DELIFT是什么
DELIFT(Data Efficient Language model Instruction Fine-Tuning)是基于高效数据优化语言模型指令微调,一种新颖的算法,用在优化大型语言模型(LLMs)在指令调优、任务特定微调和持续微调三个关键阶段的数据选择。基于成对效用度量和次模优化技术,高效选择多样化和最优的数据子集,减少计算资源消耗,同时保持或提升模型性能。实验显示,DELIFT能将微调数据量减少70%,显著节省计算资源,且效果优于现有方法。

来源:爱论文 时间:2025-02-02 22:38:00
DELIFT(Data Efficient Language model Instruction Fine-Tuning)是基于高效数据优化语言模型指令微调,一种新颖的算法,用在优化大型语言模型(LLMs)在指令调优、任务特定微调和持续微调三个关键阶段的数据选择。基于成对效用度量和次模优化技术,高效选择多样化和最优的数据子集,减少计算资源消耗,同时保持或提升模型性能。实验显示,DELIFT能将微调数据量减少70%,显著节省计算资源,且效果优于现有方法。
 相关资讯
更多+
相关资讯
更多+
DELIFT(Data Efficient Language model Instruction Fine-Tuning)是新型算法,用在优化大型语言模型(LLMs)在指令调优、任务特定微调和持续微调三个关键阶段的数据选择。基于成对效用度量和次模优化技术,高效选择多样化和最优的数据子集,减少计算资源消耗,同时保持或提升模型性能。
