TEN Agent是什么
TEN Agent是集成OpenAI Realtime API和RTC技术的开源实时多模态AI代理框架。TEN Agent能实现语音、文本、图像的多模态交互,具备天气查询、网络搜索、视觉识别、RAG能力,支持高性能的实时通信,具备低延迟的音视频交互能力。TEN Agent支持多语言和跨平台操作,支持开发者基于模块化设计轻松扩展功能,如集成视觉识别和RAG能力。TEN Agent提供实时代理状态管理,让AI代理动态响应用户交互,适用于智能客服、实时语音助手等多种场景。

来源:爱论文 时间:2025-01-26 13:12:35
TEN Agent是集成OpenAI Realtime API和RTC技术的开源实时多模态AI代理框架。TEN Agent能实现语音、文本、图像的多模态交互,具备天气查询、网络搜索、视觉识别、RAG能力,支持高性能的实时通信,具备低延迟的音视频交互能力。TEN Agent支持多语言和跨平台操作,支持开发者基于模块化设计轻松扩展功能,如集成视觉识别和RAG能力。TEN Agent提供实时代理状态管理,让AI代理动态响应用户交互,适用于智能客服、实时语音助手等多种场景。
 相关资讯
更多+
相关资讯
更多+
TEN Agent是集成OpenAI Realtime API和RTC技术的开源实时多模态AI代理框架。TEN Agent能实现语音、文本、图像的多模态交互,支持高性能的实时通信,具备低延迟的音视频交互能力。TEN Agent支持多语言和跨平台操作,支持开发者基于模块化设计轻松扩展功能,如集成视觉识别和RAG能力。
AI教程资讯
 2023-04-14
2023-04-14
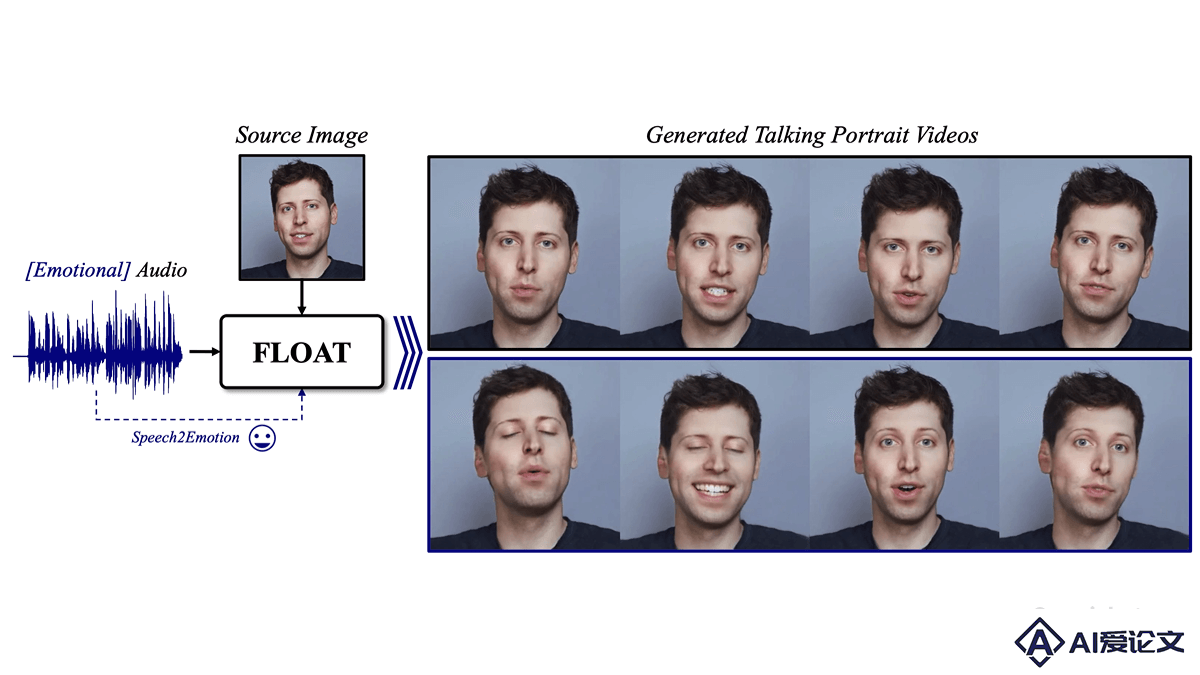
FLOAT是DeepBrain AI 和韩国先进科技研究院推出的音频驱动说话人头像生成模型,基于流匹配生成模型,学习运动潜在空间实现高效的时间一致性运动设计。模型基于Transformer架构的向量场预测器,实现帧间时间一致性,支持语音驱动的情感增强,让生成的说话动作更自然、富有表现力。
AI教程资讯
2023-04-14

SynCamMaster是浙江大学、快手科技、清华大学和香港中文大学的研究人员共同合作推出的全球首个多视角视频生成模型,能结合6自由度相机姿势,从任意视点生成开放世界视频。SynCamMaster增强了预训练的文本到视频模型,确保不同视点的内容一致性,支持多摄像机视频生成。
AI教程资讯
2023-04-14

STIV(Scalable Text and Image Conditioned Video Generation)是苹果公司推出的视频生成大模型。STIV拥有8 7亿参数,能处理文本到视频(T2V)和文本图像到视频(TI2V)任务,基于联合图像-文本分类器自由引导(JIT-CFG)提升视频生成质量。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















