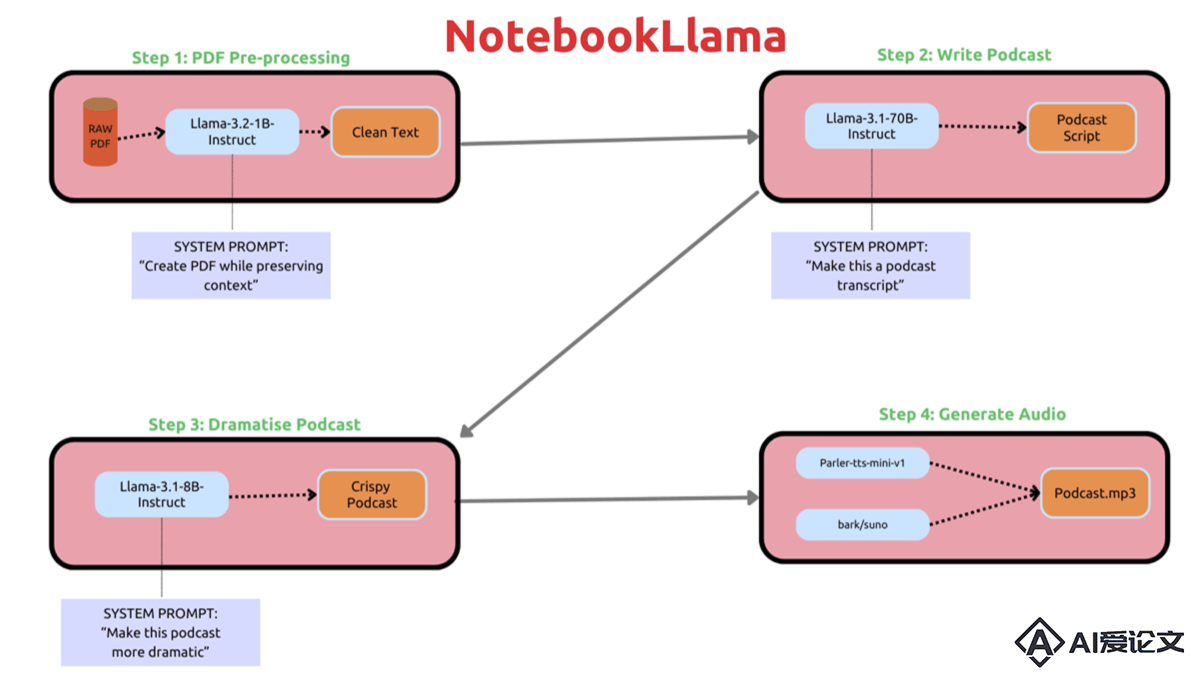
NotebookLlama是Meta推出的将PDF文档转换成播客内容的开源项目。项目基于一系列自动化步骤实现,用LLaMa模型进行PDF预处理、生成播客脚本、增加戏剧化元素及文本转语音合成。整个过程无需人工干预,产出专业水准的播客。
AI教程资讯
2023-04-14

WonderWorld是斯坦福大学和麻省理工学院共同推出的创新性3D场景生成框架,能从单张图片快速生成多样化且连贯的3D虚拟世界。基于核心的Fast LAyered Gaussian Surfels (FLAGS)表示法和引导深度扩散技术,框架在不到10秒的时间内完成场景的生成,极大地提高3D场景创建的速度,保证新旧场景之间的几何一致性。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















