SynthID Text – 谷歌DeepMind推出的AI生成文本水印技术
来源:爱论文
时间:2025-02-13 17:45:44
SynthID Text 是什么
SynthID Text 是谷歌DeepMind 推出的文本水印技术,用在识别和验证由大型语言模型(LLM)生成的文本。基于细微调整生成过程中的Token概率分数嵌入几乎无法察觉的水印,在不影响文本质量和用户体验的情况下,实现高检测精度。SynthID Text 基于Tournament采样算法,支持非失真和失真两种模式,能在大规模生产系统中用极低的额外计算开销实现。技术已成功应用于Gemini和Gemini Advanced系统,为使用AI技术提供新的可能性。

SynthID Text 的主要功能
文本水印嵌入:能在大型语言模型(LLM)生成的文本中嵌入数字水印,水印用在标识和验证文本来源。质量保持:在嵌入水印的过程中,保持文本的原有质量和自然流畅性,不影响阅读体验。高检测精度:水印设计让嵌入的水印能被高效检测出来,识别文本是否由特定的LLM生成。最小化延迟:水印过程设计为对生成文本的延迟影响极小,适于实时或大规模文本生成场景。不影响LLM训练:水印过程仅在文本生成时的采样阶段进行修改,不影响模型的训练过程。
SynthID Text 的技术原理
采样算法修改:SynthID Text 用修改大型语言模型(LLM)的采样算法嵌入水印。在生成文本时,模型根据概率分布选择下一个Token,SynthID Text 在这一过程中调整概率,嵌入难以察觉的水印。Tournament采样:SynthID Text 用Tournament采样算法,算法用模拟锦标赛过程选择Token。在每一轮中,随机选择多个Token,根据与水印函数相关联的分数选择胜者,过程会进行多轮,直到最终选出一个Token作为输出。随机种子生成:在文本生成的每一步中,SynthID Text 需要一个随机种子影响Token的选择。种子是基于先前的文本和水印密钥生成的,确保水印的随机性和不可预测性。非失真配置:SynthID Text 能配置为非失真模式,在保持文本质量的同时嵌入水印。水印的嵌入不会影响文本的原始概率分布,保证文本的自然性和连贯性。水印检测:在检测阶段,SynthID Text 基于计算文本的统计特征(即g值)确定文本是否包含水印。如果文本包含水印,统计特征将显示出与水印函数相一致的偏差。
SynthID Text 的项目地址
论文地址:https://www.nature.com/articles/s41586-024-08025-4
SynthID Text 的应用场景
内容验证:在新闻、出版和学术领域,验证文章是否由人类撰写或由AI生成,确保内容的可信度。教育评估:在教育环境中,帮助检测学生提交的作业是否用AI生成的文本,维护学术诚信。法律和合规:在法律领域,S检测法律文件或合同中是否含有AI生成的文本,确保法律文件的合法性和有效性。社交媒体:在社交媒体平台上,帮助识别和标记由AI生成的内容,防止误导信息的传播。客户服务:在自动化客户支持系统中,区分自动生成的回复和人工回复,提高客户服务质量。

 相关资讯
相关资讯 2023-04-14
2023-04-14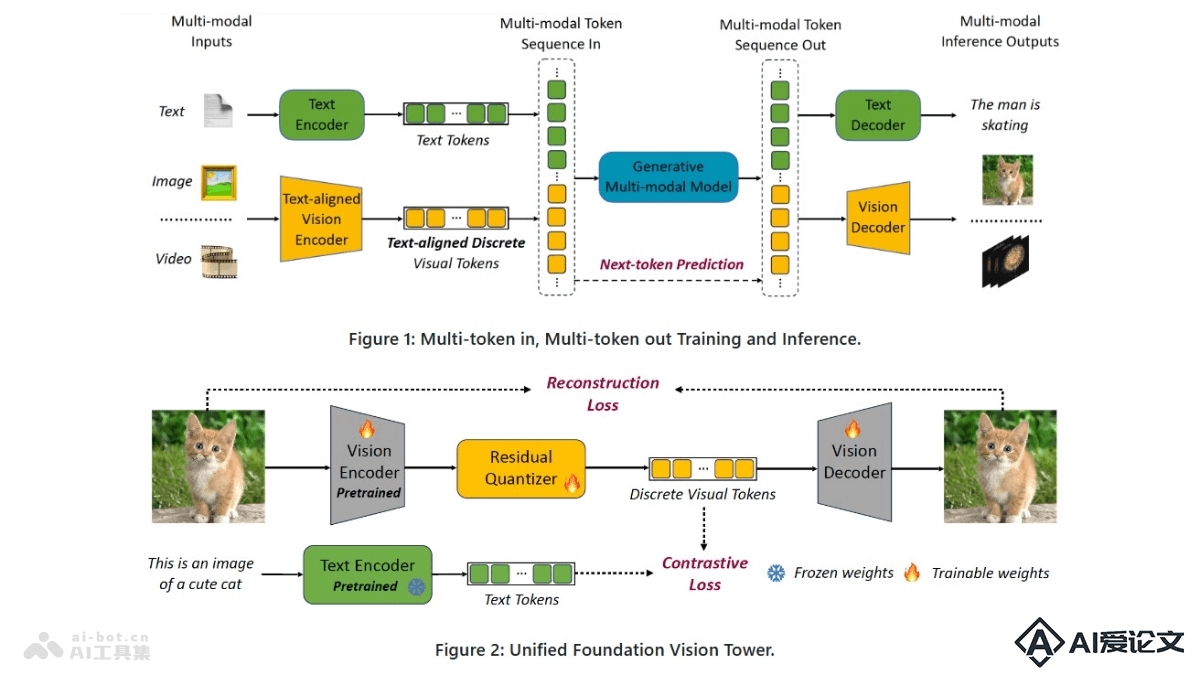


 下载
下载
















