NVILA是什么
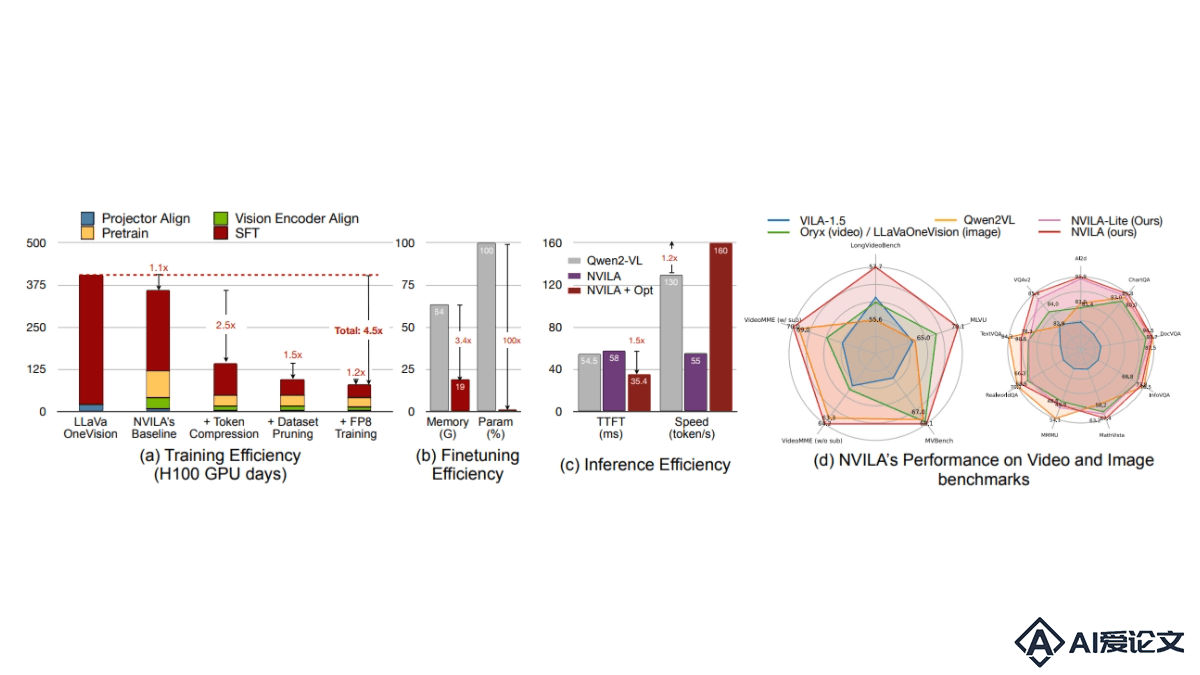
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等新功能,拓宽其在多个领域的应用潜力。
来源:爱论文 时间:2025-01-27 14:47:34
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。NVILA引入时间定位、机器人导航和医学成像等新功能,拓宽其在多个领域的应用潜力。
 相关资讯
更多+
相关资讯
更多+
NVILA是NVIDIA推出的系列视觉语言模型,能平衡效率和准确性。模型用“先扩展后压缩”策略,有效处理高分辨率图像和长视频。