LongVU是什么
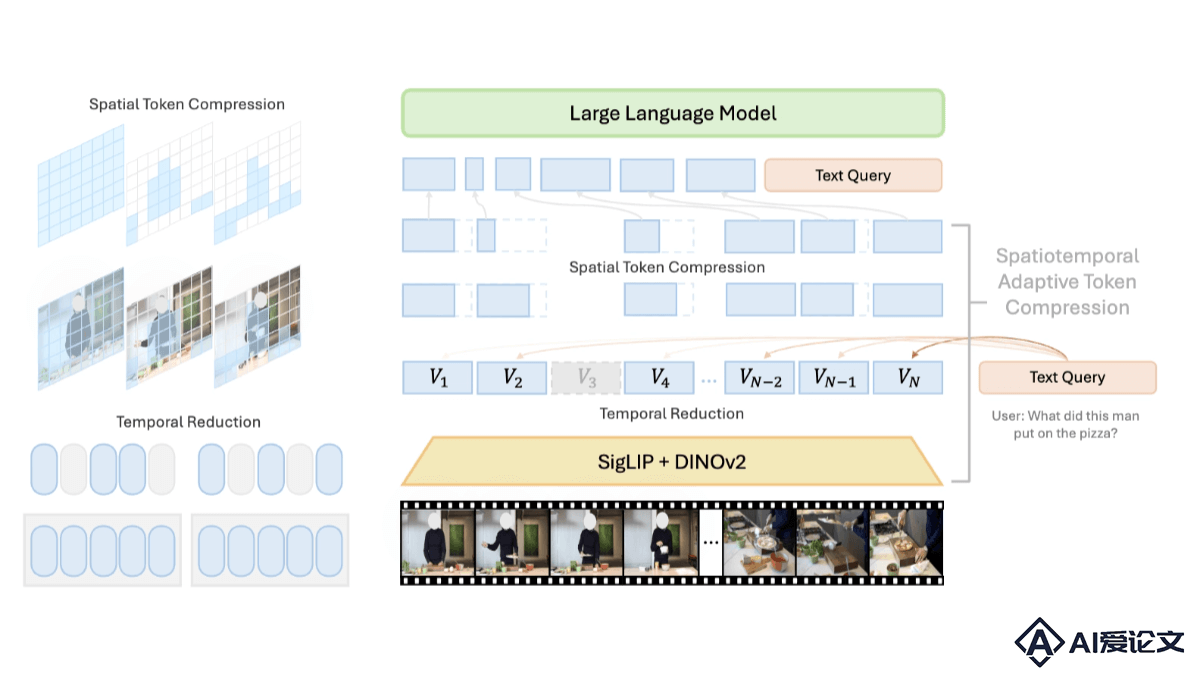
LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节。LongVU用DINOv2特征去除相似度高的冗余帧,用文本引导的跨模态查询进行选择性帧特征减少,在必要时基于时间依赖性进行空间标记压缩。LongVU能有效处理大量帧,在给定的上下文长度内损失很少的视觉信息。
来源:爱论文 时间:2025-02-13 18:06:16
LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节。LongVU用DINOv2特征去除相似度高的冗余帧,用文本引导的跨模态查询进行选择性帧特征减少,在必要时基于时间依赖性进行空间标记压缩。LongVU能有效处理大量帧,在给定的上下文长度内损失很少的视觉信息。
 相关资讯
更多+
相关资讯
更多+
LongVU是Meta AI团队推出的长视频理解模型,基于时空自适应压缩机制。解决处理长视频时受限于大型语言模型(LLM)上下文大小的挑战。LongVU基于跨模态查询和帧间依赖性,LongVU能在减少视频标记数量的同时,保留长视频的视觉细节
AI教程资讯
 2023-04-14
2023-04-14

SynthID Text 是谷歌DeepMind 推出的文本水印技术,用在识别和验证由大型语言模型(LLM)生成的文本。基于细微调整生成过程中的Token概率分数嵌入几乎无法察觉的水印,在不影响文本质量和用户体验的情况下,实现高检测精度。
AI教程资讯
2023-04-14
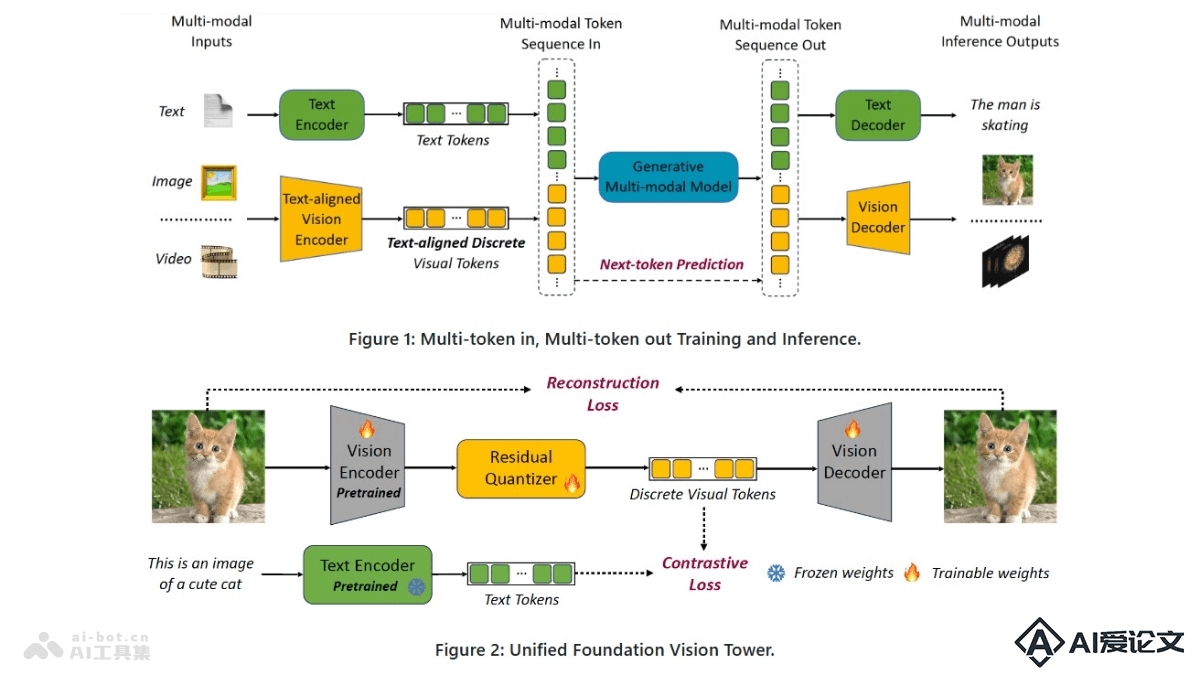
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。
AI教程资讯
2023-04-14

Video-XL是北京智源人工智能研究院联合上海交大、中国人民大学、中科院、北邮和北大的研究人员共同推出的专为小时级视频理解设计的超长视觉理解模型。基于视觉上下文潜在总结技术将视觉信息压缩成紧凑的形式,提高处理效率、减少信息丢失。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















