WebDreamer是什么
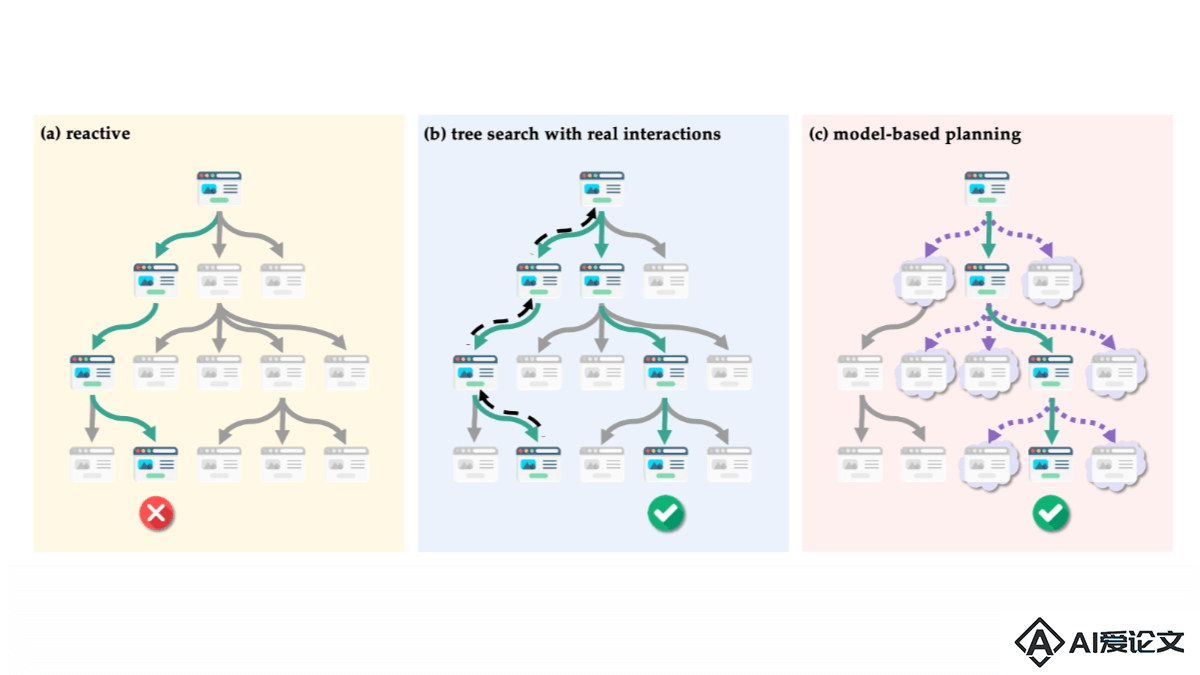
WebDreamer是俄亥俄州立大学和Orby AI研究团队推出的基于模型规划的网络智能体,基于大型语言模型(LLMs),特别是GPT-4o,作为世界模型预测网站上的交互结果。框架模拟可能的用户行为和结果,帮助网络代理在复杂的网络环境中进行有效的规划和决策。WebDreamer的核心在于“做梦”概念,在实际采取行动前,用LLM预测每个可能步骤的结果,并选择最有可能实现目标的行动。这种方法提高了智能体的性能和安全性,减少实际网站交互的需求。
来源:爱论文 时间:2025-02-02 21:46:13
WebDreamer是俄亥俄州立大学和Orby AI研究团队推出的基于模型规划的网络智能体,基于大型语言模型(LLMs),特别是GPT-4o,作为世界模型预测网站上的交互结果。框架模拟可能的用户行为和结果,帮助网络代理在复杂的网络环境中进行有效的规划和决策。WebDreamer的核心在于“做梦”概念,在实际采取行动前,用LLM预测每个可能步骤的结果,并选择最有可能实现目标的行动。这种方法提高了智能体的性能和安全性,减少实际网站交互的需求。
 相关资讯
更多+
相关资讯
更多+
WebDreamer是俄亥俄州立大学和Orby AI研究团队推出的基于模型规划的网络智能体,基于大型语言模型(LLMs),特别是GPT-4o,作为世界模型预测网站上的交互结果。框架模拟可能的用户行为和结果,帮助网络代理在复杂的网络环境中进行有效的规划和决策。
