VILA-U是什么
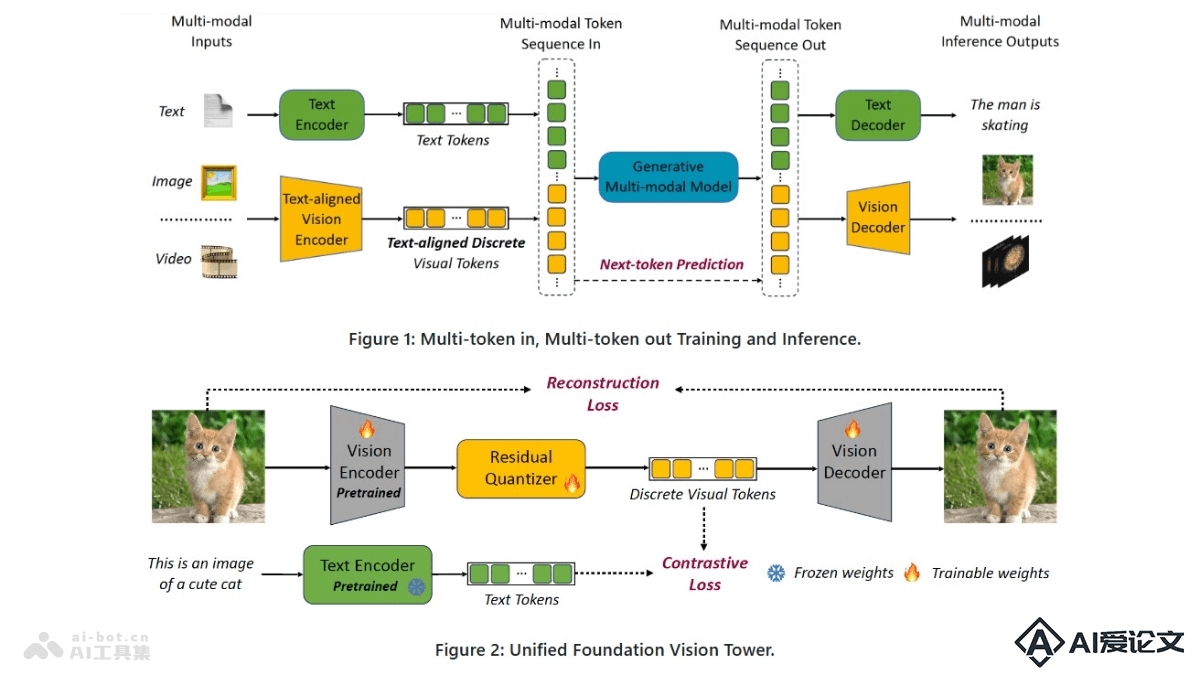
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。模型为多模态任务提供高效的解决方案,无需依赖额外的组件,如扩散模型。

来源:爱论文 时间:2025-02-13 17:19:24
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。模型为多模态任务提供高效的解决方案,无需依赖额外的组件,如扩散模型。
相关资讯
更多+
VILA-U是集成视频、图像、语言理解和生成的统一基础模型。基于单一的自回归下一个标记预测框架处理理解和生成任务,简化模型结构,在视觉语言理解和生成方面实现接近最先进水平的性能。VILA-U的成功归因于在预训练期间将离散视觉标记与文本输入对齐的能力,及自回归图像生成技术,后者能在高质量数据集上达到与扩散模型相似的图像质量。
AI教程资讯
2023-04-14
Video-XL是北京智源人工智能研究院联合上海交大、中国人民大学、中科院、北邮和北大的研究人员共同推出的专为小时级视频理解设计的超长视觉理解模型。基于视觉上下文潜在总结技术将视觉信息压缩成紧凑的形式,提高处理效率、减少信息丢失。
AI教程资讯
2023-04-14
Embed3是Cohere公司推出的行业领先的多模态AI搜索模型,能从文本和图像生成嵌入向量,帮助企业快速准确地搜索复杂报告、产品目录和设计文件等多模态资产。Embed3将数据转换为数值表示,比较相似性和差异性,实现智能搜索,支持超过100种语言,适于全球客户。
AI教程资讯
2023-04-14
DriveDreamer4D是用在提升自动驾驶场景4D重建质量的框架,基于世界模型先验增强4D驾驶场景的表示。框架能基于真实世界的驾驶数据合成新的轨迹视频,用明确结构化条件控制前景和背景元素的时空一致性,确保生成的数据严格遵守交通约束。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+