LatentLM是什么
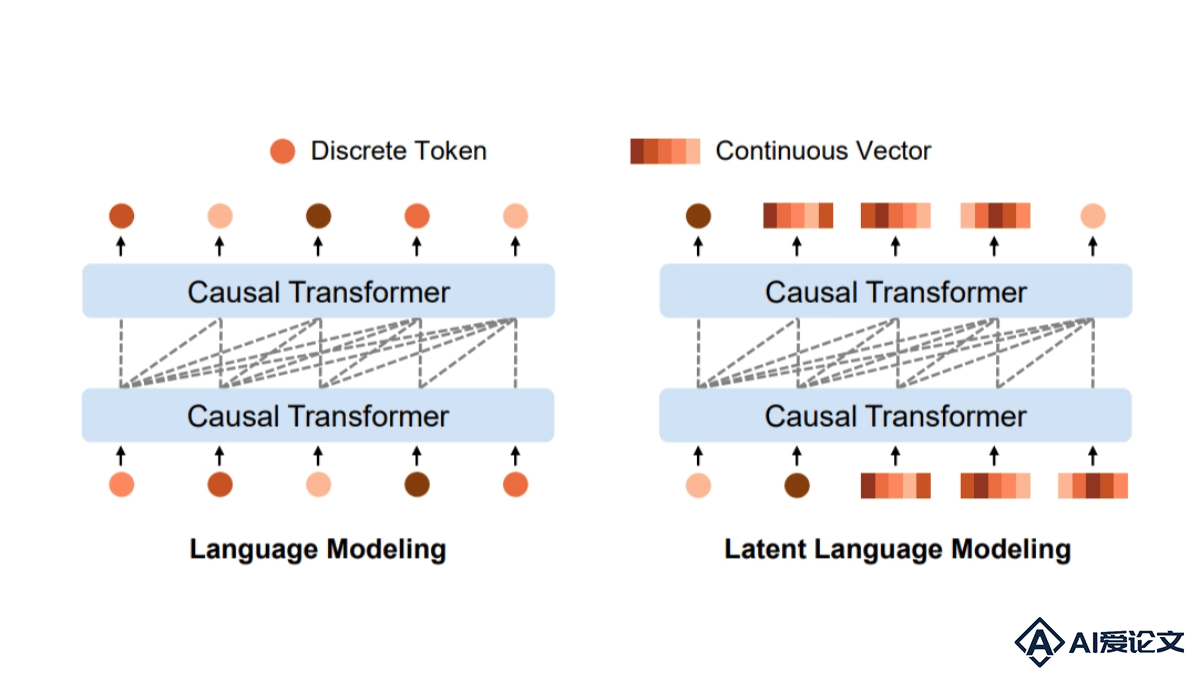
LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。LatentLM基于因果Transformer架构实现不同模态间信息共享,提高模型在多模态任务中的性能和可扩展性。LatentLM推出σ-VAE解决方差崩溃问题,增强自回归建模的鲁棒性,在图像生成、多模态大型语言模型和文本到语音合成等多个领域展现出卓越性能。
来源:爱论文 时间:2025-01-23 12:43:30
LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。LatentLM基于因果Transformer架构实现不同模态间信息共享,提高模型在多模态任务中的性能和可扩展性。LatentLM推出σ-VAE解决方差崩溃问题,增强自回归建模的鲁棒性,在图像生成、多模态大型语言模型和文本到语音合成等多个领域展现出卓越性能。
 相关资讯
更多+
相关资讯
更多+
LatentLM是微软研究院和清华大学共同推出的多模态生成模型,能统一处理离散数据(如文本)和连续数据(如图像、音频)。模型用变分自编码器(VAE)将连续数据编码为潜在向量,引入下一个词扩散技术自回归生成向量。
