EMOVA是什么
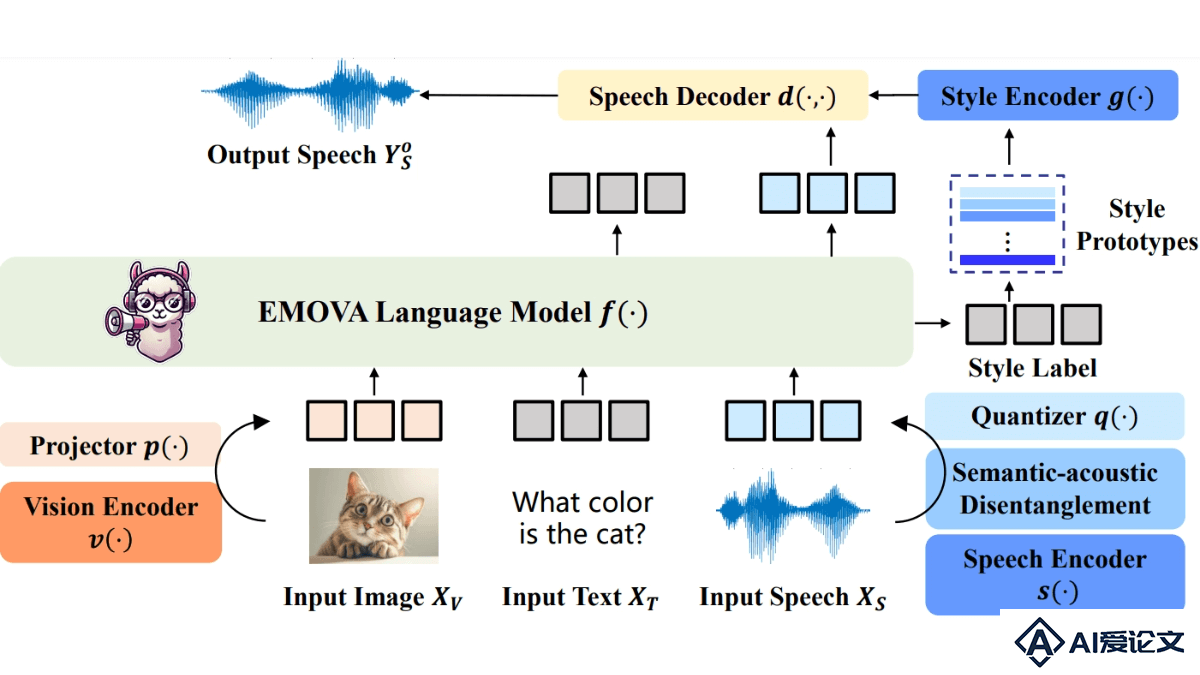
EMOVA(EMotionally Omni-present Voice Assistant)是多模态全能模型,是香港科技大学、香港大学和华为诺亚方舟实验室等机构共同推出的。EMOVA能处理图像、文本和语音模态,实现能看、能听、会说的全模态交互。EMOVA基于语义声学分离技术和轻量级情感控制模块,支持情感丰富的语音对话,让得人机交互更加自然和人性化。EMOVA在视觉语言和语音任务中均展现出优越性能,为AI领域提供新的实现思路,推动情感交互的发展。
来源:爱论文 时间:2025-01-31 16:48:34
EMOVA(EMotionally Omni-present Voice Assistant)是多模态全能模型,是香港科技大学、香港大学和华为诺亚方舟实验室等机构共同推出的。EMOVA能处理图像、文本和语音模态,实现能看、能听、会说的全模态交互。EMOVA基于语义声学分离技术和轻量级情感控制模块,支持情感丰富的语音对话,让得人机交互更加自然和人性化。EMOVA在视觉语言和语音任务中均展现出优越性能,为AI领域提供新的实现思路,推动情感交互的发展。
 相关资讯
更多+
相关资讯
更多+