AI教程资讯
 2023-04-14
2023-04-14
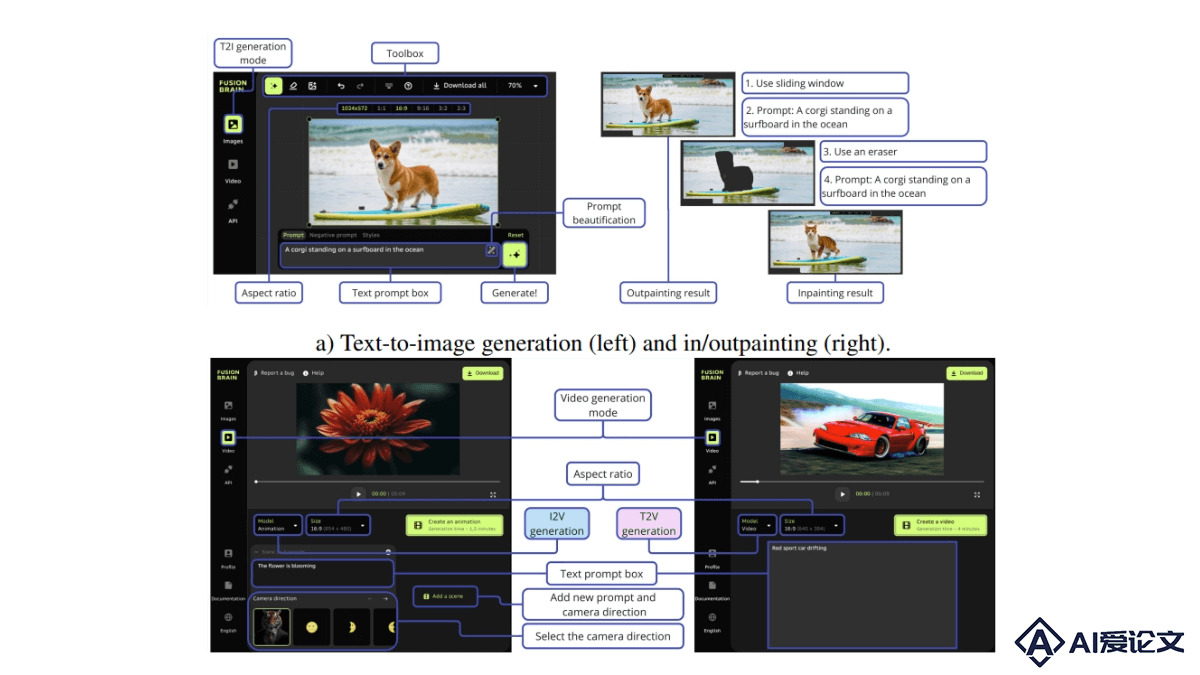
Kandinsky-3是基于潜在扩散模型的文本到图像(T2I)生成框架,以高质量和逼真度在图像合成领域脱颖而出。Kandinsky-3能适应多种图像生成任务,包括文本引导的修复 扩展、图像融合、文本-图像融合及视频生成等。研究者们推出一个简化版本的T2I模型版本,该版本在保持图像质量的同时,将推理速度提高3倍,仅需4步逆向过程即可完成。
AI教程资讯
2023-04-14
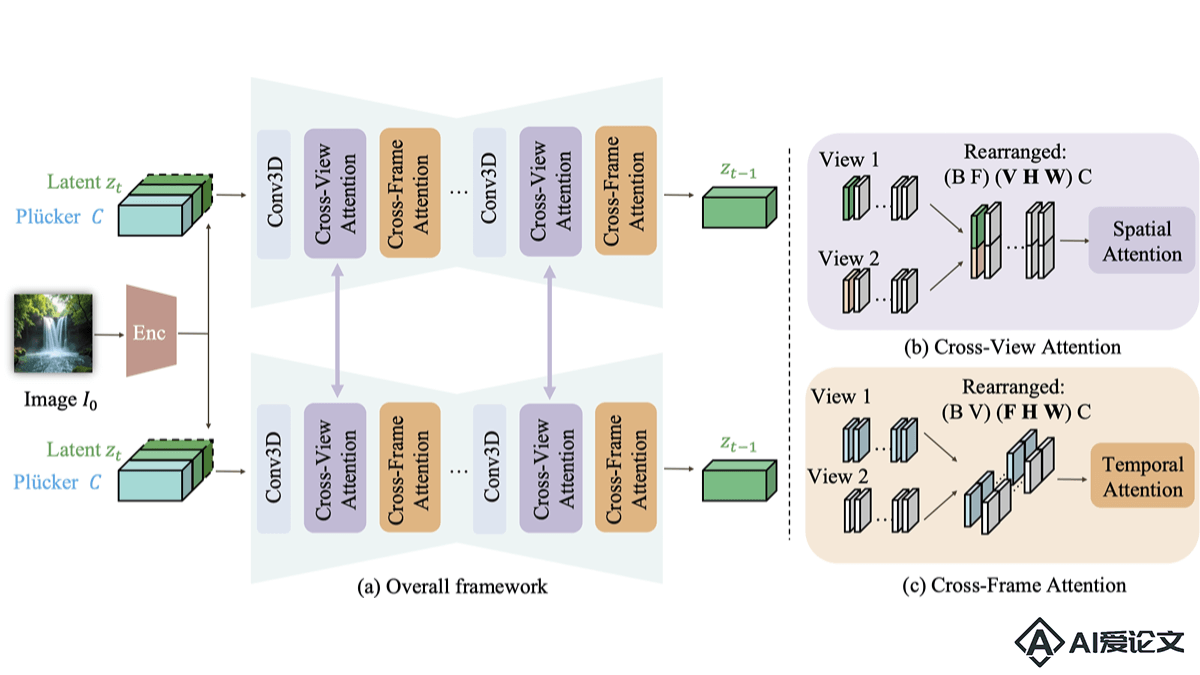
CAVIA是苹果公司、得克萨斯大学奥斯汀分校、谷歌联合推出的多视角视频生成框架,能将单一输入图像转换成多个时空一致的视频序列。框架基于引入视角集成注意力模块,增强视频的视角一致性和时间连贯性,支持用户精确控制相机运动,同时保留对象运动。
AI教程资讯
2023-04-14

Flex3D是由Meta的GenAI团队和牛津大学研究团队推出的创新的两阶段3D生成框架,能基于任意数量的高质量输入视图,解决从文本、单张图片或稀疏视图图像生成高质量3D内容的挑战。第一阶段,基于微调的多视图和视频扩散模型生成多样化的候选视图,用视图选择机制确保只有高质量和一致的视图被用于重建。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















