SynCamMaster是什么
SynCamMaster是浙江大学、快手科技、清华大学和香港中文大学的研究人员共同合作推出的全球首个多视角视频生成模型,能结合6自由度相机姿势,从任意视点生成开放世界视频。SynCamMaster增强了预训练的文本到视频模型,确保不同视点的内容一致性,支持多摄像机视频生成。基于插件式模块和多视图同步模块,实现视点间的动态同步,保持4D一致性。SynCamMaster能扩展到新视角视频合成,重新渲染输入视频从新视角观看。

来源:爱论文 时间:2025-01-26 12:25:15
SynCamMaster是浙江大学、快手科技、清华大学和香港中文大学的研究人员共同合作推出的全球首个多视角视频生成模型,能结合6自由度相机姿势,从任意视点生成开放世界视频。SynCamMaster增强了预训练的文本到视频模型,确保不同视点的内容一致性,支持多摄像机视频生成。基于插件式模块和多视图同步模块,实现视点间的动态同步,保持4D一致性。SynCamMaster能扩展到新视角视频合成,重新渲染输入视频从新视角观看。
 相关资讯
更多+
相关资讯
更多+
SynCamMaster是浙江大学、快手科技、清华大学和香港中文大学的研究人员共同合作推出的全球首个多视角视频生成模型,能结合6自由度相机姿势,从任意视点生成开放世界视频。SynCamMaster增强了预训练的文本到视频模型,确保不同视点的内容一致性,支持多摄像机视频生成。
