CosyVoice 2.0是什么
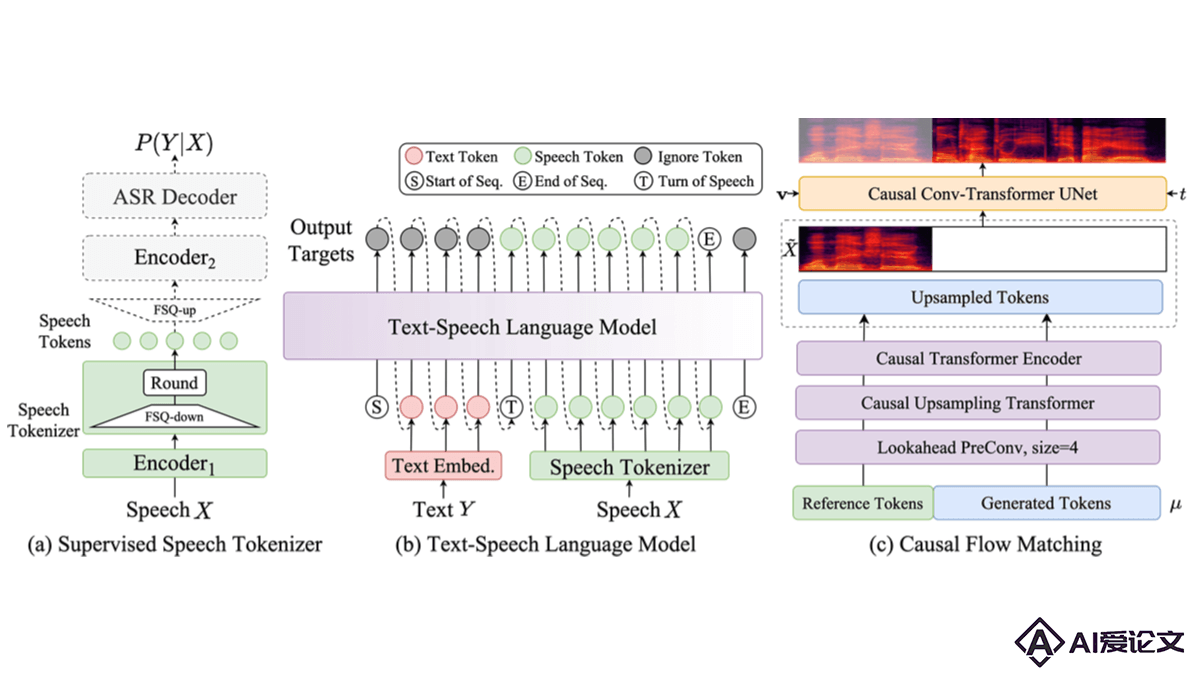
CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升,MOS评测分从5.4提升到5.53,支持流式推理,大幅降低首包合成延迟至150ms,适合实时语音合成场景。
来源:爱论文 时间:2025-01-23 17:01:03
CosyVoice 2.0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升,MOS评测分从5.4提升到5.53,支持流式推理,大幅降低首包合成延迟至150ms,适合实时语音合成场景。
 相关资讯
更多+
相关资讯
更多+
CosyVoice 2 0 是阿里巴巴通义实验室推出的CosyVoice语音生成大模型升级版,模型用有限标量量化技术提高码本利用率,简化文本-语音语言模型架构,推出块感知因果流匹配模型支持多样的合成场景。CosyVoice 2 在发音准确性、音色一致性、韵律和音质上都有显著提升。
AI教程资讯
 2023-04-14
2023-04-14

