Freestyler是什么
Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。Freestyler基于语言模型生成语义标记,再基于条件流匹配模型产生频谱图,最后用神经声码器转换成音频。Freestyler推出RapBank数据集,支持训练和模型开发,能实现零样本的音色控制,让用户生成具有特定音色的说唱声乐。
来源:爱论文 时间:2025-01-23 17:51:48
Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。Freestyler基于语言模型生成语义标记,再基于条件流匹配模型产生频谱图,最后用神经声码器转换成音频。Freestyler推出RapBank数据集,支持训练和模型开发,能实现零样本的音色控制,让用户生成具有特定音色的说唱声乐。
 相关资讯
更多+
相关资讯
更多+
Freestyler是西北工业大学计算机科学学院音频、语音与语言处理小组(ASLP@NPU)、微软及香港中文大学深圳研究院大数据研究所共同推出的说唱乐生成模型,能直接根据歌词和伴奏创作出说唱音乐。
AI教程资讯
 2023-04-14
2023-04-14

SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024x1024像素)的图像,且只需1 4秒。模型用379M参数实现这一性能,显著减少模型大小和计算需求,同时在GenEval指标上达到0 66的高分,超越许多参数量更大的SDXL和IF-XL模型。
AI教程资讯
2023-04-14
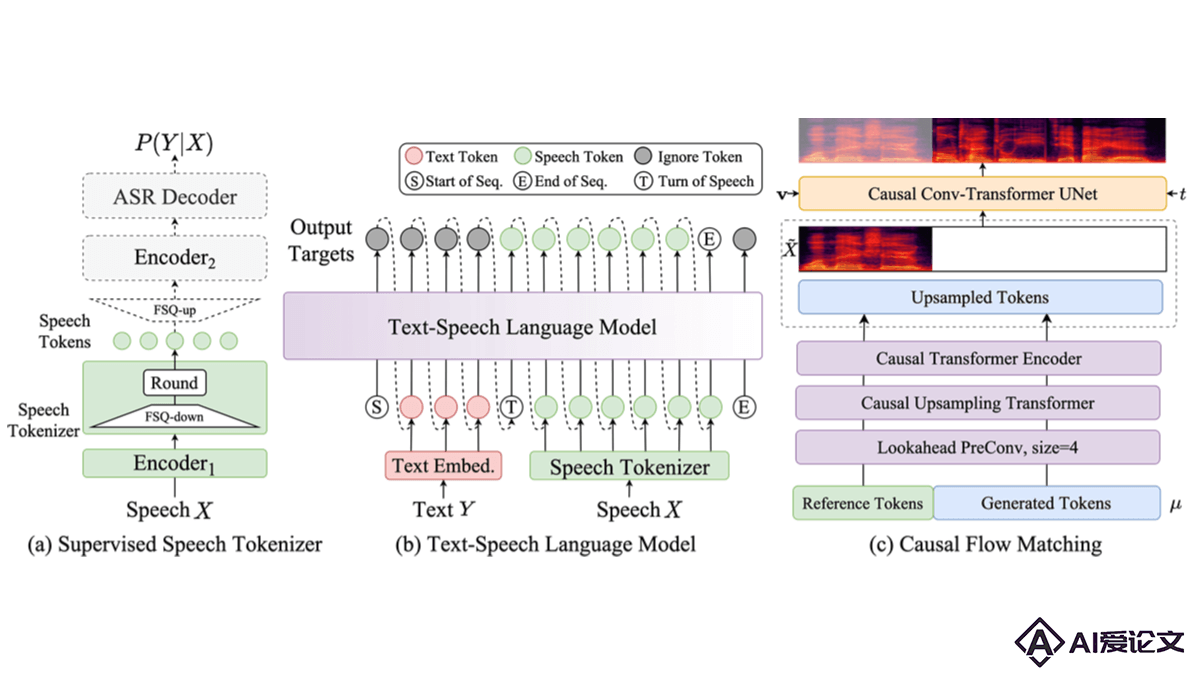
CosyVoice 2 0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升。
AI教程资讯
2023-04-14

Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















