GTA是什么
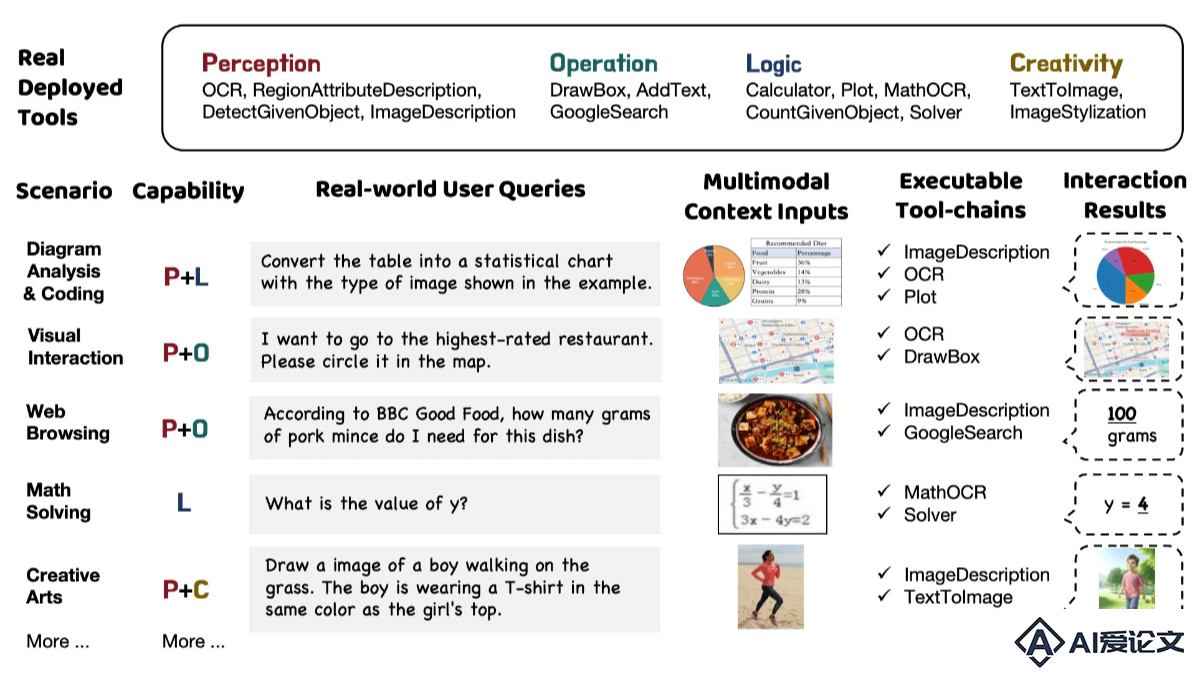
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实部署的工具和多模态输入输出,建立一个全面、细粒度的评估框架,有效衡量LLMs在复杂场景下的工具使用能力。GTA包含229个人类设计的问题,覆盖感知、操作、逻辑和创造力等多个类别,要求模型推理合适的工具,规划操作步骤,解决现实世界中的复杂任务。
来源:爱论文 时间:2025-02-11 09:57:28
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实部署的工具和多模态输入输出,建立一个全面、细粒度的评估框架,有效衡量LLMs在复杂场景下的工具使用能力。GTA包含229个人类设计的问题,覆盖感知、操作、逻辑和创造力等多个类别,要求模型推理合适的工具,规划操作步骤,解决现实世界中的复杂任务。
 相关资讯
更多+
相关资讯
更多+
GTA(a benchmark for General Tool Agents)是上海交通大学和上海AI实验室共同推出的基准测试,评估大型语言模型(LLMs)在真实世界场景中调用工具的能力。GTA基于提供真实的用户问题、真实部署的工具和多模态输入输出,建立一个全面、细粒度的评估框架,有效衡量LLMs在复杂场景下的工具使用能力。
AI教程资讯
