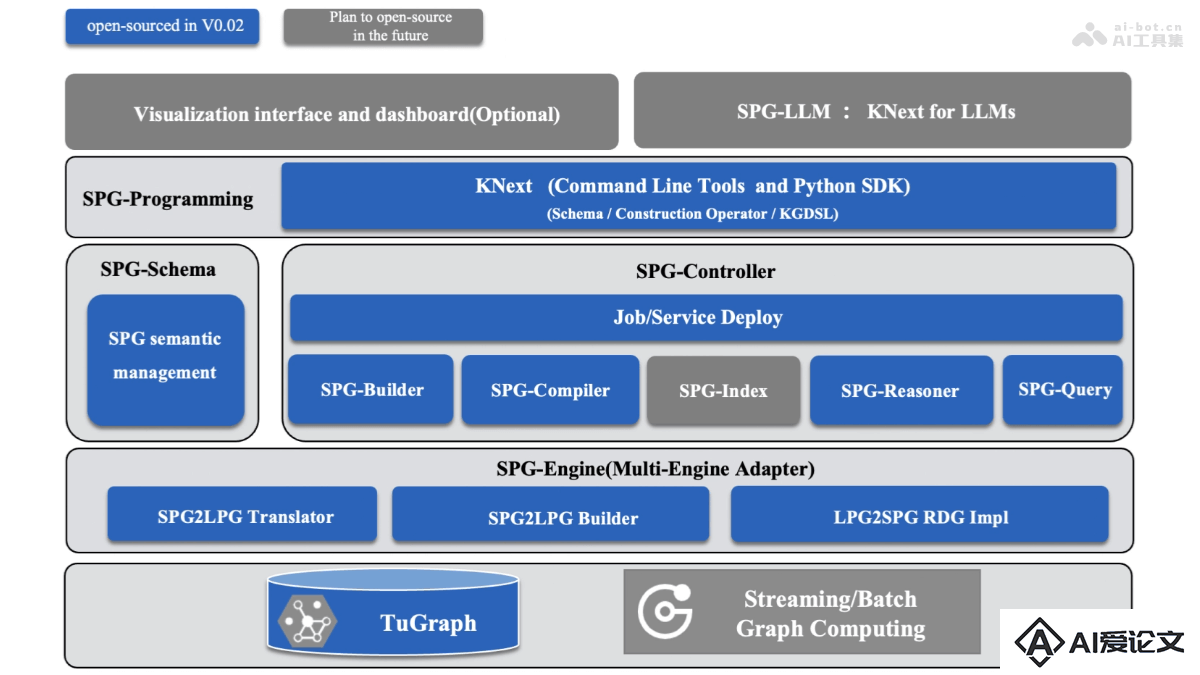
OpenSPG是什么
OpenSPG是蚂蚁集团联合OpenKG社区推出的基于SPG框架的知识图谱引擎。OpenSPG融合LPG的结构性和RDF的语义性,克服RDF/OWL语义复杂难以落地的问题,继承LPG结构简单与大数据体系兼容的优势。OpenSPG提供明确的语义表示、逻辑规则定义和算子框架等能力,支持各厂商可插拔的适配基础引擎和算法服务,构建自定义的解决方案。OpenSPG用高效的知识化转换,帮助提高数据价值和应用价值,适于金融等多种业务场景。
来源:爱论文 时间:2025-02-14 10:12:13
OpenSPG是蚂蚁集团联合OpenKG社区推出的基于SPG框架的知识图谱引擎。OpenSPG融合LPG的结构性和RDF的语义性,克服RDF/OWL语义复杂难以落地的问题,继承LPG结构简单与大数据体系兼容的优势。OpenSPG提供明确的语义表示、逻辑规则定义和算子框架等能力,支持各厂商可插拔的适配基础引擎和算法服务,构建自定义的解决方案。OpenSPG用高效的知识化转换,帮助提高数据价值和应用价值,适于金融等多种业务场景。
 相关资讯