AI教程资讯
 2023-04-14
2023-04-14

HART(Hybrid Autoregressive Transformer)是麻省理工学院研究团队推出的自回归视觉生成模型。能直接生成1024×1024像素的高分辨率图像,质量媲美扩散模型。HART基于混合Tokenizer技术,将自动编码器的连续潜在表示分解为离散token和连续token,其中离散token负责捕捉图像的主要结构,连续token专注于细节。
AI教程资讯
2023-04-14
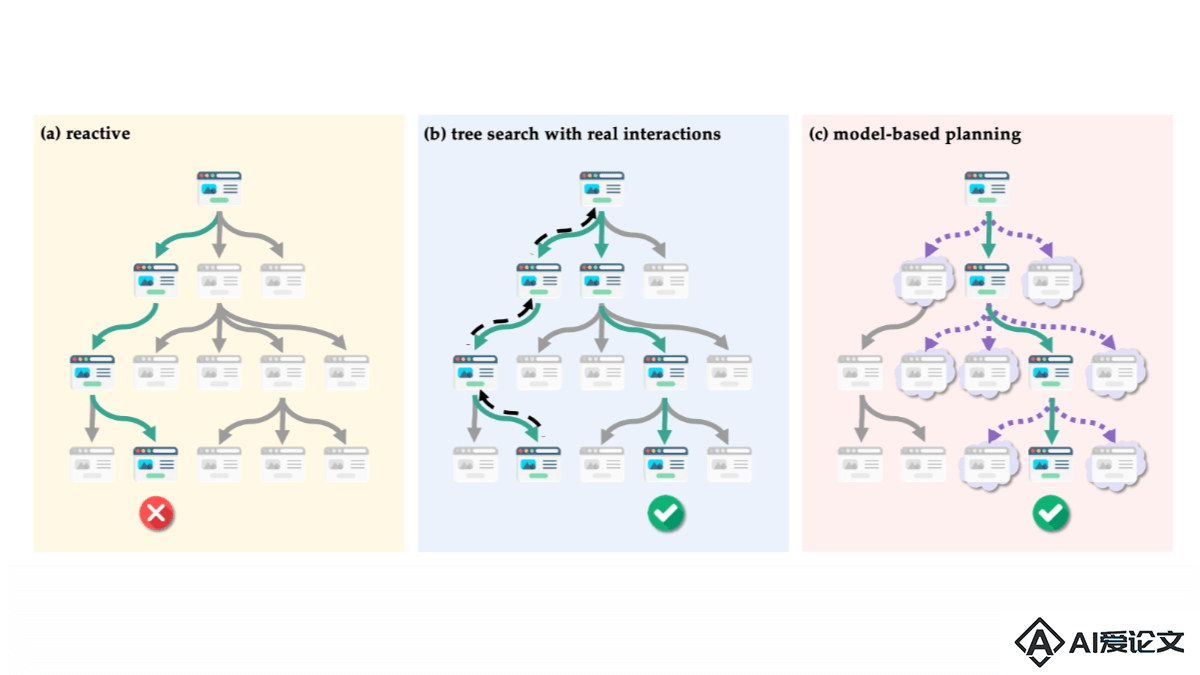
WebDreamer是俄亥俄州立大学和Orby AI研究团队推出的基于模型规划的网络智能体,基于大型语言模型(LLMs),特别是GPT-4o,作为世界模型预测网站上的交互结果。框架模拟可能的用户行为和结果,帮助网络代理在复杂的网络环境中进行有效的规划和决策。
AI教程资讯
2023-04-14
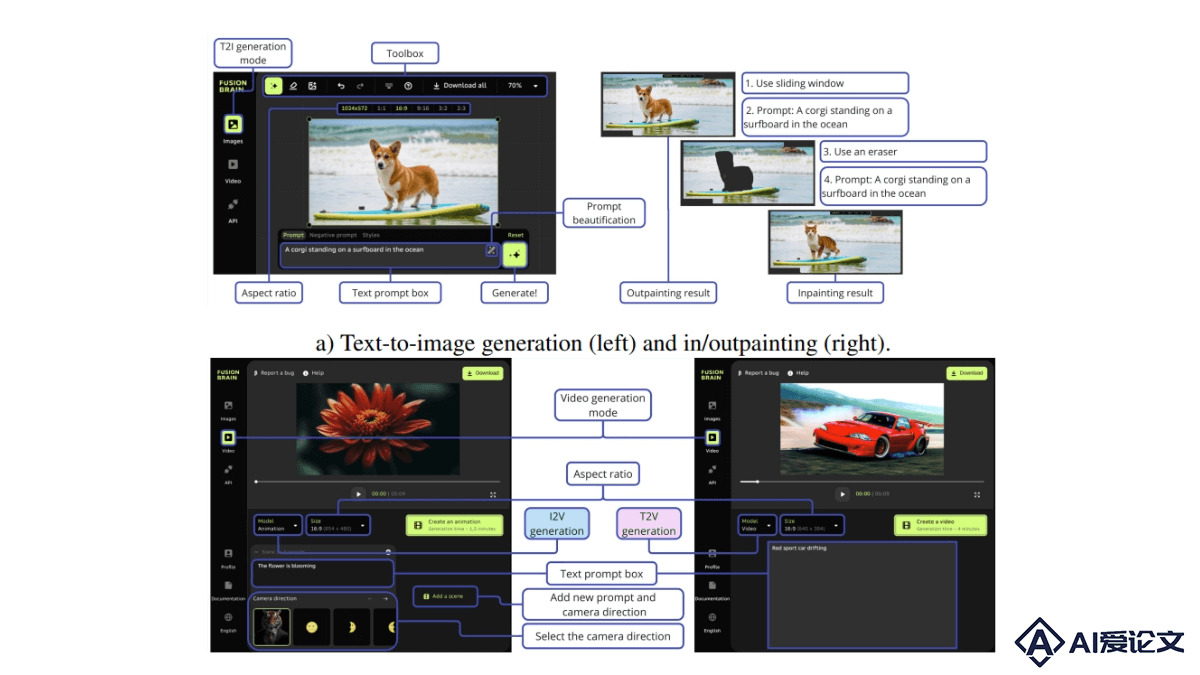
Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,以高质量和逼真度在图像合成领域脱颖而出。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复 扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