EMOVA(EMotionally Omni-present Voice Assistant)是多模态全能模型,是香港科技大学、香港大学和华为诺亚方舟实验室等机构共同推出的。EMOVA能处理图像、文本和语音模态,实现能看、能听、会说的全模态交互。
AI教程资讯
 2023-04-14
2023-04-14

OminiControl是高度通用且参数高效的图像生成框架,为扩散变换器模型如FLUX 1设计,实现对图像生成过程的精细控制。OminiControl支持主题驱动控制和空间控制,例如边缘引导和绘画生成,仅需在基础模型中增加0 1%的参数。
AI教程资讯
2023-04-14
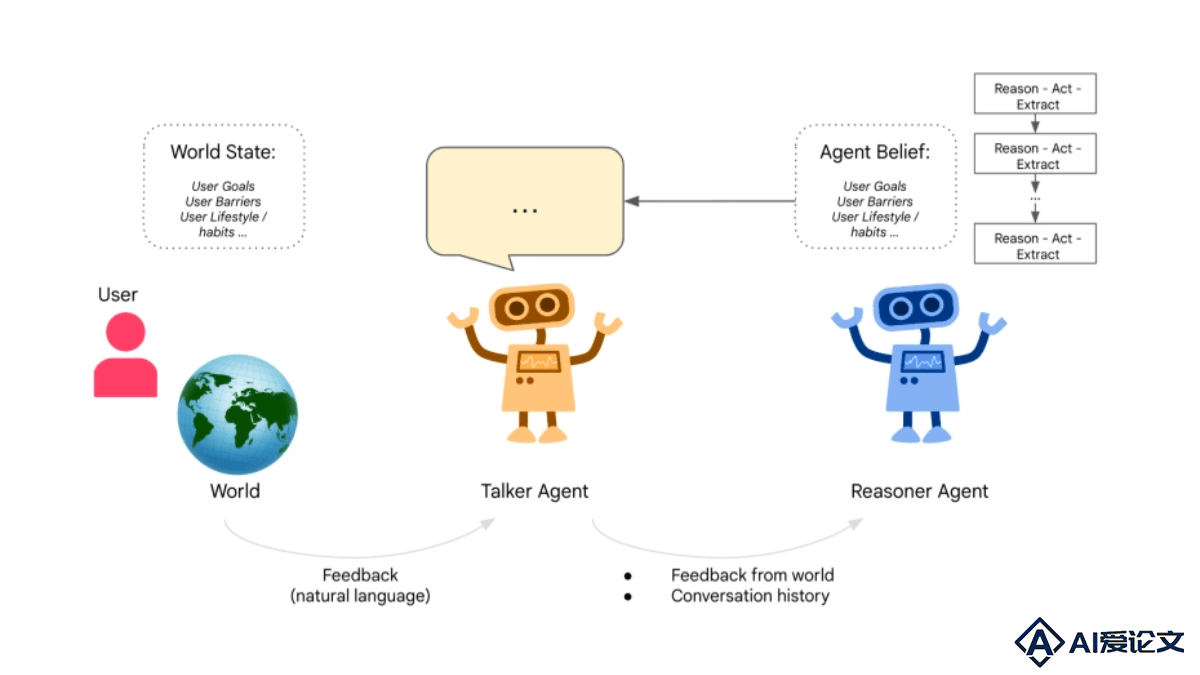
Talker-Reasoner是谷歌DeepMind推出的AI代理架构,借鉴人类的认知理论,将代理分为两个模块:Talker和Reasoner。Talker模拟人类的快速直觉思维(System 1),处理即时对话和反应;Reasoner模仿缓慢的逻辑推理(System 2),负责复杂的多步规划和决策。
AI教程资讯
2023-04-14

Diffusion Self-Distillation(DSD)是创新的零样本定制图像生成技术,用预训练的文本到图像扩散模型自动生成数据集,并将其微调为能进行文本条件的图像到图像任务的模型。Diffusion Self-Distillation基于生成图像网格和视觉语言模型筛选,创建出高质量的配对数据集,进而在无需人工干预的情况下,实现在任意上下文中对任意实例进行身份保持的定制图像生成。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















