ShowUI是什么
ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。ShowUI用小规模但高质量的指令跟随数据集,用256K数据实现75.1%的零样本截图定位准确率,训练速度提升1.4倍,展现出在GUI视觉代理领域的潜力。

来源:爱论文 时间:2025-01-31 19:52:30
ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。ShowUI用小规模但高质量的指令跟随数据集,用256K数据实现75.1%的零样本截图定位准确率,训练速度提升1.4倍,展现出在GUI视觉代理领域的潜力。
 相关资讯
更多+
相关资讯
更多+
ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。
AI教程资讯
 2023-04-14
2023-04-14

NVLM是NVIDIA推出的前沿多模态大型语言模型(LLMs),在视觉-语言任务上达到与顶尖专有模型(如GPT-4o)和开放访问模型(如Llama 3-V 405B和InternVL 2)相匹敌的性能。NVLM 1 0家族包括三种架构:仅解码器模型NVLM-D、基于交叉注意力的模型NVLM-X和混合架构NVLM-H。
AI教程资讯
2023-04-14
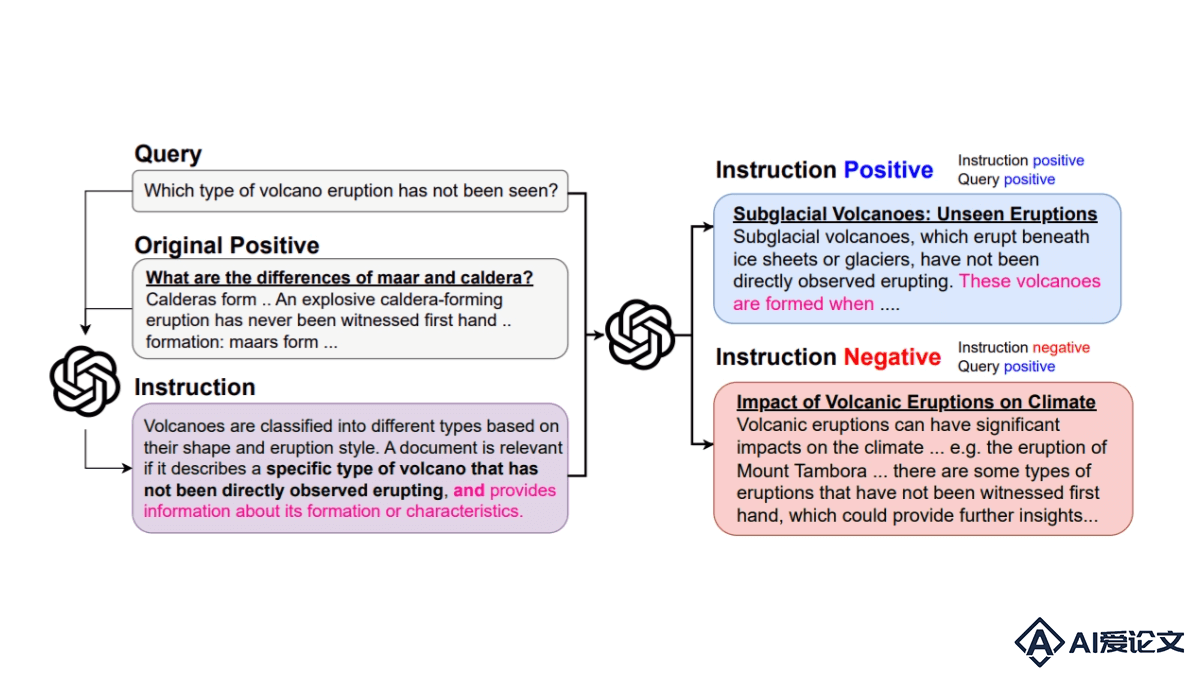
Promptriever 是约翰斯·霍普金斯大学和Samaya AI联合推出的新型检索模型,能像语言模型一样接受自然语言提示,用直观的方式响应用户的搜索需求。Promptriever 基于 MS MARCO 数据集的指令训练集进行训练,不仅在标准检索任务上表现出色,还能更有效地遵循详细指令,提高对查询的鲁棒性和检索性能。
AI教程资讯
2023-04-14

LongLLaVA是多模态大型语言模型(MLLM),基于混合架构结合Mamba和Transformer模块,能高效处理大量图像,特别擅长视频理解和高分辨率图像分析。LongLLaVA在单个A100 80GB GPU上能处理近千张图像,同时保持高性能和低内存消耗,在多模态长上下文理解任务中展现出色能力。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















