TeleAI 视频生成大模型是什么
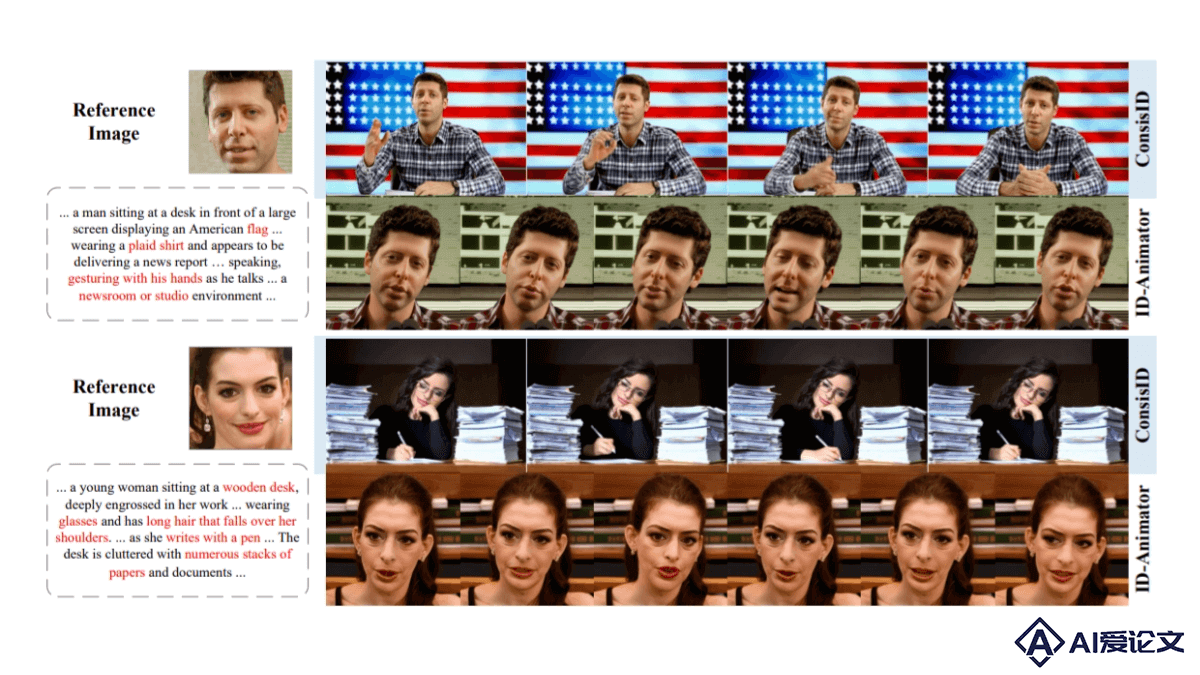
TeleAI 视频生成大模型是中国电信AI研究院推出的视频生成模型,基于两阶段生成框架:先根据文本描述创建分镜头草图,再基于草图生成视频。TeleAI 视频生成大模型能确保视频中主体外观的一致性,精确控制动作和外观,实现复杂场景和动作的流畅过渡,遵循物理规律和常识。VAST技术在视频生成质量的多个维度上表现出色,特别是在主体一致性和遵循物理规律方面,在 VBench 测试中的人体动作和物体分类两项指标都拿下满分,为AI短剧创作提供强大的技术支持。

TeleAI 视频生成大模型的主要功能
视频生成:根据文本描述生成视频内容,保持主体外观的一致性。分镜头绘制:将文本描述转换成包含人物姿势、场景分布等关键信息的分镜头。精确控制:控制视频中主体的位置、动作和外观,实现复杂动作的精确模拟。遵循物理规律:确保视频中的动作和物体运动符合物理定律,避免扭曲变形。多场景连续性:在多个场景中保持目标主体的外观一致性,实现场景间的流畅切换。TeleAI 视频生成大模型的技术原理
VAST技术:TeleAI视频生成大模型采用了“VAST(Video As Storyboard from Text)二阶段视频生成技术”。通过文本描述精准勾勒出包含视频构图、主体目标位置及人物姿态等关键信息的“故事板”(Storyboard),进而生成对应的视频内容。外观一致性和动作控制:得益于VAST技术,视频生成大模型能保证单个或多个主体人物在各视频片段中的外观一致性,实现对复杂动作和交互式动作的精确控制,让角色和目标物体的运动符合物理规律。全栈大模型能力:通过语义、语音、文生图、文生视频等全栈大模型能力,TeleAI视频生成大模型打通了短剧及影视制作的各个环节,覆盖文字脚本撰写、分镜脚本绘制、视频拍摄及剪辑、配音及音效合成等全流程,实现降本增效。二阶段生成框架:TeleAI的视频模型通过两阶段生成框架——先画分镜,再生成视频,显著提升了短剧创作过程的可控性。第一阶段将文字描述转换成一系列分镜头,第二阶段根据这些分镜头生成视频画面,确保每个出招防守都准确到位,武打场面既符合物理规律,又富有观赏性。
 相关资讯
相关资讯 2023-04-14
2023-04-14

 下载
下载
















