SongCreator是什么
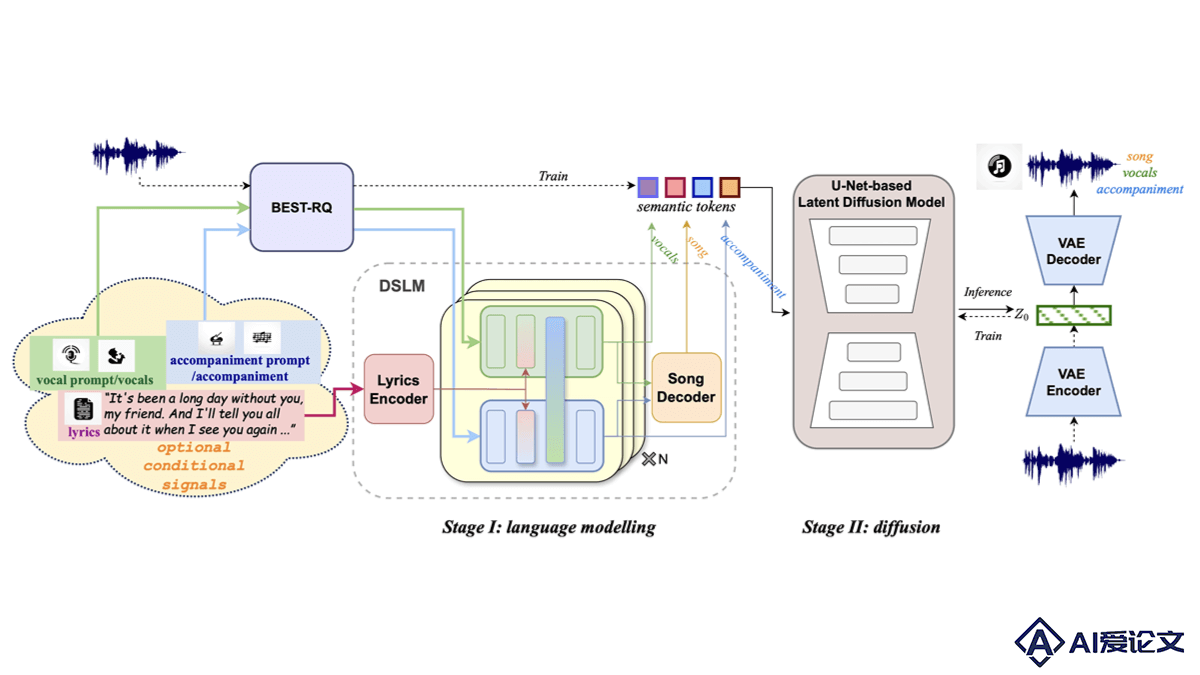
SongCreator是清华大学深圳国际研究生院、香港中文大学等机构推出的AI音乐生成模型,能从歌词出发生成包含声乐和伴奏的完整歌曲。基于双序列语言模型(DSLM)和注意力掩码策略,理解和生成各种相关的歌曲生成任务,包括编辑和生成。SongCreator在多项任务中表现出色,特别是在歌词到歌曲和歌词到声乐的任务上,能独立控制生成歌曲中声乐和伴奏的声学条件。
来源:爱论文 时间:2025-02-01 21:34:57
SongCreator是清华大学深圳国际研究生院、香港中文大学等机构推出的AI音乐生成模型,能从歌词出发生成包含声乐和伴奏的完整歌曲。基于双序列语言模型(DSLM)和注意力掩码策略,理解和生成各种相关的歌曲生成任务,包括编辑和生成。SongCreator在多项任务中表现出色,特别是在歌词到歌曲和歌词到声乐的任务上,能独立控制生成歌曲中声乐和伴奏的声学条件。
 相关资讯
更多+
相关资讯
更多+
SongCreator是清华大学深圳国际研究生院、香港中文大学等机构推出的AI音乐生成模型,能从歌词出发生成包含声乐和伴奏的完整歌曲。
AI教程资讯
 2023-04-14
2023-04-14

Teacher2Task是谷歌团队推出的多教师学习框架,引入教师特定的输入标记和重新构思训练过程,消除对手动聚合启发式方法的需求。框架不依赖聚合标签,将训练数据转化为N+1个任务,包括N个辅助任务预测每位教师的标记风格,及一个主要任务关注真实标签。
AI教程资讯
2023-04-14

DynaSaur是Adobe Research推出的大型语言模型(LLM)代理框架,突破传统LLM代理系统受限于预定义动作集合的限制。框架支持代理动态创建和组合动作,基于生成和执行Python代码与环境互动,实现更灵活的问题解决。DynaSaur能积累生成的动作,构建可重用的函数库,提高未来任务的效率和适应性。
AI教程资讯
2023-04-14

Takin AudioLLM是喜马拉雅Everest团队推出的一系列高质量零样本语音生成模型,包括Takin TTS、Takin VC和Takin Morphing。模型用最新的大型语言模型技术,专注于有声书制作,能生成接近真人的高保真语音,支持个性化定制。Takin TTS用在生成富有表现力的音频内容,Takin VC负责声音的音色转换,Takin Morphing提供声音风格转换功能。
AI教程资讯
2023-04-14
最新录入
更多+
 Morph Studio
Morph Studio
学术论文 丨 9.9MB
 下载
下载
 Gatekeep
Gatekeep
学术论文 丨 9.9MB
下载
 DomoAI
DomoAI
学术论文 丨 9.9MB
下载
 Google Vids
Google Vids
学术论文 丨 9.9MB
下载
 Spikes Studio
Spikes Studio
学术论文 丨 9.9MB
下载
 一起剪
一起剪
学术论文 丨 9.9MB
下载
热门推荐
更多+
AI工具推荐
更多+