更多+
相关资讯
更多+
OpenSPG是蚂蚁集团联合OpenKG社区推出的基于SPG框架的知识图谱引擎。OpenSPG融合LPG的结构性和RDF的语义性,克服RDF OWL语义复杂难以落地的问题,继承LPG结构简单与大数据体系兼容的优势。
AI教程资讯
 2023-04-14
2023-04-14
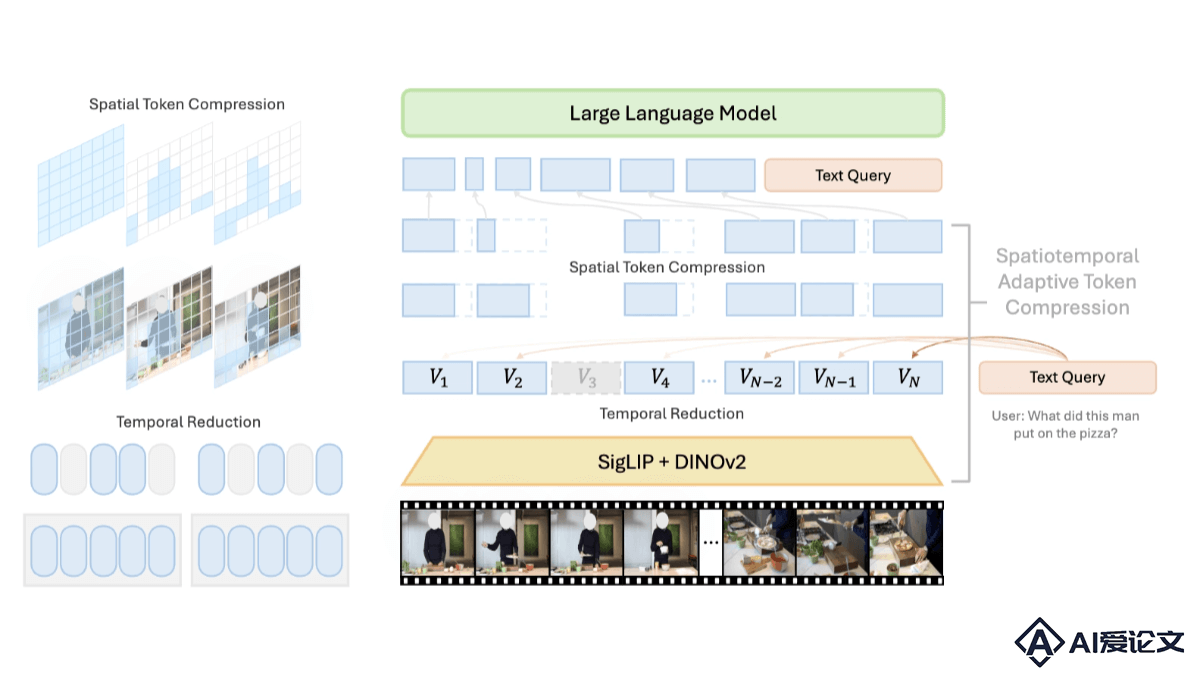
LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节
AI教程资讯
2023-04-14

SynthID Text 是谷歌DeepMind 推出的文本水印技术,用在识别和验证由大型语言模型(LLM)生成的文本。基于细微调整生成过程中的Token概率分数嵌入几乎无法察觉的水印,在不影响文本质量和用户体验的情况下,实现高检测精度。
AI教程资讯
2023-04-14
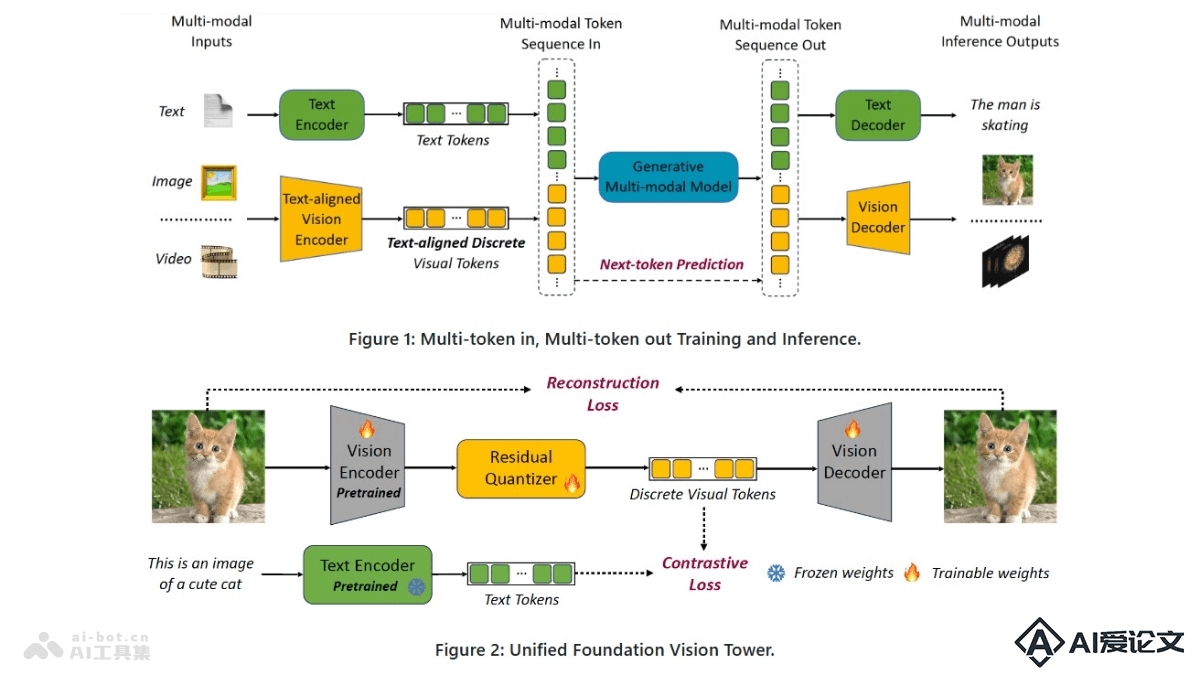
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















