SnapGen是什么
SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024×1024像素)的图像,且只需1.4秒。模型用379M参数实现这一性能,显著减少模型大小和计算需求,同时在GenEval指标上达到0.66的高分,超越许多参数量更大的SDXL和IF-XL模型。SnapGen基于优化网络架构、跨架构知识蒸馏和对抗性步骤蒸馏等技术,实现在移动设备上的高效图像生成。

来源:爱论文 时间:2025-01-23 17:22:10
SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024×1024像素)的图像,且只需1.4秒。模型用379M参数实现这一性能,显著减少模型大小和计算需求,同时在GenEval指标上达到0.66的高分,超越许多参数量更大的SDXL和IF-XL模型。SnapGen基于优化网络架构、跨架构知识蒸馏和对抗性步骤蒸馏等技术,实现在移动设备上的高效图像生成。
 相关资讯
更多+
相关资讯
更多+
SnapGen是Snap Inc、香港科技大学、墨尔本大学等机构联合推出的文本到图像(T2I)扩散模型,能在移动设备上快速生成高分辨率(1024x1024像素)的图像,且只需1 4秒。模型用379M参数实现这一性能,显著减少模型大小和计算需求,同时在GenEval指标上达到0 66的高分,超越许多参数量更大的SDXL和IF-XL模型。
AI教程资讯
 2023-04-14
2023-04-14
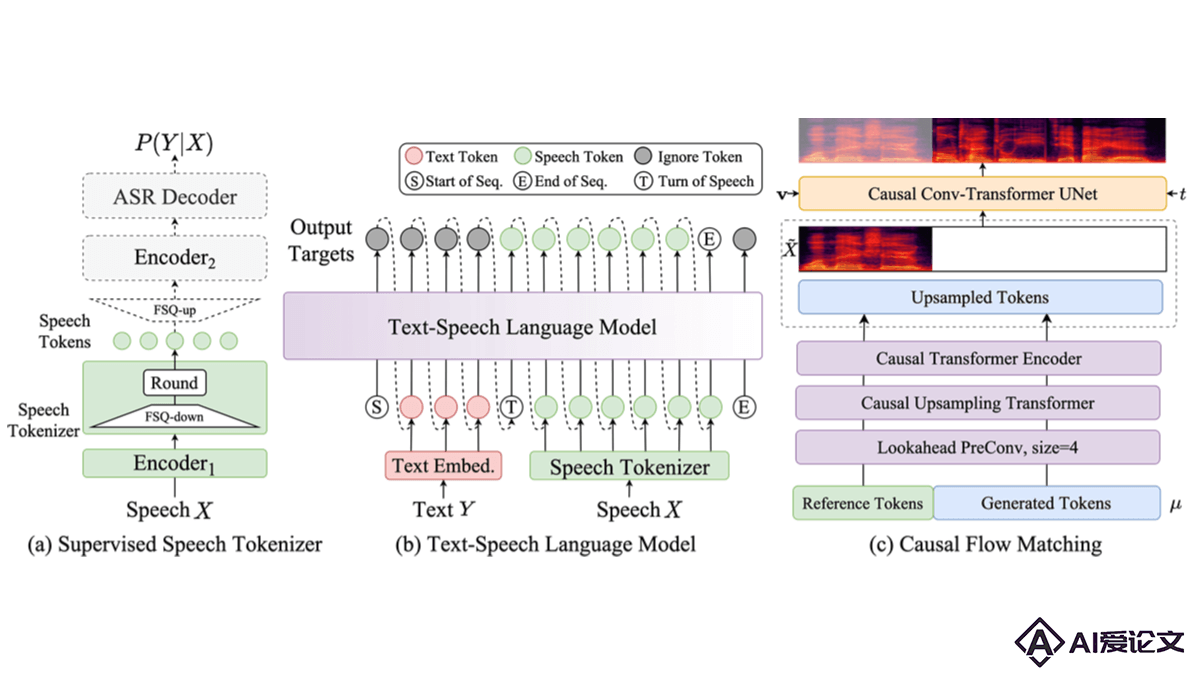
CosyVoice 2 0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升。
AI教程资讯
2023-04-14

Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。
AI教程资讯
2023-04-14
Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2 在 Meta 的 MovieGenBench 基准测试中表现优异,优于其他视频生成模型(如Meta、Minimax)。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















