SlideChat是什么
SlideChat是上海AI实验室、厦门大学、华东师范大学等机构推出的,首个能理解千兆像素级别全切片图像的视觉语言助手。SlideChat能生成详尽的全切片图像描述,针对多样化的病理场景提供具有上下文关联的复杂指令响应。基于训练,SlideChat在多个临床任务中展现出卓越的性能,包括显微镜检查、诊断等。SlideChat用大规模的多模态指令数据集SlideInstruction和评估基准SlideBench,后者包含多个子集,覆盖21种不同的临床任务。

来源:爱论文 时间:2025-02-02 16:51:44
SlideChat是上海AI实验室、厦门大学、华东师范大学等机构推出的,首个能理解千兆像素级别全切片图像的视觉语言助手。SlideChat能生成详尽的全切片图像描述,针对多样化的病理场景提供具有上下文关联的复杂指令响应。基于训练,SlideChat在多个临床任务中展现出卓越的性能,包括显微镜检查、诊断等。SlideChat用大规模的多模态指令数据集SlideInstruction和评估基准SlideBench,后者包含多个子集,覆盖21种不同的临床任务。
 相关资讯
更多+
相关资讯
更多+
SlideChat是上海AI实验室、厦门大学、华东师范大学等机构推出的,首个能理解千兆像素级别全切片图像的视觉语言助手。SlideChat能生成详尽的全切片图像描述,并针对多样化的病理场景提供具有上下文关联的复杂指令响应。基于训练,SlideChat在多个临床任务中展现出卓越的性能,包括显微镜检查、诊断等。
AI教程资讯
 2023-04-14
2023-04-14

Fugatto是英伟达(NVIDIA)推出的音频合成和转换模型,全称为"Foundational Generative Audio Transformer Opus 1"。模型能根据文本提示生成音频或视频,接收并修改现有的音频文件。Fugatto模型具有强大的能力,例如将钢琴旋律转换成人声演唱版本,或者改变口语录音中的口音和情绪表达。
AI教程资讯
2023-04-14
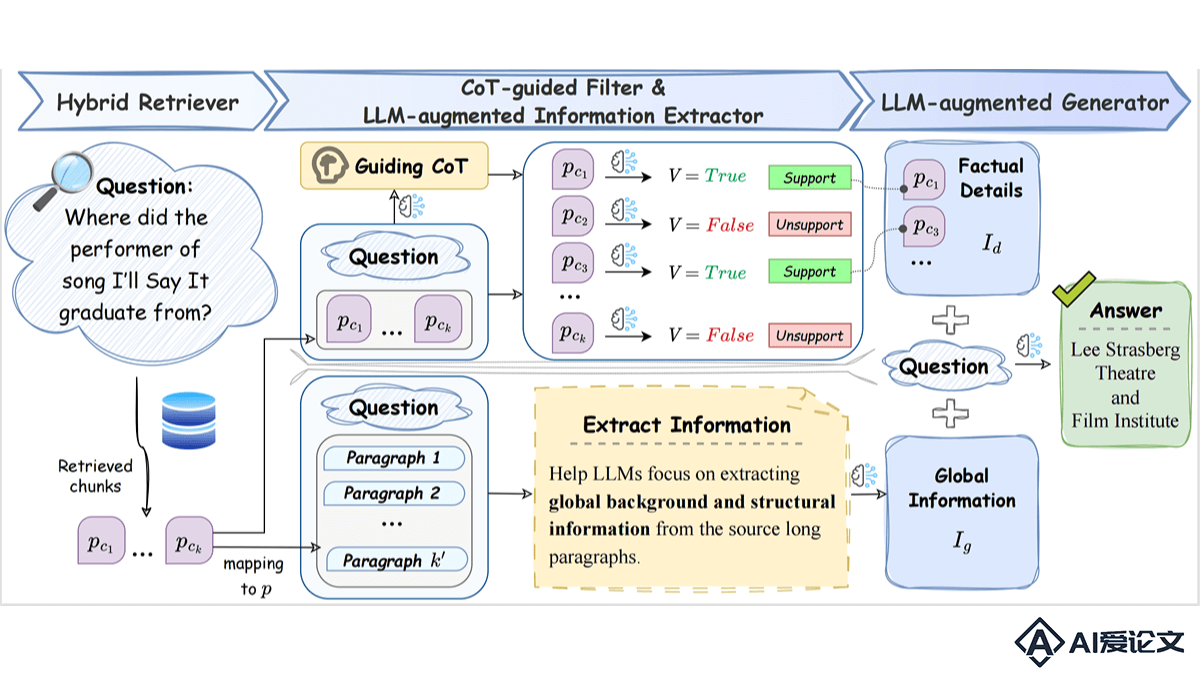
LongRAG是清华大学、中国科学院和智谱的研究团队推出的,面向长文本问答(LCQA)的双视角鲁棒检索增强生成(RAG)框架。基于混合检索器、LLM增强信息提取器、CoT引导过滤器和LLM增强生成器四个组件,有效解决长文本问答中的全局上下文理解和事实细节识别难题。
AI教程资讯
2023-04-14

Illustrious是开源的文本到图像动漫图像生成模型,是Onoma AI Research推出的。基于优化批量大小、dropout控制、训练图像分辨率和多级标题等关键方法,实现高分辨率、动态色域和高还原能力的图像生成。模型在动画风格的表现上超越如Stable Diffusion XL和其他一些广泛使用的动漫图像生成模型,并支持易于定制和个性化的开源特性。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















