FlipSketch是什么
FlipSketch 是萨里大学推出的创新系统,能将静态绘图转变为文本引导的草图动画。技术基于三个关键创新实现:微调草图风格的帧生成、用噪声细化保持输入草图视觉完整性的参考帧机制,及在不失去视觉一致性的情况下实现流畅运动的双注意力合成。与传统矢量动画不同,FlipSketch 支持动态草图变换,捕捉传统动画的自由表现力,让草图动画制作变得简单直观,同时保持手绘动画的艺术性。

来源:爱论文 时间:2025-02-02 23:29:29
FlipSketch 是萨里大学推出的创新系统,能将静态绘图转变为文本引导的草图动画。技术基于三个关键创新实现:微调草图风格的帧生成、用噪声细化保持输入草图视觉完整性的参考帧机制,及在不失去视觉一致性的情况下实现流畅运动的双注意力合成。与传统矢量动画不同,FlipSketch 支持动态草图变换,捕捉传统动画的自由表现力,让草图动画制作变得简单直观,同时保持手绘动画的艺术性。
 相关资讯
更多+
相关资讯
更多+
FlipSketch 是萨里大学推出的创新系统,能将静态绘图转变为文本引导的草图动画。技术基于三个关键创新实现:微调草图风格的帧生成、用噪声细化保持输入草图视觉完整性的参考帧机制,及在不失去视觉一致性的情况下实现流畅运动的双注意力合成。
AI教程资讯
 2023-04-14
2023-04-14
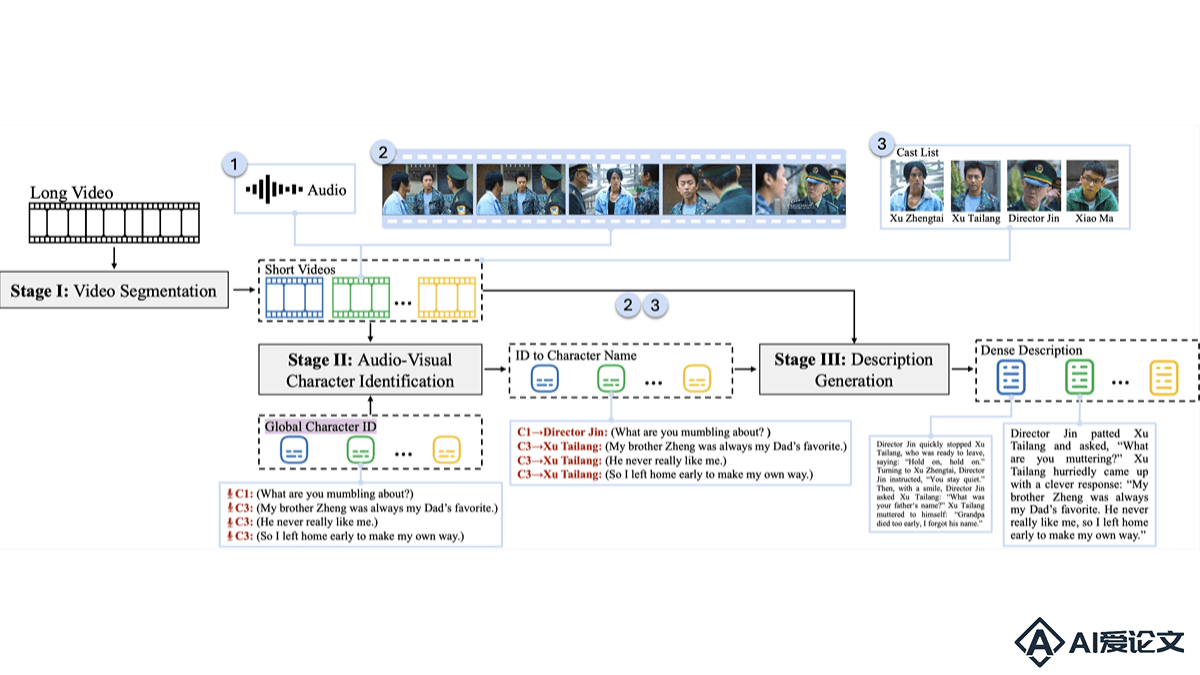
StoryTeller是字节跳动、上海交通大学和北京大学共同推出的系统,能基于音频视觉角色识别技术改善长视频描述的质量和一致性。系统结合低级视觉概念和高级剧情信息,生成详细且连贯的视频描述。StoryTeller由视频分割、音频视觉角色识别和描述生成三个主要模块组成,能有效处理数分钟长的视频。
AI教程资讯
2023-04-14

DELIFT(Data Efficient Language model Instruction Fine-Tuning)是新型算法,用在优化大型语言模型(LLMs)在指令调优、任务特定微调和持续微调三个关键阶段的数据选择。基于成对效用度量和次模优化技术,高效选择多样化和最优的数据子集,减少计算资源消耗,同时保持或提升模型性能。
AI教程资讯
2023-04-14

HART(Hybrid Autoregressive Transformer)是麻省理工学院研究团队推出的自回归视觉生成模型。能直接生成1024×1024像素的高分辨率图像,质量媲美扩散模型。HART基于混合Tokenizer技术,将自动编码器的连续潜在表示分解为离散token和连续token,其中离散token负责捕捉图像的主要结构,连续token专注于细节。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















