EfficientTAM是什么
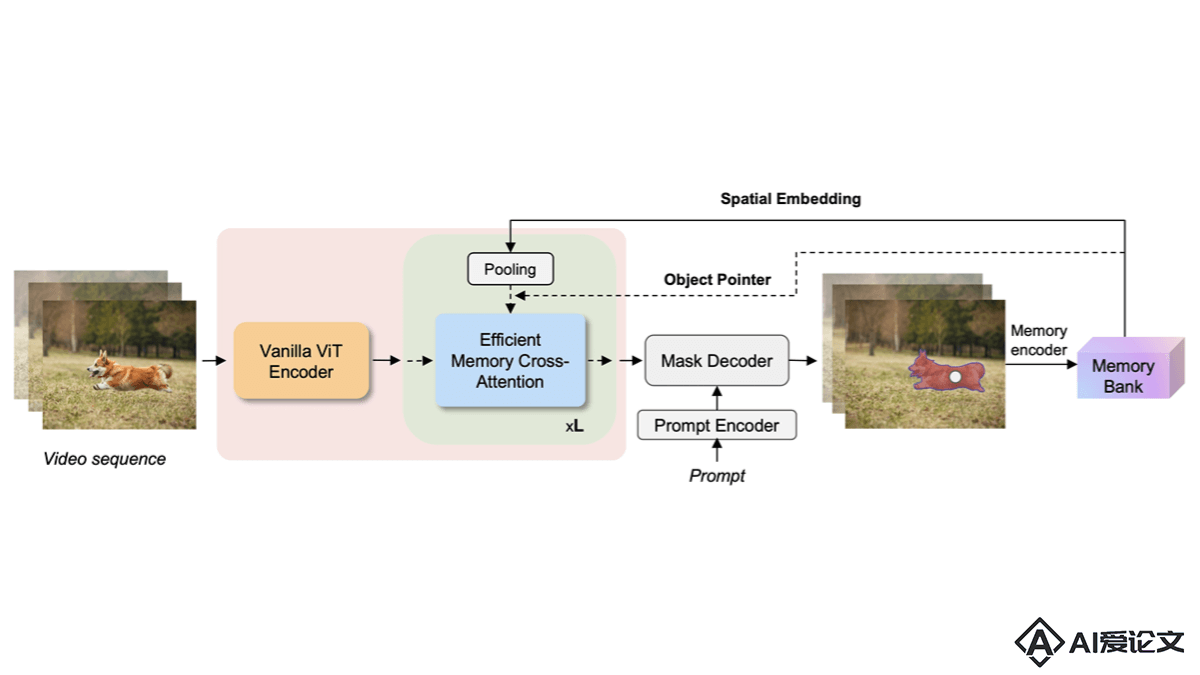
EfficientTAM是Meta AI推出的轻量级视频对象分割和跟踪模型,能解决SAM 2模型在移动设备上部署时的高计算复杂度问题。基于用简单的非层次化Vision Transformer(ViT)作为图像编码器,引入高效的记忆模块降低计算复杂度,实现在保持分割质量的同时减少延迟和模型大小。EfficientTAM在多个视频分割基准测试中表现出与SAM 2相当的性能,具有更快的处理速度和更少的参数,特别适用于移动设备上的视频对象分割应用。
来源:爱论文 时间:2025-01-29 20:38:30
EfficientTAM是Meta AI推出的轻量级视频对象分割和跟踪模型,能解决SAM 2模型在移动设备上部署时的高计算复杂度问题。基于用简单的非层次化Vision Transformer(ViT)作为图像编码器,引入高效的记忆模块降低计算复杂度,实现在保持分割质量的同时减少延迟和模型大小。EfficientTAM在多个视频分割基准测试中表现出与SAM 2相当的性能,具有更快的处理速度和更少的参数,特别适用于移动设备上的视频对象分割应用。
 相关资讯
更多+
相关资讯
更多+
EfficientTAM是Meta AI推出的轻量级视频对象分割和跟踪模型,能解决SAM 2模型在移动设备上部署时的高计算复杂度问题。基于用简单的非层次化Vision Transformer(ViT)作为图像编码器,并引入高效的记忆模块降低计算复杂度,实现在保持分割质量的同时减少延迟和模型大小。
AI教程资讯
 2023-04-14
2023-04-14

Amazon Nova 是亚马逊云服务(AWS)推出的新一代AI基础模型系列,提供行业领先的性能和成本效益。该系列包括专门处理文本的Amazon Nova Micro、多模态的Amazon Nova Lite 和Amazon Nova Pro,及即将推出的Amazon Nova Premier。除此之外,还有图像生成模型Amazon Nova Canvas 和视频生成模型Amazon Nova Reel。
AI教程资讯
2023-04-14

HunyuanVideo是腾讯开源的视频生成模型,拥有130亿参数,是目前参数量最大的开源视频模型之一。HunyuanVideo具备物理模拟、高文本语义还原度、动作一致性和电影级画质等特性,并能生成带有背景音乐的视频。
AI教程资讯
2023-04-14

Lobe Vidol是开源的数字人创作平台,让每个人都能轻松创建和互动自己的虚拟偶像。Lobe Vidol提供流畅的对话体验、背景设置、动作姿势库、优雅的用户界面、角色编辑、MMD舞蹈支持、PMX舞台加载、触摸响应功能及角色和舞蹈市场。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