AI教程资讯
 2023-04-14
2023-04-14

STIV(Scalable Text and Image Conditioned Video Generation)是苹果公司推出的视频生成大模型。STIV拥有8 7亿参数,能处理文本到视频(T2V)和文本图像到视频(TI2V)任务,基于联合图像-文本分类器自由引导(JIT-CFG)提升视频生成质量。
AI教程资讯
2023-04-14
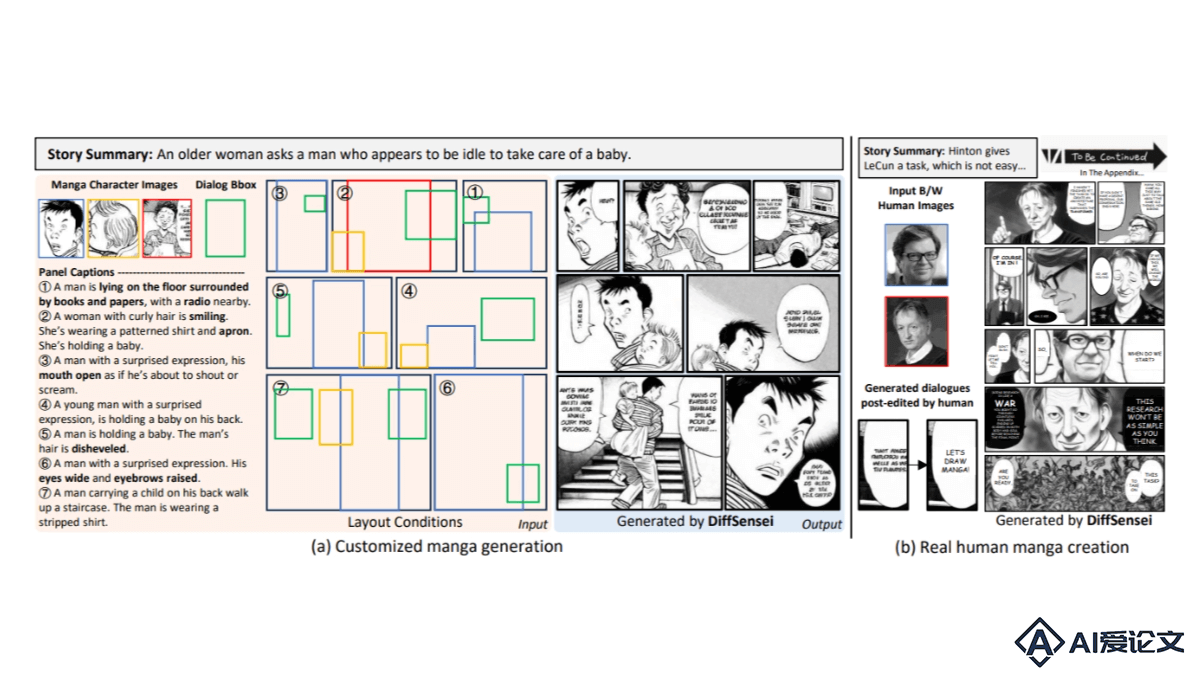
DiffSensei是北京大学、上海AI实验室及南洋理工大学的研究人员共同推出的漫画生成框架,能生成可控的黑白漫画面板。DiffSensei整合基于扩散的图像生成器和多模态大型语言模型(MLLM),实现对漫画中多角色外观和互动的精确控制。
AI教程资讯
2023-04-14
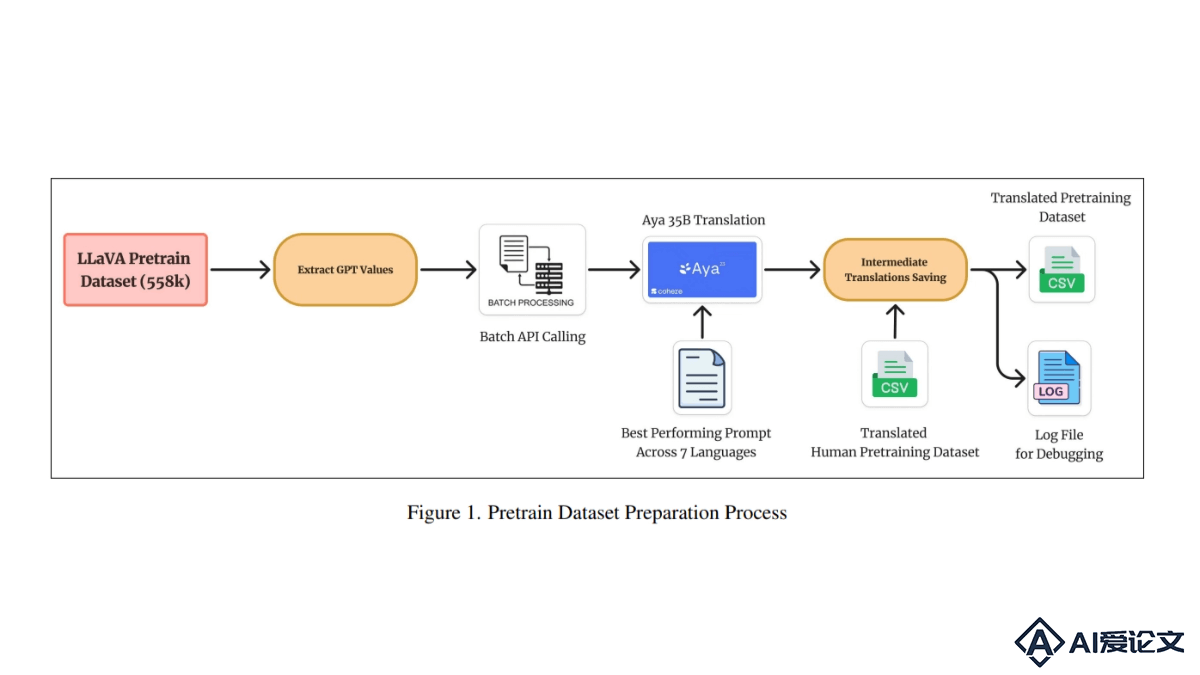
Maya是开源的多语言多模态模型,基于指令微调扩展模型在多种语言和文化背景下的能力。Maya基于LLaVA框架,包含新创建的包含八种语言的预训练数据集,提高视觉-语言任务中的文化和语言理解。Maya基于毒性分析和数据集过滤,确保训练数据的安全性和质量。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