 2023-04-14
2023-04-14

VQAScore是CMU和Meta联合推出的评估方法,基于视觉问答(VQA)模型衡量由文本提示生成的图像质量。VQAScore用计算模型对“Does this figure show {text}?”这一问题回答“是”的概率,评估图像与文本提示的对齐程度。VQAScore的核心优势在于无需额外人类标注,直接用现有的VQA模型,用概率值的形式提供更精确的评估结果,超越传统评估指标如CLIPScore
AI教程资讯
2023-04-14
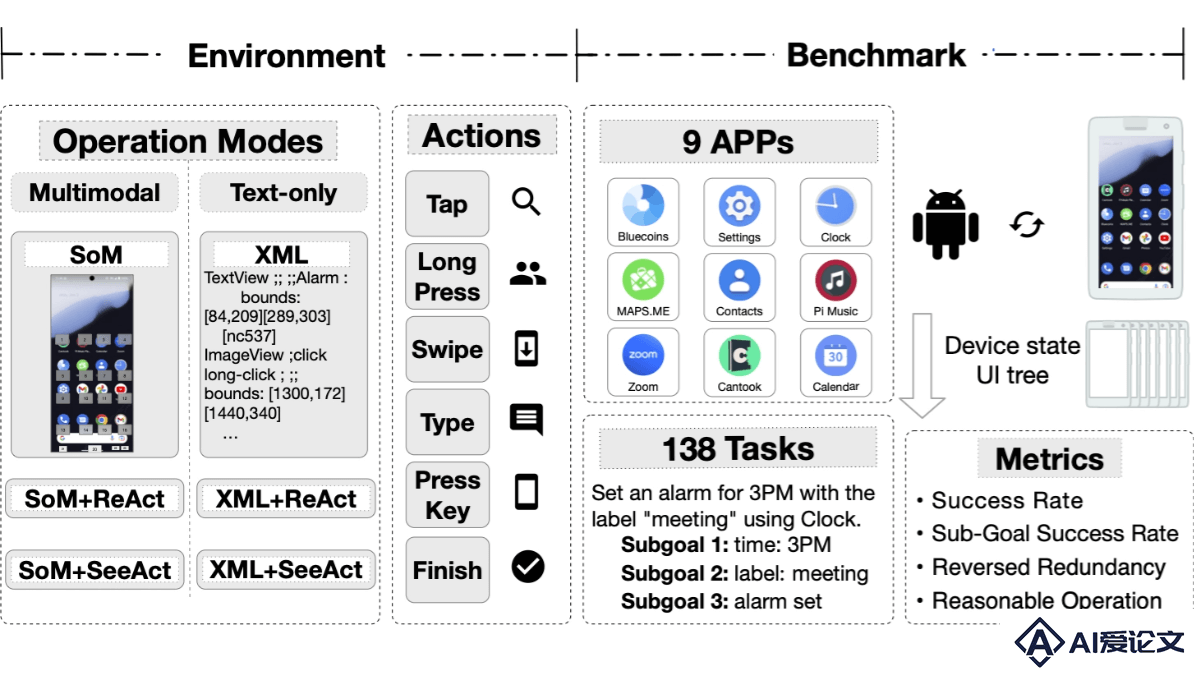
AndroidLab是用在训练和系统评估Android自主代理的框架,集成文本和图像模态操作环境,统一行动空间和可重现基准测试。AndroidLab支持大型语言模型和多模态模型,包含138个任务,覆盖九个应用。基于AndroidLab,开发Android指令数据集,提升开源模型的成功率。
AI教程资讯
2023-04-14

Recraft V3是Recraft公司推出的AI文本到图像生成模型,在Hugging Face的文本到图像模型排行榜上以1172的ELO评分荣获第一。模型具有高质量的图像生成和先进的设计控制功能,支持用户精确定位文本和元素,定制品牌风格和颜色。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载