VISION XL是什么
VISION XL是高效的视频修复和超分辨率工具,基于潜在扩散模型技术,专注于解决高清视频的逆问题。工具能修复视频缺失部分、去除模糊,提升视频清晰度,最高可达四倍超分辨率。VISION XL基于减少对额外预训练模块的依赖,优化处理效率,仅需13GB显存能在2.5分钟内处理25帧视频,非常适合需要快速处理视频的应用场景。

来源:爱论文 时间:2025-01-27 10:36:42
VISION XL是高效的视频修复和超分辨率工具,基于潜在扩散模型技术,专注于解决高清视频的逆问题。工具能修复视频缺失部分、去除模糊,提升视频清晰度,最高可达四倍超分辨率。VISION XL基于减少对额外预训练模块的依赖,优化处理效率,仅需13GB显存能在2.5分钟内处理25帧视频,非常适合需要快速处理视频的应用场景。
 相关资讯
更多+
相关资讯
更多+
VISION XL是高效的视频修复和超分辨率工具,基于潜在扩散模型技术,专注于解决高清视频的逆问题。工具能修复视频缺失部分、去除模糊,显著提升视频清晰度,最高可达四倍超分辨率。
AI教程资讯
 2023-04-14
2023-04-14

SPDL(Scalable and Performant Data Loading)是 Meta AI 推出的开源数据加载工具,能提高 AI 模型训练效率。基于多线程技术,实现高吞吐量数据加载,减少计算资源消耗。与传统基于进程的方法相比,SPDL 提升2-3倍的吞吐量,与 Free-Threaded Python 兼容,能在禁用 GIL 的环境中进一步提升30%的性能。
AI教程资讯
2023-04-14
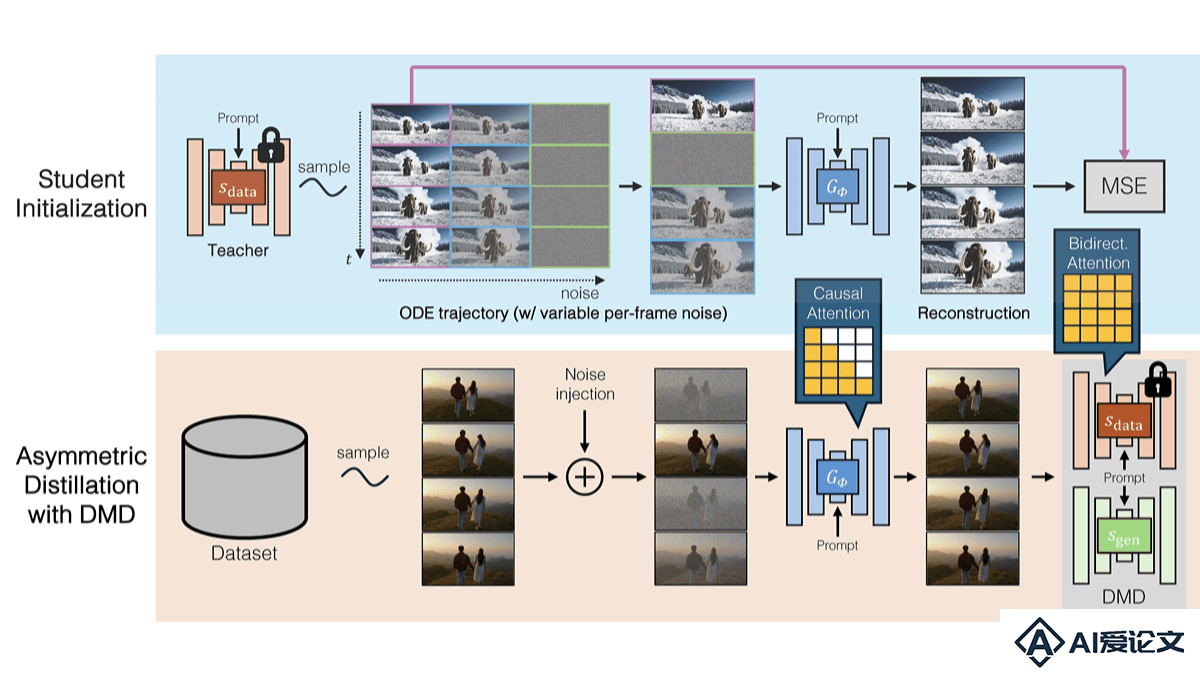
CausVid是Adobe和MIT共同推出的自回归实时视频生成技术,能实现视频的即时播放。基于蒸馏预训练的双向扩散模型构建出自回归生成模型,减少视频生成的延迟,首帧延迟仅1 3秒,生成速度达到9 4帧 秒。CausVid突破传统视频生成模型的限制,支持多种应用。
AI教程资讯
2023-04-14

ClotheDreamer是上海大学、上海交通大学、复旦大学和腾讯优图实验室共同推出的3D服装生成技术,能根据文本描述生成高保真、可穿戴的3D服装资产。ClotheDreamer用3D高斯为基础,基于Disentangled Clothe Gaussian Splatting (DCGS) 实现服装与人体分离优化,用双向Score Distillation Sampling (SDS) 提升服装渲染质量。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















