StableV2V是什么
StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。

来源:爱论文 时间:2025-02-05 12:24:54
StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。
 相关资讯
更多+
相关资讯
更多+
StableV2V是中国科技大学推出的开源视频编辑项目,基于文本、草图、图片等输入实现视频中物体的精准编辑和替换。项目用形状一致的编辑范式,基于三个主要组件:Prompted First-frame Editor(PFE)、Iterative Shape Aligner(ISA)和Conditional Image-to-video Generator(CIG),确保编辑内容与原始视频动作和深度信息一致,生成自然流畅的编辑视频。
AI教程资讯
 2023-04-14
2023-04-14

Halo是开源的DIY健康追踪项目,基于低成本的智能戒指和开源软件,让用户构建自己的私人健康监测应用。Halo支持活动追踪、心率监测、睡眠分析等功能,且完全尊重用户隐私。基于Halo,用户能深入了解自己的健康数据,享受定制化的健康追踪体验。
AI教程资讯
2023-04-14
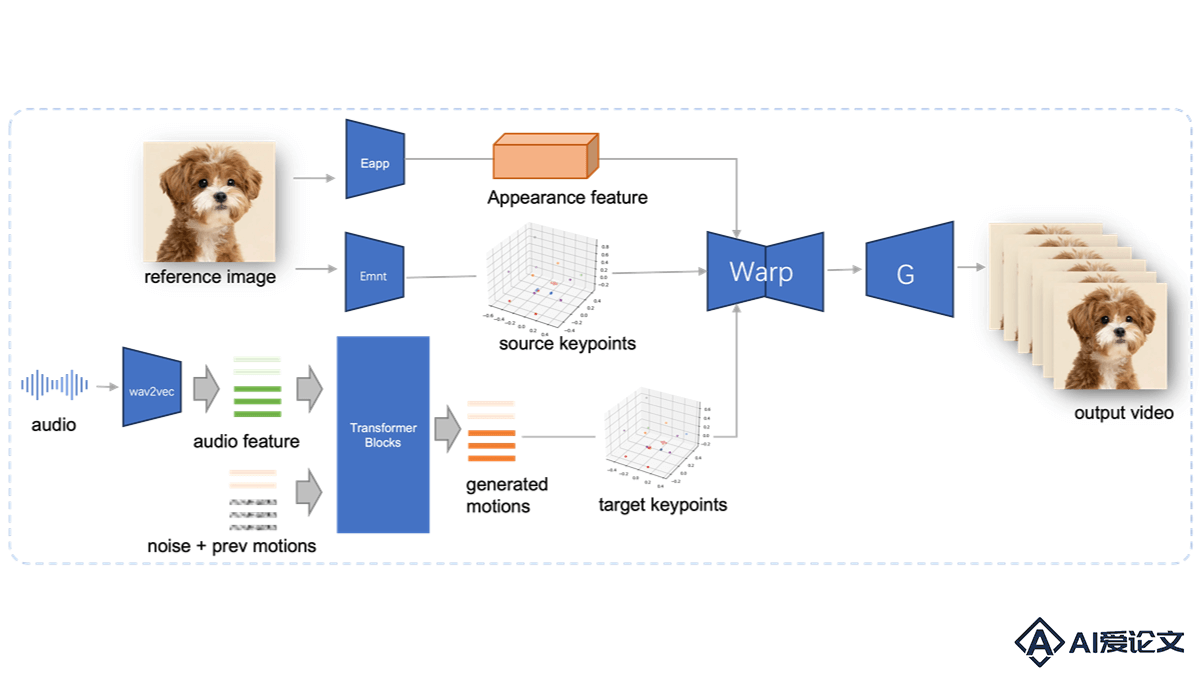
JoyVASA是京东健康国际公司开源的音频驱动的数字人头项目,基于扩散模型技术,根据音频信号生成与音频同步的面部动态和头部运动。JoyVASA能实现人物的唇形同步和表情控制,还扩展到动物头像的动画生成,在多语种支持和跨物种动画化方面具有广泛的应用潜力。
AI教程资讯
2023-04-14

TIP-I2V是大规模真实文本和图像提示数据集,用在图像到视频生成领域。TIP-I2V包含超过170万独特的用户文本和图像提示,及五种SOTA图生视频模型生成的相应视频。数据集能推动更好、更安全的图像到视频模型的发展,帮助研究人员分析用户偏好,评估模型性能,解决图像到视频模型引起的错误信息问题。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