NVILA在训练和微调阶段进行系统优化,减少资源消耗,在多项图像和视频基准测试中达到或超越当前领先模型的准确性,包括Qwen2VL、InternVL和Pixtral在内的多种顶尖开源模型,及GPT-4o和Gemini等专有模型。
AI教程资讯
 2023-04-14
2023-04-14
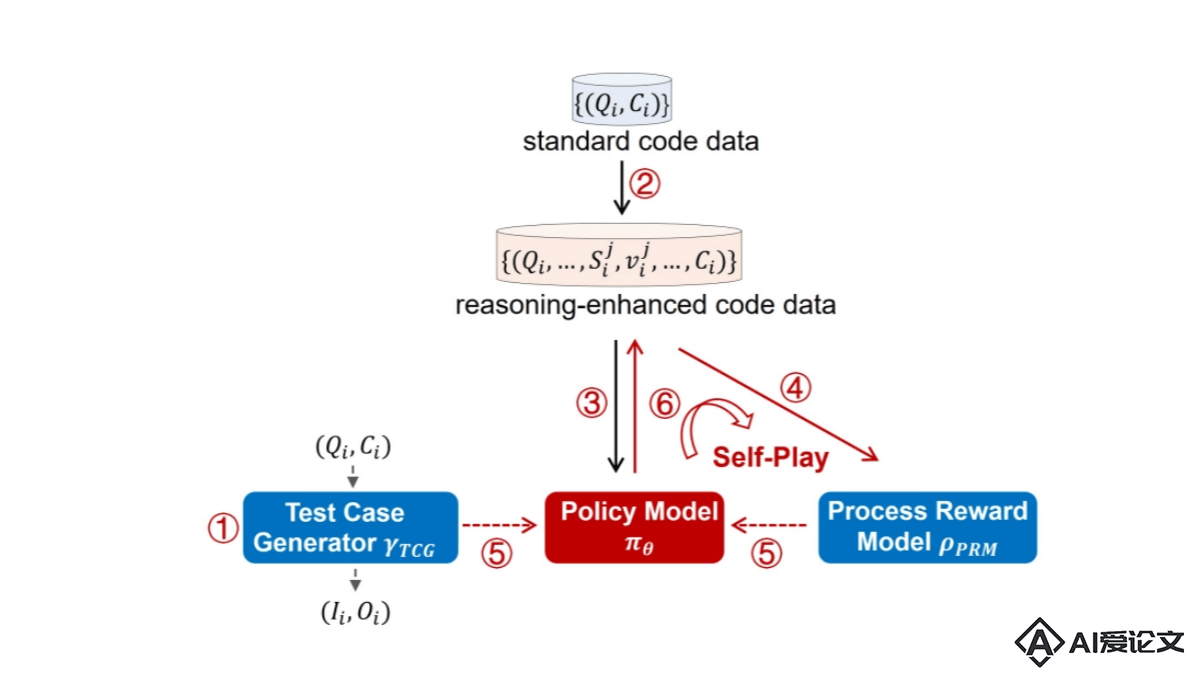
O1-CODER是北京交通大学研究团队推出的开源项目,旨在复制OpenAI的O1模型,专注于编码任务。O1-CODER结合强化学习(RL)和蒙特卡洛树搜索(MCTS)技术,提升模型的System-2思维能力,更谨慎、逻辑和逐步的问题解决过程。
AI教程资讯
2023-04-14
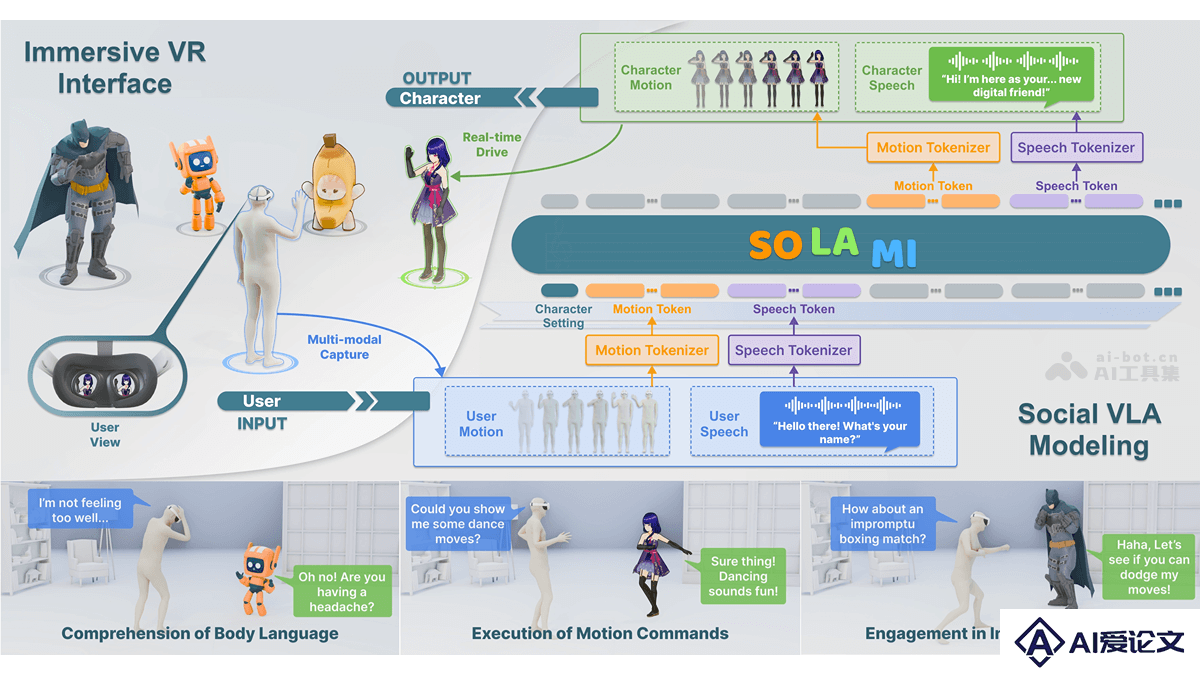