AI教程资讯
 2023-04-14
2023-04-14
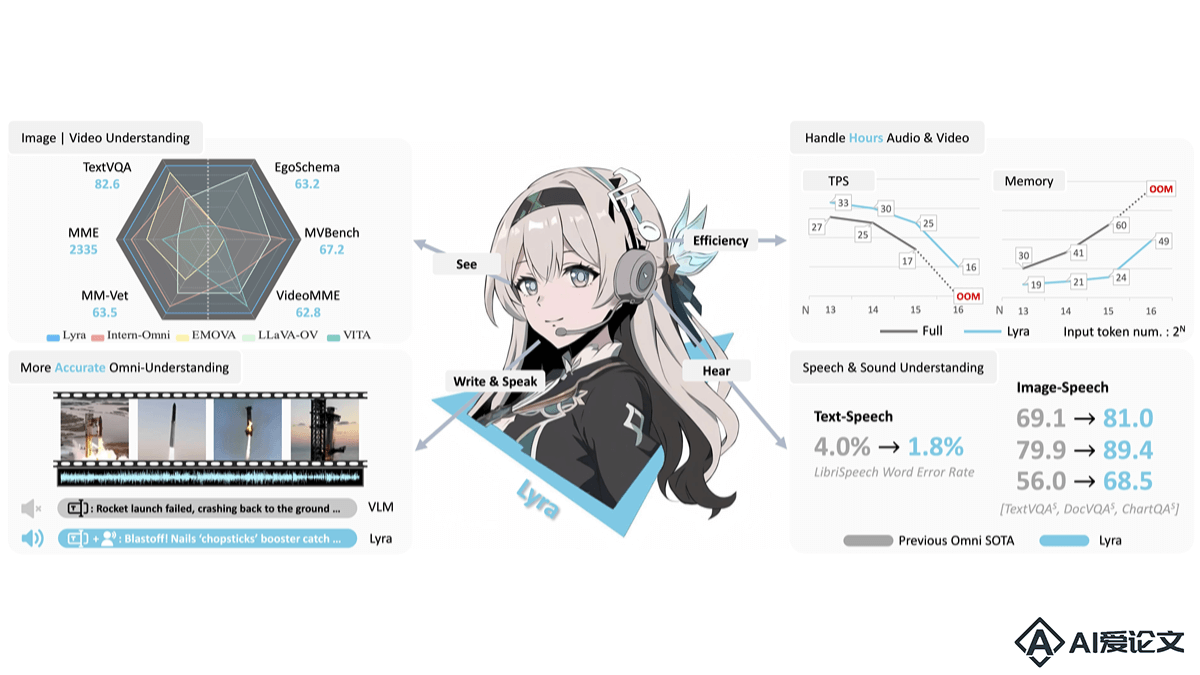
Lyra是香港中文大学、SmartMore和香港科技大学推出的高效多模态大型语言模型(MLLM),专注于提升语音、视觉和语言模态的交互能力。Lyra基于开源大型模型、多模态LoRA模块和潜在的多模态正则化器,减少训练成本和数据需求。
AI教程资讯
2023-04-14
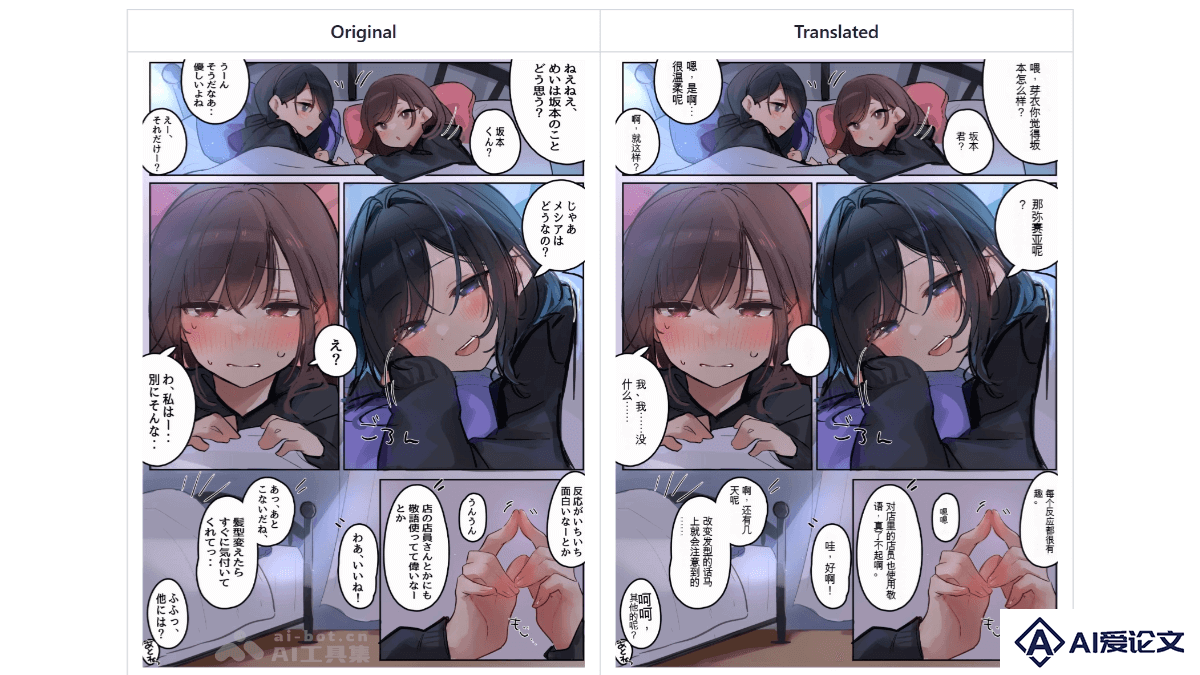
Manga Image Translator是开源的漫画图片文字翻译工具,能一键翻译漫画和图片中的文字。Manga Image Translator基于OCR技术识别文本,结合机器翻译将文字转换成目标语言。工具支持多种语言,能将翻译后的文本无缝嵌入原图,保持漫画风格。
AI教程资讯
2023-04-14

Ivy-VL是AI Safeguard联合卡内基梅隆大学和斯坦福大学推出的轻量级多模态AI模型,专为移动端和边缘设备设计。模型拥有3B参数量,相较于其他多模态大模型,显著降低计算资源需求,能在AI眼镜、智能手机等资源受限设备上高效运行。
AI教程资讯
2023-04-14
热门推荐
更多+
AI工具推荐
更多+


 下载
下载















