clone-voice是什么
Clone-voice是开源的声音克隆工具,基于深度学习技术分析和模拟人类声音,实现声音的高质量克隆。工具支持包括中文、英文、日语、韩语等在内的16种语言,能将文本转换为语音或将一种声音风格转换为另一种。界面友好,操作简单,不需要高性能的硬件支持,适合个人和专业领域使用。Clone-voice的应用场景广泛,包括娱乐、教育、媒体广告和语音交互等,为数字内容创作和个性化声音资源提供新的可能性。

来源:爱论文 时间:2025-01-28 16:54:58
Clone-voice是开源的声音克隆工具,基于深度学习技术分析和模拟人类声音,实现声音的高质量克隆。工具支持包括中文、英文、日语、韩语等在内的16种语言,能将文本转换为语音或将一种声音风格转换为另一种。界面友好,操作简单,不需要高性能的硬件支持,适合个人和专业领域使用。Clone-voice的应用场景广泛,包括娱乐、教育、媒体广告和语音交互等,为数字内容创作和个性化声音资源提供新的可能性。
 相关资讯
更多+
相关资讯
更多+
Clone-voice是开源的声音克隆工具,基于深度学习技术分析和模拟人类声音,实现声音的高质量克隆。工具支持包括中文、英文、日语、韩语等在内的16种语言,能将文本转换为语音或将一种声音风格转换为另一种。用户界面友好,操作简单,不需要高性能的硬件支持,适合个人和专业领域使用。
AI教程资讯
 2023-04-14
2023-04-14

SNOOPI是创新的文本到图像生成框架,基于增强单步扩散模型的指导提升模型性能和控制力。SNOOPI包括PG-SB(适当指导 - SwiftBrush)和NASA(负向远离转向注意力)两种技术。PG-SB用随机尺度的无分类器引导方法,增强训练稳定性;NASA用交叉注意力机制整合负面提示,有效抑制生成图像中的不期望元素。
AI教程资讯
2023-04-14

MEMO(Memory-Guided EMOtionaware diffusion)是Skywork AI、南洋理工大学和新加坡国立大学推出的音频驱动肖像动画框架,用在生成具有身份一致性和表现力的说话视频。MEMO围绕两个核心模块构建:记忆引导的时间模块和情感感知音频模块。
AI教程资讯
2023-04-14
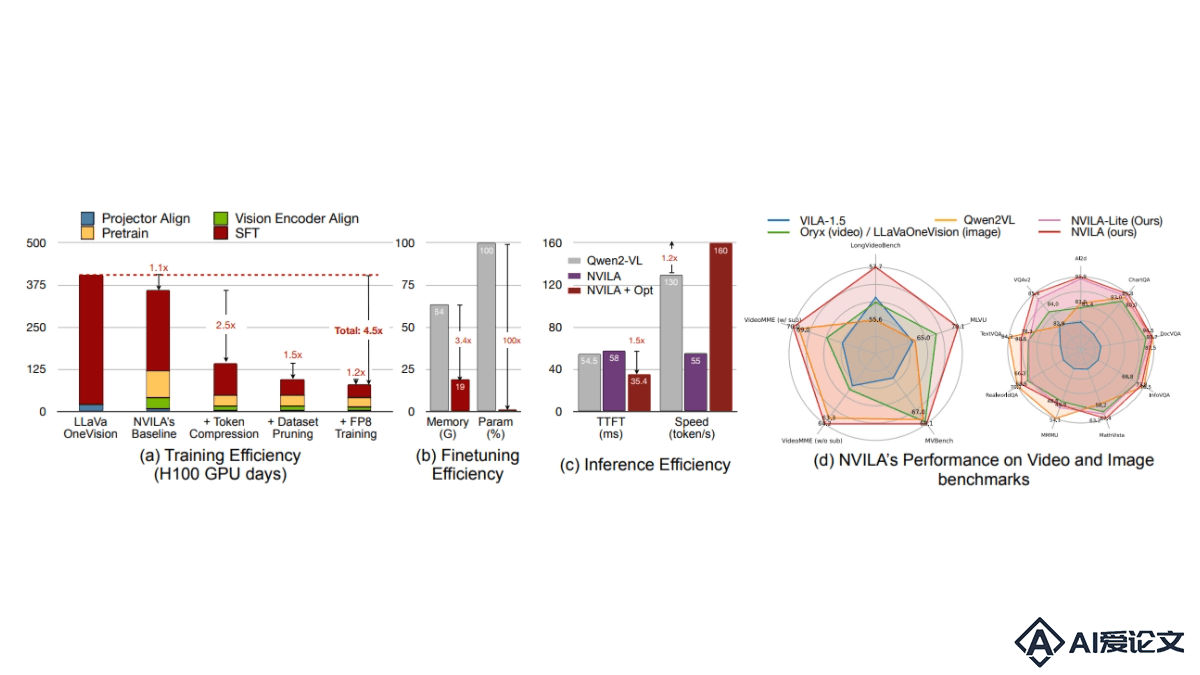
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