Megrez-3B-Omni是无问芯穹推出的全球首个端侧全模态理解开源模型,能处理图像、音频和文本三种模态数据。Megrez-3B-Omni在多个主流测试集上展现出超越34B模型的性能,推理速度领先同精度模型达300%。
AI教程资讯
2023-04-14
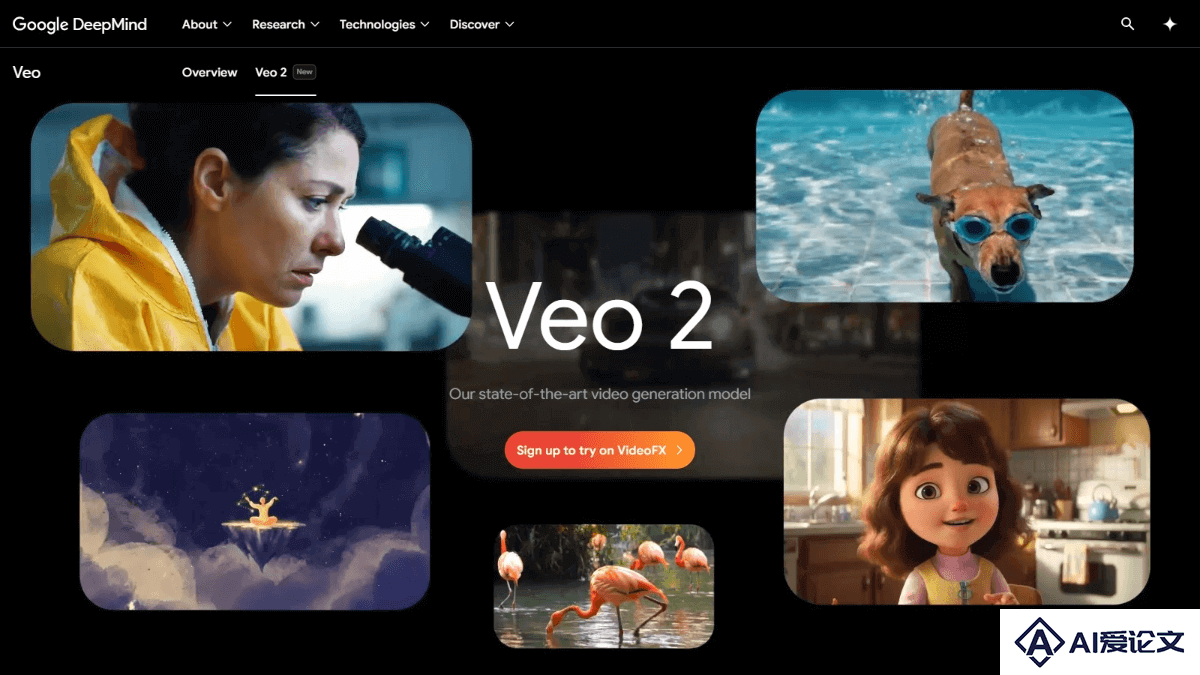
Veo 2 是 Google DeepMind 推出的 AI 视频生成模型,能根据文本或图像提示生成高质量视频内容。Veo 2支持高达 4K 分辨率的视频制作,理解镜头控制指令,能模拟现实世界的物理现象及人类表情。Veo 2 在 Meta 的 MovieGenBench 基准测试中表现优异,优于其他视频生成模型(如Meta、Minimax)。
AI教程资讯
2023-04-14
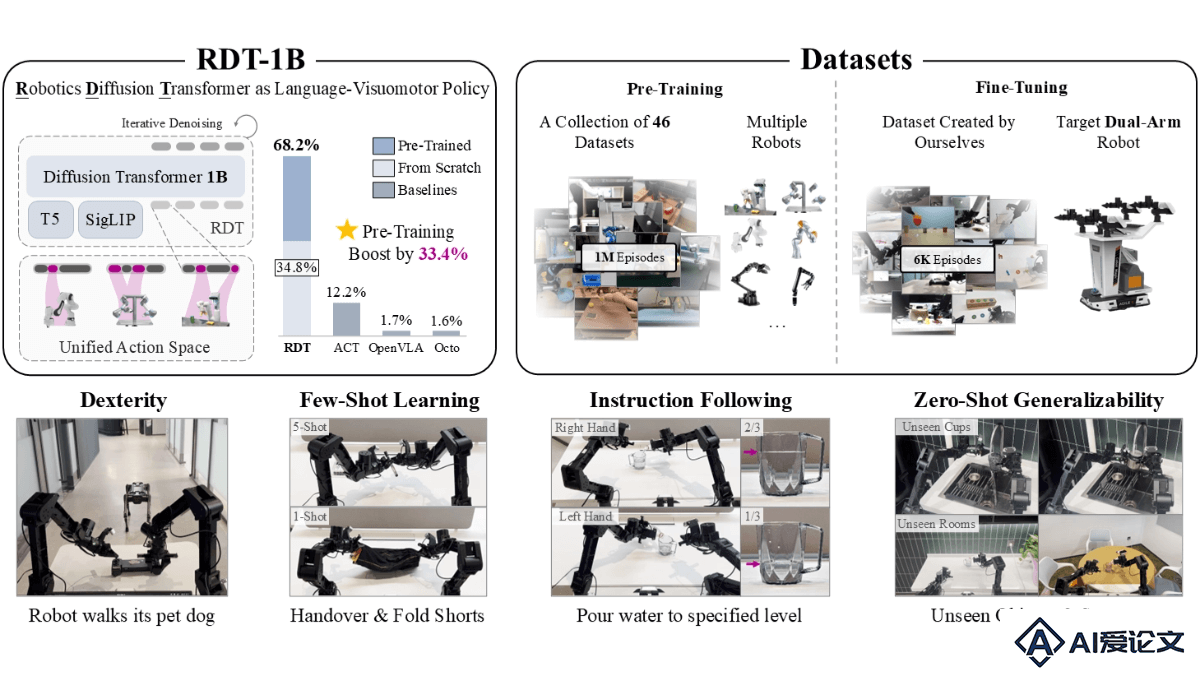
RDT(Robotics Diffusion Transformer)是清华大学AI研究院TSAIL团队推出的全球最大的双臂机器人操作任务扩散基础模型。RDT具备十亿参数量,能在无需人类操控的情况下,自主完成复杂任务,如调酒和遛狗。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