SOLAMI是创新的VR端3D角色扮演AI系统,是南洋理工大学研究团队推出的。支持用户用语音和肢体语言与虚拟角色进行沉浸式互动,基于社交视觉-语言-行为模型,提供超越传统文本和语音交互的自然交流体验。
AI教程资讯
2023-04-14
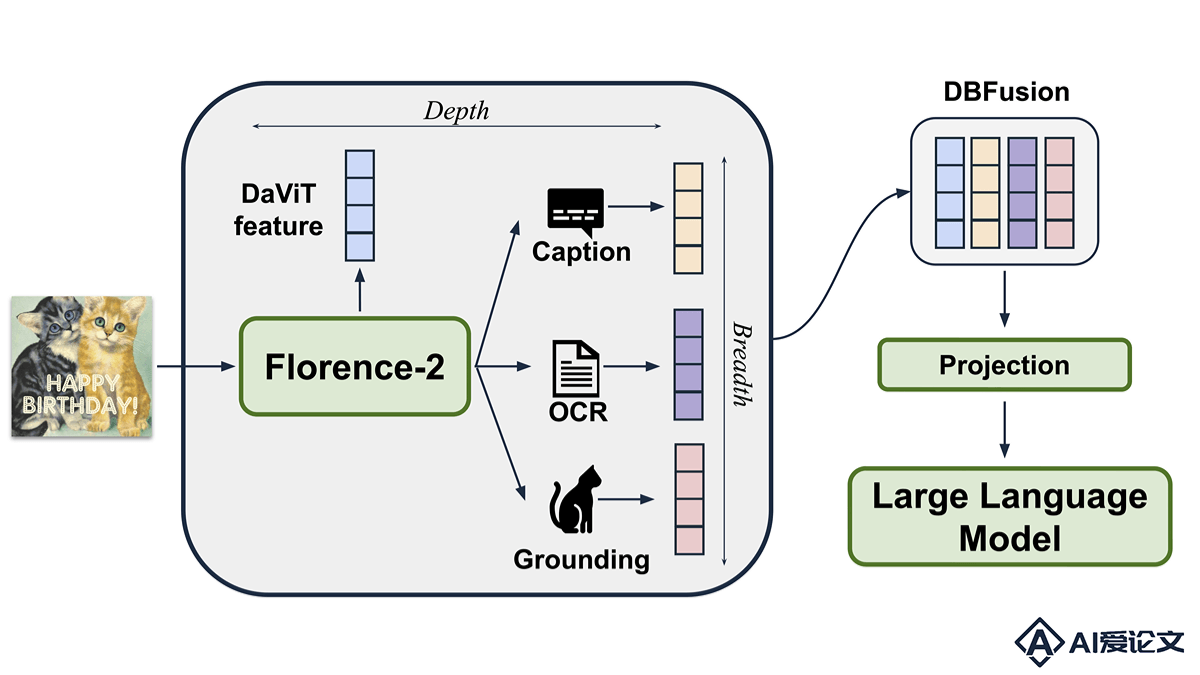
Florence-VL是创新的多模态大型语言模型(MLLMs),是马里兰大学和微软研究院共同推出的。Florence-VL用生成式视觉基础模型Florence-2丰富视觉表示,能捕捉图像的不同层次和方面的视觉特征,适应多样的下游任务。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















